

Отчет о совместимости и взаимосвязи модулей оптических приемопередатчиков 800G SR8 и 400G SR4
Средство записи журнала изменений версий V0. Образец теста Cassie Test Цель тестирования Объекты: 800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. Проведя соответствующие тесты, параметры теста соответствуют соответствующим отраслевым стандартам, и тестовые модули можно нормально использовать для коммутатора Nvidia (Mellanox) MQM9790, сетевой карты Nvidia (Mellanox) ConnectX-7 и Nvidia (Mellanox) BlueField-3, прокладывая основа для
Развитие PCIE
In 2012, communication between two boards was achieved over optical fiber using the PCIE protocol. The advantages of doing so are: the reserved optical port allows the two devices to be physically separated, and the reserved optical interface and memory are compatible with and can be accessed by each other.

Раскрытие возможностей графических процессоров NVIDIA H100 в высокопроизводительных серверах
Напряженная ситуация современных вычислений, характеризующаяся увеличением объемов данных и ростом вычислительных требований, стала свидетелем появления графического процессора NVIDIA H100, новатора в области высокопроизводительных серверов. Целью статьи является раскрытие революционных функций, а также новых технологий, лежащих в основе графического процессора NVIDIA H100, который

Раскрытие потенциала кабелей Nvidia MPO для оптоволоконных сетей нового поколения
Кабели Nvidia MPO находятся на переднем крае инноваций в современном постоянно меняющемся мире телекоммуникаций и сетей центров обработки данных. Они обещают значительный прирост оптоволоконных сетей с точки зрения пропускной способности, эффективности и масштабируемости. В данной статье рассматривается оценка различных возможностей. offблагодаря этим передовым кабельным решениям с уважением

Представляем платформу NVIDIA HGX: ускорение искусственного интеллекта и высокопроизводительных вычислений
Платформа HGX от NVIDIA — это революционное достижение в области искусственного интеллекта и высокопроизводительных вычислений. Он был разработан для удовлетворения растущих потребностей в электроэнергии в современных средах с интенсивным использованием данных и объединен с передовой технологией графического процессора; он обеспечивает выдающуюся эффективность обработки, а также гибкость. Целью данного введения является дать читателям предварительное

Революционная Nvidia DGX GH200: будущее суперкомпьютеров с искусственным интеллектом
Nvidia DGX GH200 представляет собой сдвиг парадигмы в области искусственного интеллекта (ИИ) и машинного обучения, открывая новую главу в истории суперкомпьютеров с искусственным интеллектом. Он был разработан как передовая система, способная обрабатывать сложные рабочие нагрузки искусственного интеллекта с непревзойденной вычислительной мощностью, скоростью и энергоэффективностью, отвечающей растущим потребностям. Эта статья
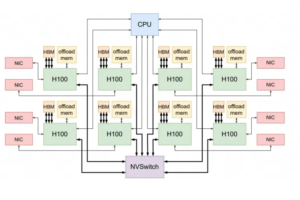
Сети масштабирования графических процессоров на базе Ethernet
Недавний запуск Intel Gaudi-3, который использует RoCE для межсетевого взаимодействия Scale-UP, а также дискуссии Джима Келлера о замене NVLink на Ethernet привлекли внимание к этому инновационному подходу. Примечательно, что компания Tenstorrent, в которой участвует Джим Келлер, умело реализовала межчиповое сетевое соединение с использованием Ethernet. Поэтому уместно обратиться к