


Отчет о совместимости и взаимосвязи модулей оптических приемопередатчиков 800G SR8 и 400G SR4
Средство записи журнала изменений версий V0. Образец теста Cassie Test Цель тестирования Объекты: 800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. Проведя соответствующие тесты, параметры теста соответствуют соответствующим отраслевым стандартам, и тестовые модули можно нормально использовать для коммутатора Nvidia (Mellanox) MQM9790, сетевой карты Nvidia (Mellanox) ConnectX-7 и Nvidia (Mellanox) BlueField-3, прокладывая основа для

Представляем титанов: Nvidia GeForce RTX 4090 против Nvidia A100 для максимальной производительности
Nvidia GeForce RTX 4090 и Nvidia A100, находящиеся в бесконечном поиске усовершенствований в компьютерных технологиях, представляют собой самые совершенные графические процессоры, которые когда-либо были созданы. Эти два технологических гиганта, хотя и имеют схожие корни изобретений, имеют разные цели существования. В этой статье,
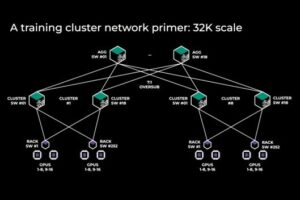
Кластер A100/H100/GH200: требования к сетевой архитектуре и оптическим модулям
Традиционные центры обработки данных претерпели переход от трехуровневой архитектуры к листовой архитектуре, в первую очередь для удовлетворения растущего трафика с востока на запад внутри центра обработки данных. Поскольку процесс миграции данных в облако продолжает ускоряться, масштабы центров обработки данных облачных вычислений продолжают расширяться. Приложения
Развитие PCIE
В 2012 году связь между двумя платами была реализована по оптоволоконному кабелю с использованием протокола PCIE. Преимущества этого подхода заключаются в следующем: зарезервированный оптический порт позволяет физически разделить два устройства, а зарезервированный оптический интерфейс и память совместимы и могут быть доступны друг другу.

Раскрытие возможностей графических процессоров NVIDIA H100 в высокопроизводительных серверах
Напряженная ситуация современных вычислений, характеризующаяся увеличением объемов данных и ростом вычислительных требований, стала свидетелем появления графического процессора NVIDIA H100, новатора в области высокопроизводительных серверов. Целью статьи является раскрытие революционных функций, а также новых технологий, лежащих в основе графического процессора NVIDIA H100, который

Раскрытие потенциала кабелей Nvidia MPO для оптоволоконных сетей нового поколения
Кабели Nvidia MPO находятся на переднем крае инноваций в современном постоянно меняющемся мире телекоммуникаций и сетей центров обработки данных. Они обещают значительный прирост оптоволоконных сетей с точки зрения пропускной способности, эффективности и масштабируемости. В данной статье рассматривается оценка различных возможностей. offблагодаря этим передовым кабельным решениям с уважением

Представляем платформу NVIDIA HGX: ускорение искусственного интеллекта и высокопроизводительных вычислений
Платформа HGX от NVIDIA — это революционное достижение в области искусственного интеллекта и высокопроизводительных вычислений. Он был разработан для удовлетворения растущих потребностей в электроэнергии в современных средах с интенсивным использованием данных и объединен с передовой технологией графического процессора; он обеспечивает выдающуюся эффективность обработки, а также гибкость. Целью данного введения является дать читателям предварительное