
Executive Summary
Driven by the explosive growth of the digital economy and Artificial Intelligence (AI) technologies, global data center network infrastructure is at a critical historical node of migration from 100G to 400G/800G. As Large Language Model (LLM) parameters break through the trillion level and demands for High-Performance Computing (HPC) and distributed storage surge, the network is no longer just a data transmission channel but has evolved into a core bottleneck determining the efficiency of computing clusters. As the cornerstone of next-generation data center networks, the technical substance of 400G Ethernet switches has transcended simple bandwidth upgrades, deeply involving the heterogeneity of underlying chip architectures, the intelligence of congestion control algorithms, and the innovation of optoelectronic interconnection forms.
This report aims to comprehensively and thoroughly analyze the technical ecosystem and competitive landscape of the current 400G switch market. Research shows that between 2024 and 2025, the global Ethernet switch market achieved significant double-digit growth driven strongly by AI Back-end Network demands. Although the shipment growth rate of 800G ports is rapid, 400G remains the primary carrier platform for data centers currently and for the next three years, thanks to its mature supply chain, excellent cost-performance ratio, and extensive legacy compatibility.
In the technical dimension, Ethernet is launching a fierce offensive against traditional InfiniBand through RoCEv2 (RDMA over Converged Ethernet) technology. To resolve the contradiction between Ethernet’s natural “best-effort” characteristic and AI training’s demand for a “lossless network,” chip giants like Broadcom, NVIDIA, and Cisco have launched ASIC chips with deep telemetry and advanced flow control capabilities (e.g., Tomahawk 5, Spectrum-4, Silicon One G100). Meanwhile, system vendors like Huawei, H3C, and Ruijie have built differentiated competitive barriers through software-hardware integrated algorithm innovations such as iLossless, SeerNetwork, and RALB. This report will delve into these technical details and combine them with market data to provide forward-looking strategic references for enterprise users, investors, and technical decision-makers.
Macro Background and Technical Drivers: From Cloud Computing to AI Factories
Fundamental Shift in Traffic Models
Over the past decade, data center network designs were primarily intended to serve cloud computing and Web applications, with traffic characteristics dominated by “North-South” (Client-to-Server) flows, while considering “East-West” (VM-to-VM) traffic brought by virtualization. However, the rise of Generative AI has completely changed this paradigm. In AI training clusters, thousands of GPUs need to perform parameter synchronization (All-Reduce), causing network traffic to exhibit extremely high Burstiness and Many-to-One (Incast) characteristics.
This shift in traffic models makes traditional Oversubscription network architectures no longer applicable. In AI factories, the network must provide high throughput, zero packet loss, and deterministic low latency. Research indicates that a minor increase in network latency (e.g., from 10 microseconds to 100 microseconds) can lead to expensive GPU computing resources sitting idle, significantly increasing the time cost and power consumption of model training. Therefore, the deployment of 400G switches is not a simple port upgrade but an effort to build a high-performance network foundation capable of supporting linear scalability of computing power.
Key Technical Leaps in 400G Ethernet
The implementation of the 400G Ethernet standard (IEEE 802.3bs) introduced several disruptive technologies, achieving a qualitative leap in physical layer transmission efficiency:
Introduction of PAM4 Modulation Technology: To transmit more data within limited bandwidth, the 400G standard abandoned traditional NRZ (Non-Return-to-Zero) coding in favor of PAM4 (Pulse Amplitude Modulation 4-level). PAM4 transmits 2 bits (4 levels) per clock cycle, doubling efficiency compared to NRZ. However, PAM4 has stricter Signal-to-Noise Ratio (SNR) requirements, directly leading to more complex Physical Layer (PHY) designs and reliance on DSP (Digital Signal Processing) chips.
Necessity of FEC (Forward Error Correction): Because PAM4 signals are more susceptible to interference, the Bit Error Rate (BER) rises significantly. Therefore, 400G links must mandatorily enable FEC functions (such as RS-FEC 544,514). While FEC ensures transmission reliability, it introduces extra processing latency (typically in the 100ns-250ns range), which is a factor to weigh for AI networks pursuing ultra-low latency.
Evolution of Optical Module Forms: QSFP-DD (Double Density) and OSFP (Octal Small Form-factor Pluggable) have become the mainstream packaging standards for the 400G era. QSFP-DD dominates general data centers due to backward compatibility with QSFP28; OSFP is favored in high-performance computing and future 800G evolution due to better heat dissipation capabilities (supporting up to 15W-20W or higher power consumption).
Economic Analysis of Energy Efficiency and Density
In hyperscale data centers, Power Efficiency is a core consideration. 400G switches demonstrate significant economic advantages over 100G architectures. According to industry data analysis, a 400G network architecture can reduce power consumption per Gbps by approximately 43% (from ~1.2W/Gb to ~0.7W/Gb) and reduce rack space usage by 48% compared to a 100G network of equivalent bandwidth.
Table 2.1: Economic Comparison of Energy Efficiency & Density: 400G vs. 100G Architectures
| Key Metric | 100G Network Architecture (Baseline) | 400G Network Architecture | Improvement/Advantage |
| Port Bandwidth | 100 Gbps | 400 Gbps | 4x Increase |
| Power per Gbps | ~35mW / 1.2W (System Level) | ~20mW / 0.7W (System Level) | ~43% Energy Savings |
| Rack Space (per Tbps) | 2.5 RU | 1.3 RU | 48% Savings |
| Cable Count (Equal BW) | 100% (Baseline) | 25% – 50% | 50%-75% Reduction, Simplified Ops |
| Switch Chip Capacity | 3.2 Tbps – 6.4 Tbps | 12.8 Tbps – 25.6 Tbps | 4x-8x Increase, Flattened Network Layers |
| TCO (3-Year) | Baseline ($X) | $0.65X | 35% Reduction |
This improvement in energy efficiency is primarily due to advancements in switch chip processes (moving from 16nm/12nm to 7nm/5nm) and increases in SerDes rates (from 25G SerDes to 56G/112G SerDes). This allows data centers to support the exponential bandwidth demand growth brought by AI computing without increasing their physical footprint.
Deep Dive into Core Chip (ASIC) Architectures and Technology Schools
The switch chip (ASIC) is the heart that determines the performance ceiling of a 400G switch. The current market presents a tripartite landscape: Broadcom dominates the commercial market with massive shipment volumes and a standardized ecosystem; NVIDIA focuses on end-to-end optimization leveraging its deep HPC background; Cisco attempts to break the boundaries between routing and switching through a unified architecture. Additionally, vendors like Marvell remain competitive in specific niches.
Broadcom Tomahawk Series: The King of Throughput and Ecosystem
Broadcom’s StrataXGS Tomahawk series is the “de facto standard” for the global commercial data center switch market.
Tomahawk 4 (TH4): As the industry’s first widely adopted 25.6 Tbps chip, TH4 uses a 7nm process, with a single chip supporting 64 x 400G ports. Its architecture focuses on extreme throughput and power efficiency, utilizing a Sliced Memory Architecture. While this architecture may face challenges handling extreme uneven traffic (Incast), its maturity and cost advantages make it the top choice for Hyperscalers building Spine-Leaf networks.
Tomahawk 5 (TH5): Adopting a 5nm process, bandwidth doubles to 51.2 Tbps. TH5 is not just a bandwidth upgrade but introduces enhanced features for AI workloads, such as hardware-based Dynamic Load Balancing (DLB) and finer-grained telemetry. A single TH5 chip supports 64 x 800G ports or 128 x 400G ports, greatly simplifying network topology and reducing hops.
Tomahawk Ultra: A new architecture launched for AI Scale-up networks. Although branding continues the Tomahawk line, the kernel has been refactored. Broadcom claims it achieves Link Layer Retransmission (LLR) and Credit-Based Flow Control (CBFC), aiming to replicate InfiniBand’s lossless characteristics on Ethernet with latency reduced to the 250ns level, mainly targeting NVIDIA’s Spectrum-X solution.
NVIDIA Spectrum Platform: End-to-End Architecture Born for AI
NVIDIA’s (formerly Mellanox) Spectrum series switch chips were designed from the start not just to “switch data” but to “accelerate computing”.
Fully Shared Buffer: Unlike Broadcom’s sliced architecture, the Spectrum series (e.g., Spectrum-3 and Spectrum-4) uses a dynamic shared buffer architecture. This means all ports share the same on-chip memory. When a port experiences congestion (e.g., Microburst), it can dynamically utilize the entire chip’s idle cache resources. This design significantly reduces packet loss probability and provides more deterministic performance under the “Many-to-One” traffic patterns common in AI training.
Spectrum-4: Uses TSMC 4N process, providing 51.2 Tbps bandwidth. Beyond high bandwidth, its most notable features are nanosecond-level clock synchronization accuracy (improved by 5-6 orders of magnitude) and “What Just Happened” (WJH) telemetry. WJH captures and streams detailed failure contexts (e.g., specific drop reasons, affected flow characteristics) rather than simple aggregate statistics, which is crucial for troubleshooting complex distributed AI training failures.
Cisco Silicon One: Ambition for a Unified Architecture
Cisco’s Silicon One architecture aims to break the binary opposition in traditional networks between “Routing Chips” (deep buffer, low bandwidth, complex functions) and “Switching Chips” (shallow buffer, high bandwidth, simple functions).
Q100/G100 Architecture: G100 is Cisco’s flagship chip for the Web-scale switching market, based on a 7nm process providing 25.6 Tbps bandwidth. Its core innovation lies in the “Run-to-Completion” processing pipeline and unified on-chip shared cache. Cisco claims G100 is the industry’s first product to achieve fully shared packet buffering on a high-bandwidth switch chip, combined with P4 programmability, making it suitable as both a high-performance ToR switch and a Spine node requiring complex routing functions.
Multi-Role Capability: Silicon One can switch between “Routing Mode” and “Switching Mode” via microcode configuration, allowing customers to cover all scenarios from DCI edge to data center core with a single hardware architecture, greatly simplifying spares management and operational complexity.
Table 3.1: Comparison of Mainstream 400G/800G Switch Chip Architectures
| Feature/Metric | Broadcom Tomahawk 4 | NVIDIA Spectrum-3 | NVIDIA Spectrum-4 | Cisco Silicon One G100 | Broadcom Tomahawk 5 |
| Process | 7nm | 16nm | 4N (TSMC) | 7nm | 5nm |
| Max Capacity | 25.6 Tbps | 12.8 Tbps | 51.2 Tbps | 25.6 Tbps | 51.2 Tbps |
| 400G Density | 64 Ports | 32 Ports | 128 Ports | 64 Ports | 128 Ports |
| Buffer Arch | Distributed/Sliced | Fully Shared | Fully Shared | Fully Shared | Distributed/Sliced |
| AI/HPC Opt. | Basic RoCE | RoCE Opt., WJH | Spectrum-X, Nano Clock | P4 Prog., Adv. Flow Ctrl | Cognitive Routing, DLB |
| Typ. Latency | ~500ns | <400ns | ~500ns | ~600ns | ~500ns |
| Scenarios | Cloud Spine/Leaf | HPC, AI Storage, Finance | Large AI Clusters, Supercomputing | Cloud Routing, Converged Arch | Next-Gen AI Clusters, 800G Backbone |

Network Architecture Transformation in the AI Era: From Best-Effort to Zero Packet Loss
The proliferation of 400G switches is not just a hardware upgrade but a reconstruction of the network protocol stack and topology. The core goal is to achieve InfiniBand-level performance on Ethernet, i.e., a “Lossless Network.”
The Game of RoCEv2 and Congestion Control Algorithms
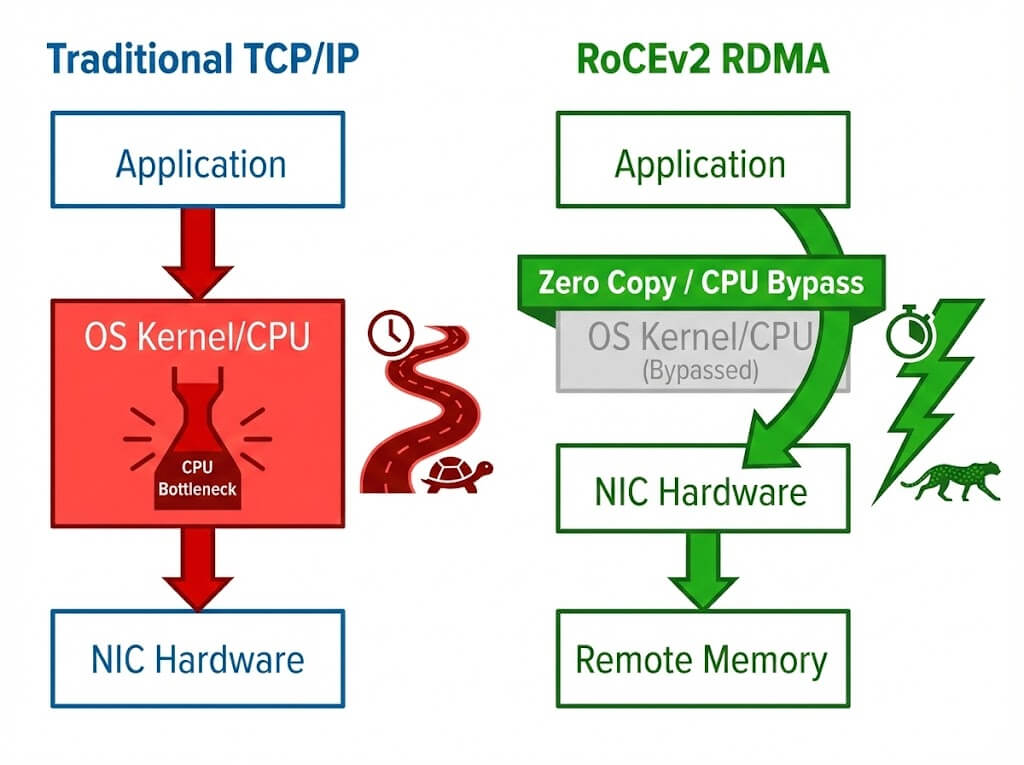
RoCEv2 (RDMA over Converged Ethernet version 2) allows applications to access remote memory directly, bypassing the CPU kernel, thereby achieving ultra-low latency and CPU utilization. However, RoCEv2 relies on lossless transmission in the underlying network. Once packet loss occurs, RDMA’s retransmission mechanism (Go-back-N) causes throughput to drop drastically.
Traditional PFC (Priority-based Flow Control) prevents packet loss through crude “Pause Frames,” but this easily triggers “Head-of-Line Blocking” and “Congestion Spreading,” potentially leading to deadlocks. Therefore, intelligent congestion control algorithms based on ECN (Explicit Congestion Notification) have become the focal point of competition among major vendors.
4.1.1 DCQCN (Data Center Quantized Congestion Notification): Currently the most basic RoCEv2 congestion control algorithm. It combines ECN and PFC; when the switch detects a queue exceeding a threshold, it marks it with ECN. The receiving NIC sends a CNP (Congestion Notification Packet) to the sender upon receipt, and the sender reduces the rate. Limitation: Traditional DCQCN parameters (Kmin, Kmax, Pmax) are statically configured. In AI training scenarios with drastic traffic fluctuations, static thresholds either react too slowly (causing packet loss) or overreact (causing throughput decline).
4.1.2 Huawei iLossless (Intelligent Lossless): Huawei introduced AI chips into its CloudEngine series switches, implementing dynamic ECN threshold adjustment via the iLossless algorithm. Mechanism: The switch learns traffic models in real-time (identifying large/small flows, Incast degree) and dynamically adjusts the ECN trigger waterlines. Huawei claims this algorithm ensures zero packet loss while boosting throughput to 100% and significantly reducing long-tail latency.
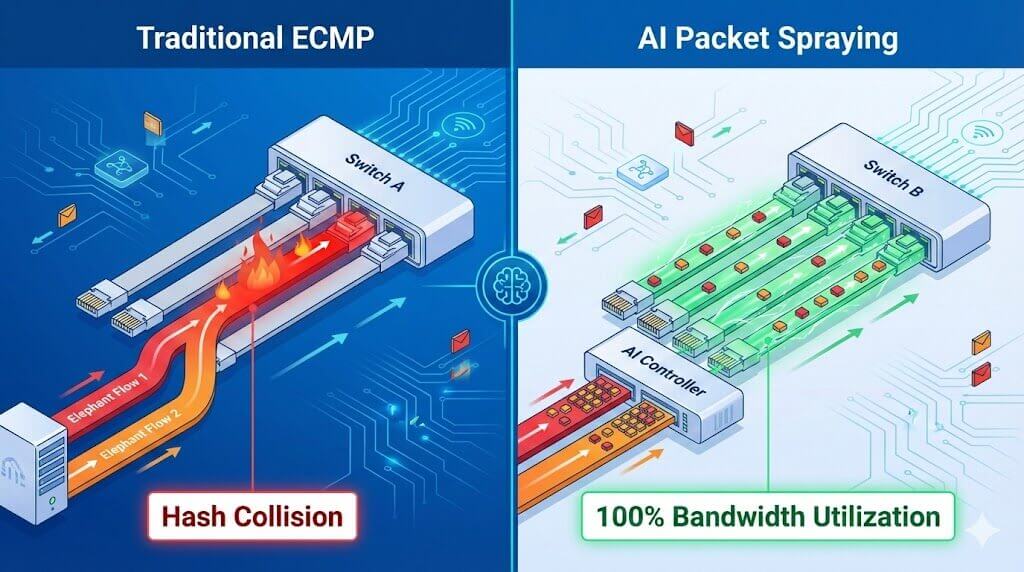
4.1.3 Ruijie RALB (Rail-aware Adaptive Load Balancing) & NFIM: Ruijie developed RALB technology specifically for the Multi-Rail characteristics of AI Clusters. Mechanism: Traditional ECMP (Equal-Cost Multi-Path routing) relies on hash selection, which leads to Hash Collisions (some links congested while others are idle). RALB senses real-time link quality (congestion levels) and performs dynamic load balancing on a Per-packet basis, distributing packets to the most idle links, thereby increasing bandwidth utilization to over 97.6%. Coupled with NFIM (Nanosecond Flow Intelligent Control Module), it can perform predictive scheduling before congestion occurs.
4.1.4 H3C SeerNetwork & DDC Architecture: H3C launched a solution based on DDC (Distributed Disaggregated Chassis) to thoroughly resolve congestion. Mechanism: The DDC architecture physically separates the Line Cards and Fabric of a chassis switch, interconnecting them via optical fibers. During data forwarding, it uses Spray Link technology to slice packets and evenly spray them across all uplinks, physically eliminating hash collisions and achieving theoretically 100% non-blocking performance.
Network Topology: Clos vs. Multi-Rail
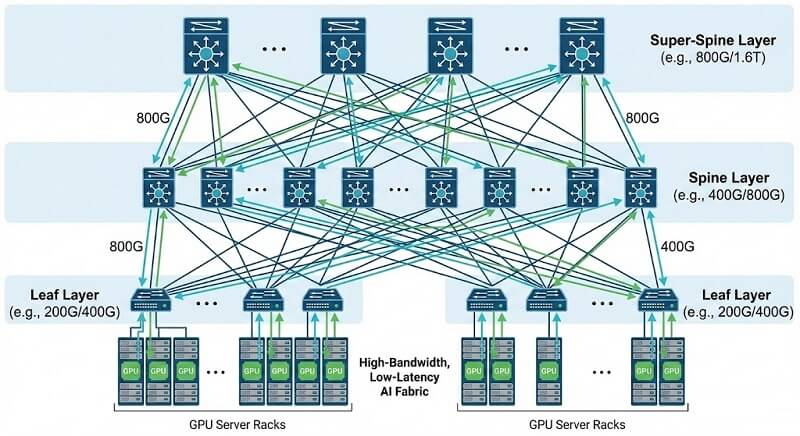
Traditional Clos (Spine-Leaf): Suitable for general computing. Servers connect via a single NIC, and traffic aggregates at the Spine layer.
AI Multi-Rail: Modern AI servers (e.g., NVIDIA HGX H100) are typically equipped with 8 GPUs and 8 NICs. In a Multi-Rail architecture, 8 independent physical network planes (Rails) are established. GPU 0 of every server connects to the Rail 0 network, GPU 1 to Rail 1, and so on. This design allows GPU-to-GPU communication (especially All-Reduce) to be completed entirely within the same Rail, passing through only one level of ToR switch, drastically reducing latency and collision probability. 400G switches typically serve as high-density Leaf nodes in this architecture.
Global Mainstream 400G Switch Vendor Competitiveness Analysis
NVIDIA (Mellanox): The Definer of AI Networks
Core Products: SN4000 (Spectrum-3), SN5600 (Spectrum-4).
Market Position: Absolute dominance in the AI Back-end Network market (combining InfiniBand and Ethernet).
Competitive Advantages:
- Full Stack Ecosystem: The only vendor providing GPU + DPU + NIC + Switch + NOS (Cumulus/SONiC) + Management Software (UFM/NetQ).
- Spectrum-X: Utilizes BlueField-3 DPU as a “Super NIC” combined with Spectrum-4 switches to achieve performance far exceeding standard Ethernet through precise RTT (Round-Trip Time) measurement and direct memory access.
- Telemetry: WJH (What Just Happened) provides chip-level fault visibility, a “godsend” for operating massive AI clusters.
- Disadvantages: Relatively expensive; ecosystem is relatively closed (though based on Ethernet, optimal performance is tied to their full stack).
Arista Networks: The Top Choice for Cloud Giants
Core Products: 7060X5 (TH5 Leaf), 7800R3 (Jericho 2 Spine/DCI).
Market Position: Extremely high share in Front-end networks and Hyperscalers; actively cutting into AI Back-end networks.
Competitive Advantages:
- EOS Operating System: Recognized as the industry’s most stable and open network OS. A single image adapts to all hardware, greatly reducing operational complexity.
- Deep Buffer Architecture: The 7800R series uses Broadcom DNX-based deep buffer chips with GB-level VOQ (Virtual Output Queue) caching, ideal for Data Center Interconnect (DCI) and scenarios with extremely uneven traffic.
- DLB and Etherlink: In the 7700R4 series, Arista introduced distributed Etherlink technology to optimize interconnection efficiency for large-scale clusters.
Cisco Systems: The Giant’s Transformation
Core Products: Nexus 9300-GX2 (Leaf), Nexus 9800 (Modular Spine).
Competitive Advantages:
In-house Silicon One Chip: Freed from sole reliance on Broadcom, achieving architectural differentiation and cost control. G100/G200 chips’ high bandwidth and programmability offer strong flexibility.
Optics-Electronics Synergy: Following the acquisition of Acacia, Cisco has deep accumulation in optical module technology, offering verified “Switch + Optical Module” integrated solutions, which is highly valuable for optical link stability in the 400G/800G era.
Extensive Enterprise Customer Base: Provides a smooth migration path (ACI architecture or NX-OS mode) for clients transitioning from traditional enterprise networks to AI.
Huawei: The Integrator of Technical Strength
Core Products: CloudEngine 16800 Series (Modular), CE8800/9800 (Fixed).
Competitive Advantages:
- iLossless AI Algorithm: Introducing AI computing power into the switch control plane to dynamically optimize flow control parameters is Huawei’s core moat in the lossless Ethernet field.
- Hardware Engineering: The CE16800 uses an orthogonal backplane design, efficient heat dissipation, and advanced power supply technology, supporting extremely high-density 400G/800G port deployment with excellent system energy efficiency.
- Autonomy: Possesses in-house Solar series chips and a complete software/hardware stack, ensuring high supply chain security (for specific markets).
H3C & Ruijie: Cost-Performance and Scenario Customization
H3C: Relying on the SeerNetwork architecture, emphasizes intelligent operations. Its S9825 series switches perform balanced in density and power. H3C is also an active explorer of CPO technology, showcasing low-power silicon photonics co-packaged prototypes.
Ruijie: Deeply rooted with major internet firms (e.g., ByteDance, Alibaba), offering extreme agility. Its RG-S6900 series focuses on “Intelligent Speed” DCN, solving deployment and tuning pain points for large-scale networks via RALB and “One-key RoCE” functions. Ruijie responds quickly in Whitebox and customized ODCC specification products.
Market Data and Economic Analysis
Market Size and Growth Trends
According to the latest tracking data from IDC and Dell’Oro Group, the global Ethernet switch market maintained strong growth in 2024.
- Overall Size: In Q3 2024, data center switch market revenue grew by over 30% year-over-year, with AI-related Back-end networks contributing the vast majority of the increment.
- Port Shipments: 400G ports have become the absolute mainstream, accounting for half of the total data center bandwidth capacity. Although the base for 800G ports is small, the quarterly sequential growth rate is nearing 100%, and deployment in AI clusters is expected to surpass 400G by 2025.
- Vendor Shares: Cisco remains first in overall market revenue but faces share compression. Arista follows closely in the data center sector (especially 100G/400G). NVIDIA shows the most rapid growth, dominating specific AI niche markets with InfiniBand and Spectrum Ethernet solutions. In the Chinese market, Huawei, H3C, and Ruijie hold the top three spots firmly.
Cost and Power Trends
Cost per Bit: With the maturation of the 400G optical module supply chain, the cost of a single 400G port is significantly lower than the sum of four 100G ports, saving on fiber cabling costs and reducing maintenance complexity.
Power Challenges: Despite improved energy efficiency per Gbps for 400G, the total power consumption of a single switch has risen sharply. A 2U switch fully loaded with 64 x 400G ports typically consumes 1500W-2000W (including optical modules). This poses severe challenges for cabinet power supply and heat dissipation, driving the R&D of Liquid Cooled Switches.
Table 6.1: Power Consumption Estimates for Mainstream 400G Switches (Typical Full Load)
| Vendor | Model | Port Config | Typical System Power (Est. with Optics) | Thermal Design |
| H3C | S9825-64D | 64x 400G | ~1850W (Max) / ~613W (Typ. Empty) | Front-Rear Airflow, Hot-swap Fans |
| Ruijie | RG-S6980-64QC | 64x 400G | ~2400W (Max) / ~1760W (Typ) | 4+1 Redundant Fans, Smart Speed |
| NVIDIA | SN5600 | 64x 800G/400G | ~670W (System only, no optics) | High-eff. Airflow, Opt. for AOC/DAC |
| Huawei | CE16800 | Modular (48x 400G/card) | Approx 800W+/card (Config dependent) | Orthogonal Arch, Mixed Liquid Cooling |
Future Outlook: 800G, UEC, and Optoelectronics Integration
Evolution to 800G and 1.6T
With the release of NVIDIA Blackwell GPUs and next-generation AI accelerators, single-card bandwidth demand will leap to 800Gbps or higher.
- The 800G Era: 2025 will be the breakout year for 800G Ethernet. Switches based on Tomahawk 5 and Spectrum-4 will be deployed at scale in the core layer (Spine) of AI clusters.
- 1.6T Outlook: It is expected that by 2026-2027, with the commercialization of next-generation chips like Tomahawk 6 (102.4T), 1.6T interfaces will begin entering hyperscale clusters.
Rise of UEC (Ultra Ethernet Consortium)
To break InfiniBand’s monopoly and solve traditional Ethernet pain points in AI scenarios, giants including AMD, Arista, Broadcom, Cisco, Meta, and Microsoft jointly founded the UEC.
Goal: Define the next-generation “AI-Native” Ethernet transport layer protocol, improving RoCEv2 by introducing Multi-Path Packet Spraying, flexible retransmission mechanisms, and more efficient congestion control. Future 400G/800G switches will universally support UEC standards, thoroughly eliminating the “lossy” risks of Ethernet.
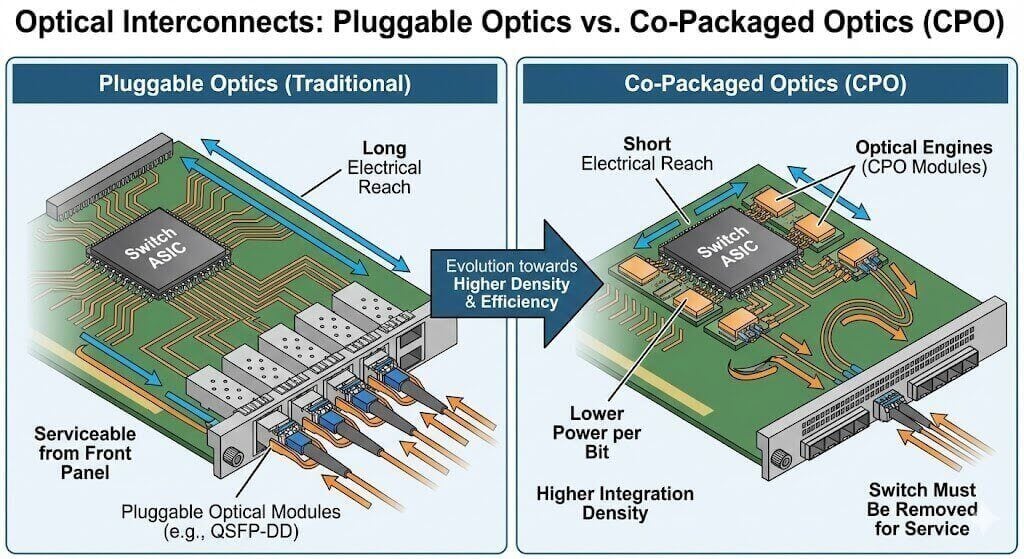
CPO (Co-Packaged Optics) vs. LPO (Linear Drive Pluggable Optics)
To break physical limits of electrical interconnects (SerDes distance constraints) and reduce power consumption, optoelectronic integration is the ultimate direction.
CPO: Encapsulates the optical engine directly on the switch chip substrate. While energy efficiency is excellent, due to maintenance difficulties (optical modules are not hot-swappable), it is currently only applied tentatively in specific ultra-high-density scenarios (e.g., 51.2T and above); mass adoption will take time.
LPO: As a transition solution to CPO, LPO removes the DSP chip from the optical module, using the switch ASIC’s powerful SerDes to drive optical components directly. This significantly reduces power and latency while retaining pluggable characteristics, making it a hot technical trend in the current 400G/800G market.
Conclusion
The 400G Ethernet switch market is at a golden intersection of technological innovation and scale application. AI is not only a consumer of bandwidth but a catalyst for network architecture reconstruction.
- Technical Aspect: “Lossless,” “Low Latency,” and “Visibility” have become the new three-dimensional standards for measuring switch performance. Shared buffer architectures, intelligent congestion control algorithms (e.g., iLossless, RALB), and hardware-level telemetry capabilities are key to distinguishing high-end AI switches from general-purpose switches.
- Market Aspect: Although NVIDIA leads with AI full-stack solutions, Arista, Cisco, and Chinese vendors (Huawei, H3C, Ruijie) are building a powerful Ethernet camp with open ecosystems, cost-performance ratios, and differentiated software functions, gradually eroding InfiniBand’s market space.
For enterprises and institutions selecting 400G switches, attention should not be limited to port density and price but should deeply evaluate actual performance in RoCEv2 environments, the maturity of congestion control algorithms, and compatibility with existing AI computing platforms. With the advancement of UEC standards and the arrival of 800G, a more open, efficient, and intelligent Ethernet ecosystem is accelerating its formation.
Related Products:
-
 NVIDIA MSN4700-WS2FC Spectrum-3 Based 400GbE 1U Open Ethernet Switch with Cumulus Linux, 32 QSFP-DD Ports, 2 AC Power Supplies, x86 CPU, Standard Depth, P2C Airflow, Rail Kit
$28900.00
NVIDIA MSN4700-WS2FC Spectrum-3 Based 400GbE 1U Open Ethernet Switch with Cumulus Linux, 32 QSFP-DD Ports, 2 AC Power Supplies, x86 CPU, Standard Depth, P2C Airflow, Rail Kit
$28900.00
-
NVIDIA SN5400 Spectrum-4 Based 400GbE 2U Open Ethernet Switch with Cumulus Linux Authentication, 64 QSFP56-DD Ports, 2xSFP28 Ports, 2 AC Power Supplies, x86 CPU, Secure Boot, Standard Depth, C2P Airflow, Tool-less Rail Kit
$39000.00
-
NVIDIA MQM9790-NS2F Quantum-2 NDR InfiniBand Switch, 64 x 400Gb/s Ports, 32 OSFP Cages, Unmanaged, P2C Airflow(forward)
$24000.00
-
NVIDIA MQM9700-NS2R Quantum-2 NDR InfiniBand Switch, 64-ports NDR 400Gb/s, 32 OSFP Ports, Managed, P2C Airflow(reverse)
$34000.00
-
NVIDIA MQM9700-NS2F Quantum-2 NDR InfiniBand Switch, 64 x 400Gb/s Ports, 32 OSFP ports, Managed, P2C Airflow(forward)
$30000.00
-
NVIDIA MQM9790-NS2R Quantum-2 NDR InfiniBand Switch, 64-ports NDR 400Gb/s, 32 OSFP Ports, Unmanaged, P2C Airflow (reverse)
$24000.00





