
In the rapidly evolving landscape of AI infrastructure, AMD is emerging as a game-changer, particularly in liquid cooling technologies. As data centers push the boundaries of performance and efficiency, AMD’s latest advancements are setting new benchmarks. FiberMall, a specialist provider of optical-communication products and solutions, is committed to delivering cost-effective offerings to global data centers, cloud computing environments, enterprise networks, access networks, and wireless systems. Renowned for its leadership in AI-enabled communication networks, FiberMall is an ideal partner if you’re seeking high-quality, value-driven optical-communication solutions. For more details, you can visit their official website or reach out directly to their customer support team.
This blog explores AMD’s groundbreaking developments in AI liquid cooling, from massive GPU clusters to the innovative MI350 series. Whether you’re an AI enthusiast, data center operator, or tech investor, these insights highlight why AMD is becoming the wind vane for the next era of AI computing.
TensorWave Deploys North America’s Largest AMD Liquid-Cooled Server Cluster
TensorWave, a rising star in AI infrastructure, has recently announced the successful deployment of North America’s largest AMD GPU training cluster. Powered by 8,192 Instinct MI325X GPU accelerators, this setup marks the first large-scale direct liquid cooling (DLC) cluster using this GPU model.

TensorWave’s focus on AMD’s cutting-edge hardware enables efficient computing platforms for enterprises, research institutions, and developers. This colossal cluster not only sets a scale record but also injects fresh momentum into AI development. Industry analysts note that AMD-based clusters offer superior cost-effectiveness—potentially saving up to 30% compared to NVIDIA’s DGX systems for equivalent computing power.
As more organizations adopt AMD GPUs, AI infrastructure costs could drop further, accelerating AI adoption across industries. For optical communication needs in such high-performance setups, FiberMall provides reliable, AI-optimized solutions to ensure seamless data transmission.

AMD Unveils MI350 Chip with Full Liquid Cooling Architecture, Garnering Market Enthusiasm
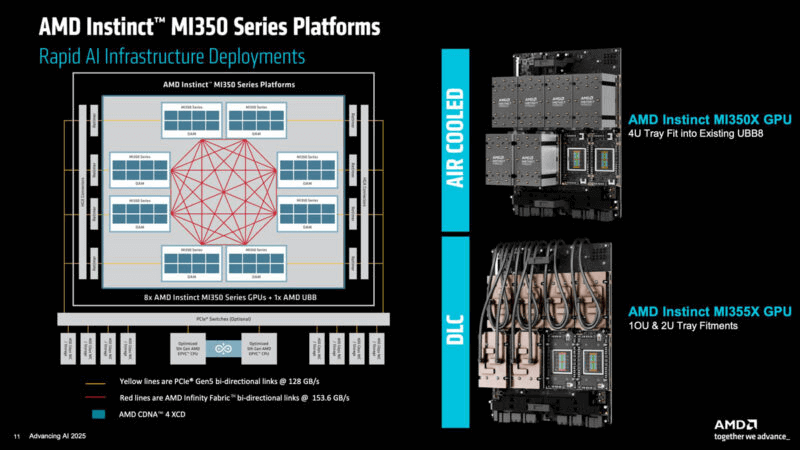
On June 12, 2025, AMD hosted the “Advancing AI 2025” conference in San Jose, California, where it officially launched the Instinct MI350 series GPU accelerators. These GPUs enable ultra-large-scale computing clusters through multi-card collaboration, with single nodes supporting up to eight cards in parallel, delivering 2,304GB of HBM3E memory. Performance peaks at over 80.5 PFlops in FP8 precision and 161 PFlops in FP6/FP4 low-precision computing, rivaling NVIDIA’s GB200.
Inter-card connectivity uses bidirectional Infinity Fabric channels, while CPU connections leverage 128GB/s PCIe 5.0 for bottleneck-free data transfer. AMD offers both air-cooled and liquid-cooled versions; air cooling supports up to 64 cards, while liquid cooling scales to 128 cards (2U-5U racks) for diverse supercomputing needs.



The MI350X module consumes 1,000W with air cooling, while the high-performance MI355X hits 1,400W, primarily using liquid cooling. Partners like Supermicro, Pegatron, and Gigabyte have already introduced MI350 series liquid-cooled servers.


In the global high-end AI chip market, NVIDIA holds over 80% share, but AMD’s MI350 resurgence—matching GB200 performance—signals a shift. For liquid cooling ecosystems, AMD’s progress offers alternatives to NVIDIA’s dominance, fostering healthier competition. Leading cloud providers, including major hyperscalers and Neo Cloud, will integrate MI350, with Dell, HPE, and Supermicro following suit. Mass production began early this month, with initial partner servers and CSP instances slated for Q3 2025—many favoring liquid-cooled variants.

FiberMall’s expertise in AI-enabled optical networks complements these deployments, providing cost-effective interconnects for high-bandwidth AI clusters.
AMD’s Driving Impact on the Liquid Cooling Market
NVIDIA’s near-monopoly has tied liquid cooling advancements to its ecosystem, including restrictive whitelists that deter partners. AMD’s large-scale liquid-cooled clusters and MI350 launch are a boon, potentially challenging NVIDIA alongside players like Huawei. This could invigorate liquid cooling suppliers outside NVIDIA’s orbit.
AMD claims MI350 will boost AI platform energy efficiency by 38 times within five years, with plans for another 20x improvement by 2030—reducing energy use by up to 95%.
Deep Dive: AMD MI350 Series Chips, OAM, UBB, Liquid-Cooled Servers, and Rack Deployments
At Advancing AI 2025, AMD introduced the Instinct MI350 series, including MI350X and MI355X, poised to compete head-on with NVIDIA’s Blackwell.

Instinct MI350 Overview
Both models feature 288GB HBM3E memory at 8TB/s bandwidth. MI355X delivers full performance: FP64 at 79 TFlops, FP16 at 5 PFlops, FP8 at 10 PFlops, and FP6/FP4 at 20 PFlops, with up to 1,400W TDP. MI350X is scaled back by 8%, peaking at 18.4 PFlops in FP4 with 1,000W TDP.
AMD Instinct MI350 Series Chips
The MI350X and MI355X share a chip design, built on a 3D hybrid bonding architecture using TSMC’s 3nm (N3P) and 6nm processes.


Comparison: AMD MI350X vs. NVIDIA B200/GB200
| Parameter | AMD MI350X | NVIDIA B200 | NVIDIA GB200 |
| Architecture | CDNA 4 (3D Hybrid Bonding) | Blackwell (Dual Die Integration) | Blackwell + Grace CPU (Dual B200 + 1 Grace) |
| Process Node | TSMC 3nm (N3P) + 6nm (IOD) Hybrid Packaging | TSMC 4nm (N4P) | TSMC 4nm (N4P) |
| Transistors | 185 Billion | 208 Billion | 416 Billion (Dual B200) |
| Memory Config | 288GB HBM3E (12Hi Stack), 8TB/s Bandwidth | 192GB HBM3E (8Hi Stack), 7.7TB/s Bandwidth | 384GB HBM3E (Dual B200), 15.4TB/s Bandwidth |
| FP4 Compute | 18.4 PFLOPS (36.8 PFLOPS Sparse) | 20 PFLOPS (FP4 Dense) | 40 PFLOPS (Dual B200) |
| FP8 Compute | 9.2 PFLOPS (18.4 PFLOPS Sparse) | 10 PFLOPS | 20 PFLOPS |
| FP32 Compute | 144 TFLOPS | 75 TFLOPS | 150 TFLOPS |
| FP64 Compute | 72 TFLOPS (2x B200 Double Precision) | 37 TFLOPS | 74 TFLOPS |
| Interconnect | 153.6GB/s Infinity Fabric (8 Cards/Node), Ultra Ethernet to 128 Cards | 1.8TB/s NVLink 5.0 (Per Card), 576 Cards in NVL72 | 1.8TB/s NVLink 5.0 (Per B200), 129.6TB/s Bidirectional in 72-Card Cluster |
| Power Consumption | 1000W (Air-Cooled) | 1000W (Liquid-Cooled) | 2700W (Dual B200 + Grace) |
| Software Ecosystem | ROCm 7 with PyTorch/TensorFlow Optimization, FP4/FP6 Support | CUDA 12.5+ with FP4/FP8 Precision, TensorRT-LLM Inference | CUDA 12.5+ with Grace CPU Optimization for Trillion-Parameter Models |
| Typical Performance | Llama 3.1 405B Inference 30% Faster than B200; 8-Card FP4 at 147 PFLOPS | GPT-3 Training 4x H100; Single-Card FP4 Inference 5x H100 | 72-Card NVL72 FP4 at 1.4 EFLOPS; Inference Cost 25% Less than H100 |
| Price (2025) | $25,000 (67% Recent Increase, Still 17% Below B200) | $30,000 | $60,000+ (Dual B200 + Grace) |
| Efficiency | 30% Higher HBM Bandwidth per Watt; 40% More Tokens per Dollar than B200 | 25% Higher FP4 per Transistor; 50% Better NVLink Efficiency | 14.8 PFLOPS/W in Liquid Cooling for FP4 |
| Differentiation | Unique FP6/FP4 Dual-Precision Inference; 288GB for 520B-Parameter Models | 2nd-Gen Transformer Engine for FP4; Chip-Level RAS for Reliability | Grace CPU Unified Memory; Decompression Engine for Data Loading |
MI350X boasts 60% more memory than B200 (192GB) with matching bandwidth. It leads in FP64/FP32 by ~1x, FP6 by up to 1.2x, and low-precision by ~10%. Inference matches or exceeds by 30%, training is comparable or 10%+ ahead in FP8 fine-tuning—all at higher cost-efficiency (40% more tokens per dollar).
AMD Instinct MI350 OAM
The OAM form factor is compact, with a thick PCB similar to MI325X.

AMD Instinct MI350 UBB
Here is the MI350 OAM package installed into a UBB alongside seven other GPUs for a total of eight.

AMD Instinct MI350 On UBB 8 GPU No Cooling 2
Here is another angle of that.

AMD Instinct MI350 On UBB 8 GPU No Cooling 1
Here is a look at the entire UBB with eight GPUs installed.

AMD Instinct MI350 UBB 8 GPU No Cooling
In a lot of ways, this is similar to the previous generation AMD Instinct MI325X board, and that is the point.

AMD Instinct MI350 On UBB 8 GPU No Cooling 3
On one end, we have the UBB connectors and a heatsink for the PCIe retimers.

AMD Instinct MI350X UBB PCIe Retimers
There is also a SMC for management.

AMD Instinct MI350 SMC
Beyond the board itself, is also the cooling.
AMD Instinct MI350X Air Cooling
Here is an OAM module with a big air cooling heatsink. This air cooling is the AMD Instinct MI350X.

AMD Instinct MI350X Cooler
Here are eight of these on the UBB. This is similar to what we saw above, just with the eight big heatsins.

AMD Instinct MI350X UBB 8 GPU
Here is another view of the heatsinks from the SMC and handle side.

AMD Instinct MI350X UBB 8 GPU Heatsink Profile
For some reference, here is the AMD MI300X’s UBB:

AMD MI300X 8 GPU OAM UBB 1
AMD also has the MI355X liquid-cooled version of this which allows for higher TDP and higher performance per card.
AMD MI350 Series AI Servers
Partners include Supermicro (4U/2U liquid-cooled, up to eight MI355X), Compal (7U, up to eight), and ASRock (4U, eight MI355X).
MI350 Rack Deployments
Single nodes max at eight cards (2,304GB memory, up to 161 PFlops FP6/FP4). Air cooling scales to 64 cards; liquid to 128. A 128-card setup offers 36TB memory and up to 2.57 EFlops FP6/FP4.
Conclusion: AMD’s Liquid Cooling Revolution
AMD’s MI350 series and TensorWave’s cluster underscore a pivotal shift in AI liquid cooling, challenging monopolies and driving efficiency. As AI demands soar, these innovations promise cost savings and scalability.
FiberMall stands ready to support your AI infrastructure with top-tier optical-communication solutions. Visit our website or contact customer support for tailored advice.
Related Products:
-
 OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 Female Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 Male Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2400.00
-
OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2400.00
-
OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 Female Plug Pigtail 5m Immersion Liquid Cooling Optical Transceivers
$2330.00
-
OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 Male Plug Pigtail 5m Immersion Liquid Cooling Optical Transceivers
$2330.00
-
OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$2250.00
-
OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$2250.00











