
The demand for AI hardware is booming, and the shipment of computing chips is expected to accelerate. Based on FiberMall’s research on the computing power industry chain, FiberMall forecasts that the shipment of NVIDIA’s H-series and B-series chips will reach 3.56 million and 350,000 units respectively in 2024. In 2025, with the further delivery of the GB200, the total shipment of the B-series GPUs is expected to reach 2.5 million units. Additionally, FiberMall expects that the deployment of Google’s TPU and AMD’s MI300 will also continue, all of which will drive the synchronized ramp-up of 800G OSFP and 1.6T OSFP-XD optical modules at the network level.
With positive developments in the industry chain, the demand for 1.6T is expected to exceed expectations. At OFC 2024, multiple exhibitors showcased the latest 1.6T OSFP-XD optical module products. Previously, NVIDIA’s new Blackwell AI chip announced at the GTC conference has raised higher requirements for interconnectivity, and the X800 series switches enable the construction of 1.6T networks. Meanwhile, the upstream optical module industry chain is also gradually in place, with Marvell expecting its 1.6T DSP with a single channel of 200G to be deployed by the end of 2024, and Broadcom stating that 200G EML is ready for mass production. FiberMall believes that the 1.6T industry chain, both upstream and downstream, is accelerating its maturity. In terms of deployment, FiberMall expects that in the second half of 2024, 1.6T OSFP-XD optical modules will likely be deployed in coordination with the mass production of NVIDIA’s B-series chips, initially achieving small-scale ramp-up, and then seeing large-scale deployment in 2025. Technologically, FiberMall believes that EML single-mode will still be the mainstream in the 1.6T era, while also being optimistic about the rapid growth of the penetration rate of new technology solutions such as silicon photonics and linear-drive pluggable optics (LPO).
In terms of demand, FiberMall forecasts that in 2025:
1) The demand from the top 1-2 overseas customers will quickly migrate from 800G OSFP to 1.6T, leading to a rapid ramp-up of 1.6T OSFP-XD optical modules;
2) While some customers’ 800G OSFP demand may decline due to the migration to higher speeds, another group of customers’ demand will shift from 400G OSFP to 800G OSFP, providing certain support for the overall 800G OSFP demand.
FiberMall’s scenario analysis on the total shipment of 1.6T in 2025 is based on two core variables: 1) The overall prosperity of the AI hardware procurement (B-series GPU shipment of 2-3 million units); 2) The maturity timeline of the 1.6T network (the proportion of B-series GPU paired with 1.6T networking solutions at 70%-90%). The analysis indicates that the total shipment of 1.6T OSFP-XD optical modules in 2025 will be 3.6-5.95 million units, with the neutral scenario at 4.7 million units, which is higher than the current market expectations.
Scenario Analysis on the Demand for 1.6T OSFP-XD Optical Modules
FiberMall has conducted a comprehensive analysis, taking into account the forecasted shipment of AI chips such as NVIDIA, TPU, and MI300, the correlation between optical modules and AI chips, as well as the choice of optical module speed configurations. The analysis indicates that the demand for 800G OSFP and 1.6T OSFP-XD optical modules in 2025 may reach 7.91 million and 4.7 million units, respectively. The key assumptions are as follows:
- AI chip shipment forecast: At the GTC 2024 conference, NVIDIA announced its first-generation B-series cloud GPUs based on the Blackwell architecture, as well as the new GB200 CPU+GPU architecture super chip and the corresponding GB200 NVL72 computing unit, which can provide supercomputing-level 1E Flops performance in a single cabinet, achieving a performance upgrade from chip to system. In addition to the general-purpose GPUs, FiberMall expects that the deployment of Google’s TPU and AMD’s MI300 will also continue, driving the demand for 800G OSFP/1.6T OSFP-XD optical module configurations.
- Estimation of the correlation between optical modules and AI chips: Under the InfiniBand fat-tree network architecture, due to the non-convergent network characteristics, the total bandwidth at each network layer is consistent. Based on the assumption that the ratio of AI acceleration cards to network cards is 1:1, FiberMall calculates that the ratio of H100 to 800G OSFP optical modules is 1:3 in a three-layer network architecture and 1:2 in a two-layer architecture. At the GTC 2024 conference, NVIDIA announced the X800 series switches, among which the Q3400-RA 4U switch based on the InfiniBand protocol has 144 800G OSFP ports, which can be equivalently allocated as 72 1.6T ports. FiberMall believes that the performance of the Quantum-X800 series switches with 144 ports is significantly improved compared to the previous generation QM9700 series with 64 ports, and the number of clusters supported by the two-layer Quantum-X800 switches in the fat-tree architecture has increased. From a relatively conservative perspective, FiberMall predicts the effective demand for optical modules based on a 1:2 ratio of B-series GPUs to 1.6T OSFP-XD optical modules.
- Choice of optical module speed configurations: In general, FiberMall expects that cloud providers or AI manufacturers will tend to prioritize the configuration of higher-speed networks to maximize the computing performance of their clusters. However, considering that the 1.6T hardware ecosystem is not yet fully mature in 2024, FiberMall predicts that customers may primarily adopt 800G OSFP speeds when deploying small-scale networks with NVIDIA’s B-series chips this year, and the 1.6T configuration paired with B-series chips is expected to become the mainstream solution by 2025 as the 1.6T industry chain matures. At the current stage, the industry does not have clear order guidance on the total shipment of B-series GPUs in 2025, and the forecast of B-series chip shipment is also subject to various variables, such as the release timeline of GPT-5, the deployment of new AI large models or applications, and the exploration of the commercial viability of AI. These factors will affect the overall procurement of AI hardware by leading cloud providers and other AI industry participants. FiberMall has observed that the market’s expectations for the capital expenditure of the top four North American cloud providers in 2024 have been revised upwards over the past year, and these companies have publicly stated that they will continue to increase their investment in AI infrastructure, reflecting the sustained progress of the AI industry and the expansion of underlying hardware demand. FiberMall believes that the capital expenditure of leading companies on AI hardware in 2025 will continue to be influenced by the changes in the AI industry.
FiberMall has conducted a scenario analysis on the total shipment of 1.6T OSFP-XD optical modules in 2025, using two core variables: 1) The overall prosperity of the AI hardware procurement (B-series GPU shipment of 2-3 million units); 2) The maturity timeline of the 1.6T network (the proportion of B-series GPU paired with 1.6T networking solutions at 70%-90%, with the remaining being 800G OSFP).
Considering the prosperity of the AI industry demand and the commercial maturity timeline of the 1.6T optical port key technologies as variables, FiberMall’s scenario analysis indicates that the total shipment of 1.6T OSFP-XD optical modules in 2025 is expected to be in the range of 3.6-5.95 million units, with the overall level of the range higher than the current market expectations. The new generation of computing clusters maintains a high demand for high-speed optical modules, and the prosperity of the industry chain resonates upwards.
Under the wave of AI development, the new generation of computing clusters is showing two trends of change:
- Rapid growth in network traffic, with east-west traffic as the main driver: According to the “White Paper on the Evolution of Smart Computing Center Network (2023)” published by China Mobile Research Institute, intelligent computing requires a large amount of parallel computing, generating All Reduce (collective communication) data volumes reaching hundreds of GB. FiberMall believes that against the backdrop of the proliferation of large models, the “thousand-model war” will further drive the growth of network traffic. Meanwhile, the proportion of east-west (between servers) traffic has increased significantly, and according to Cisco’s forecast, the current east-west traffic proportion may have reached 80-90% of the network traffic.
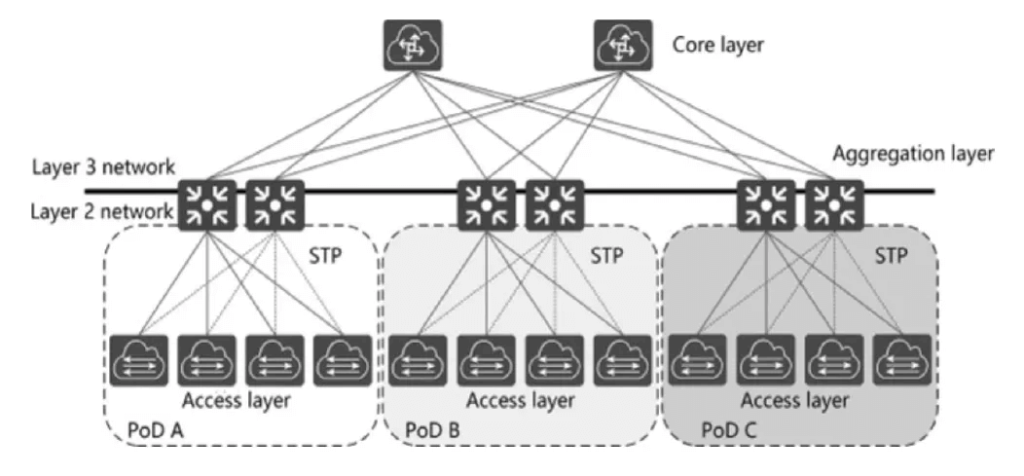
- The typical network architecture is transitioning from the three-layer tree-like architecture to the multi-core architecture represented by the spine-leaf architecture: According to the public information from the NVIDIA and Inspur China joint training on NVIDIA’s new-generation data center network products, data centers were mainly based on the traditional three-layer architecture, with a tree-like architecture, having 2 cores and gradually converging upwards, with north-south traffic as the main direction. The three-layer network architecture consists of the access layer, aggregation layer, and core layer. The access layer directly connects to the user, the aggregation layer connects the access layer and the core layer, providing services such as firewalls, SSL offloading, intrusion detection, and network analysis, and the core layer is the high-speed switching backbone of the network. Due to the increased demand for communication performance in intelligent computing, the demand for AI cloud training and inference is driving the evolution of the data center network architecture towards a multi-layer, non-convergent, and more scalable form.
FiberMall believes that the overall growth in traffic of the smart computing center and the evolution of the network architecture jointly drive the increase in connection demand, leading to the growth in optical module usage and speed upgrades.
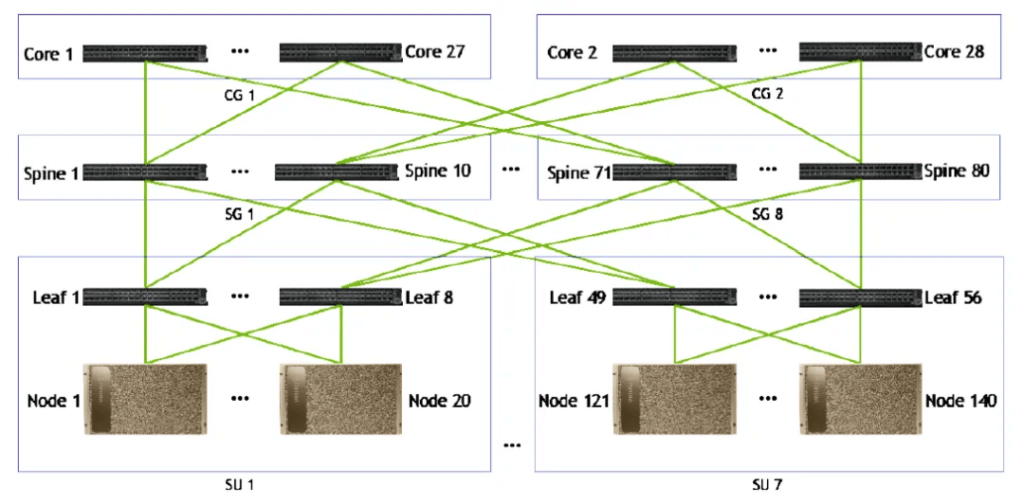
NVIDIA’s data centers use a fat-tree architecture to build a non-convergent network, where the three-layer network can connect more nodes than the two-layer network. Compared to the traditional fat-tree model, NVIDIA’s data center fat-tree model uses a large number of high-performance switches to build a large-scale non-blocking network, and even increases the uplink ports to avoid packet loss and network collapse, more similar to a diffusion-type architecture. In terms of the number of layers, there are two-layer and three-layer networking options, where the three-layer network architecture can connect more nodes than the two-layer architecture, allowing for more AI chips to be interconnected, suitable for the training of AI large models with larger parameters.
The DGX H100 SuperPOD provides two networking options:
- Adopting a networking approach similar to the A100 SuperPOD, using CX-7 network cards and InfiniBand switches to achieve cross-server connections. According to the schematic diagram on NVIDIA’s website, FiberMall assumes that each H100 server is configured with 8 400G ConnectX-7 single-port smart network cards, with four CX-7 network cards integrated into one network module, and two network modules connecting to the InfiniBand switch with 2 * 400G NDR OSFP ports each, i.e., the network card side corresponds to 4 800G OSFP optical modules, and the network card connection to the first-layer switch also requires 4 800G OSFP optical modules, totaling 8 800G OSFP optical modules for the first-layer network. Due to the non-convergent network characteristics, the total bandwidth corresponding to each layer in the InfiniBand fat-tree network architecture is consistent, and based on the assumption that the ratio of AI acceleration cards to network cards is 1:1, FiberMall calculates that the ratio of H100 to 800G OSFP optical modules is 1:3 in a three-layer network architecture and 1:2 in a two-layer architecture.
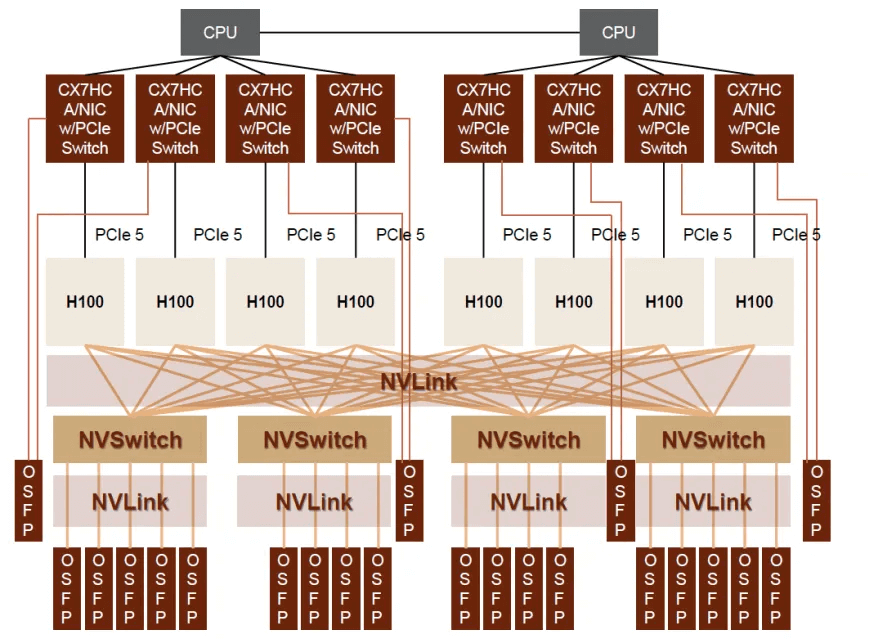
- Adopting the new NVLink switching system: Externalizing the NVLink used for high-speed GPU interconnection within servers to a 256-node cluster, using the fourth-generation NVLink and third-generation NVSwitch to build a two-layer (L1 and L2) NVLink network, enabling direct interconnection and shared memory access of up to 32 nodes (256 GPUs). In this NVLink networking solution, the GPUs and the L1 NVSwitch (within the cabinet) are interconnected using copper cables, while the L1 and L2 NVSwitch layers use optical interconnection, resulting in a demand for 18 pairs of 800G OSFP connections, with a higher ratio of H100 to 800G OSFP compared to the first networking option. In the 256 DGX GH200 AI supercomputer, FiberMall estimates that the ratio of GH200 to 800G OSFP optical modules may further increase to 1:9, with the core assumption that the interconnection between each node (with 8 GH200 chips) and the 3 L1 NVS within the node uses copper cables, and the 32 nodes in the DGX GH200 are connected to the 36 L2 NVS through optical interconnection, resulting in 1,152 (32*36) pairs of connections between L1 and L2, corresponding to 2,304 800G OSFP optical modules, a significant increase in optical module usage.
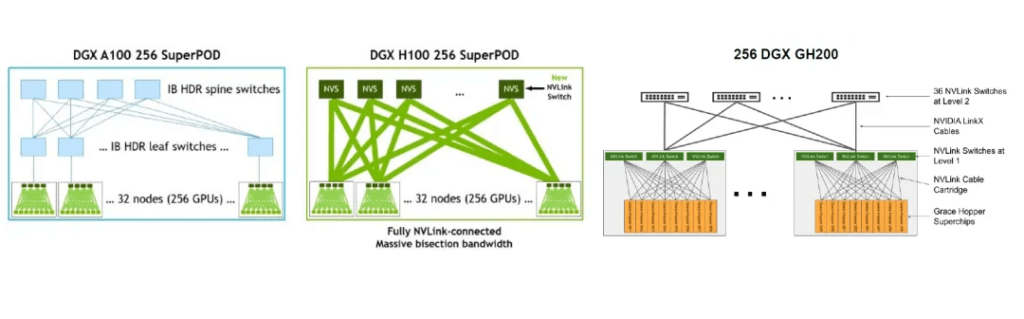
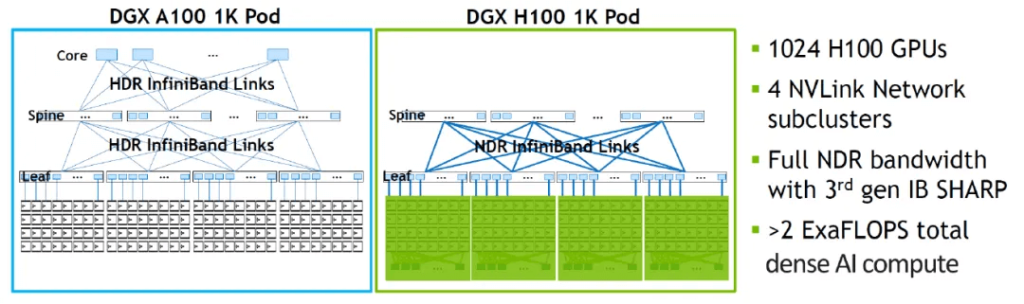
It is worth noting that to further expand the cluster to a scale of over a thousand GPUs based on the 256-GPU interconnected SuperPOD, InfiniBand Links need to be used for extended networking. Taking a 1024-GPU cluster as an example, according to NVIDIA’s website, by forming a two-layer spine-leaf network architecture through NDR InfiniBand Links, 4 DGX H100 256 SuperPOD clusters can be connected to achieve the direct interconnection of 1024 GPUs. FiberMall believes that in the InfiniBand network outside the SuperPOD, the usage of 800G OSFP optical modules can still be estimated based on the previous ratio relationship in the two-layer architecture, i.e., the ratio of H100 GPU to 800G OSFP optical module is approximately 1:2.
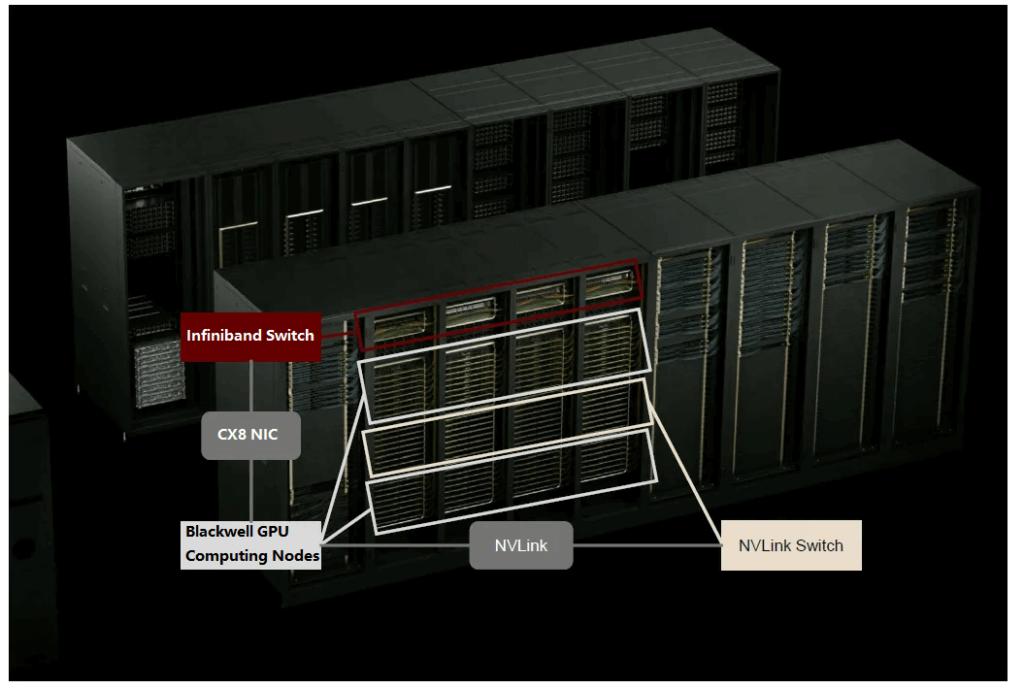
At the GTC 2024 conference, NVIDIA announced the GB200 NVL72, which consists of 18 computing nodes, 9 NVLink Switch trays, and 1 Q3400-RA 4U InfiniBand switch. Each computing node is composed of 4 Blackwell GPUs and 2 CPUs, meaning the GB200 NVL72 contains 72 GPUs. Each node is configured with 4 800G ConnectX-8 network cards, and the ratio of Blackwell GPUs to CX-8 network cards remains 1:1. This implies that when using InfiniBand for AI backend networking, the ratio of B-series GPUs to 1.6T OSFP-XD optical modules will continue the same proportion as the H100 era (1:2 for two-layer networking, 1:3 for three-layer networking).
As mentioned in the previous section, NVIDIA’s new Quantum-X800 series switches, which can be configured with 144 800G OSFP ports (equivalent to 72 1.6T ports), enable the construction of 1.6T networks. Their performance is significantly improved compared to the previous generation 64-port switches, and the number of clusters supported by the two-layer Quantum-X800 switches in the fat-tree architecture has increased to 10,368 nodes. This suggests that the coverage of the two-layer networking may be expanded, and therefore, FiberMall has conservatively adopted a 1:2 ratio in the scenario analysis. However, FiberMall believes that as the GPU cluster scale continues to expand and the demand for interconnection at the 10,000-card and above level increases, the required number of optical modules may further grow.

In terms of NVLink networking, in the GB200 NVL72 single-cabinet solution, the computing nodes within the cabinet are interconnected with the NVLink Switch using copper cables, without the need for optical-electrical signal conversion, which is consistent with the previous GH200 cabinet interconnection solution. However, in certain high-performance AI computing scenarios, the fifth-generation NVLink can be used to achieve high-speed interconnection of up to 8 GB200 NVL72 systems (576 Blackwell GPUs). When interconnecting GB200 NVL72 cabinets based on NVLink, two-by-two interconnection can use LACC copper connections, but for multi-cabinet interconnection, as referenced in the previous GH200 networking architecture, an additional L2-layer NVS is required. If optical interconnection is adopted between the L1 and L2 NVS, FiberMall expects the ratio of optical modules to GPUs to further increase.
According to NVIDIA’s website, the performance of GB200 is significantly improved compared to the previous generation. Compared to a computing cluster of the same 72 H100 GPUs, the GB200 can achieve approximately 30 times higher performance for large model inference, with a 25-fold reduction in cost and power consumption. FiberMall expects the shipment share of Blackwell GPUs in GB200 to be higher than that of the GH200 in the Hopper series. In summary, FiberMall believes that the performance advantage of GB200 will likely lead to an increase in its shipment share, and the NVLink connection scenario across multiple cabinets in the system is still expected to promote the growth of the optical module ratio compared to the single-chip connection solution. The combination of these two factors is expected to drive the increased demand for high-speed optical modules in the new-generation computing ecosystem.
Risk Factors
- 200G EML optical chip production capacity falls short of expectations. The availability of 200G EML optical chip production capacity can provide upstream core raw material support for the mature deployment of 1.6T OSFP-XD optical modules. Suppose the production timeline or ramp-up speed of 200G EML optical chips falls short of expectations. In that case, it may delay the industry deployment of 1.6T, impacting the shipment volume of 1.6T OSFP-XD optical modules in 2025.
- AI industry demand falls short of expectations. As the digital and intelligent transformation of society continues, the deployment of AI large models is accelerating to empower various industries. FiberMall believes that the thriving development of artificial intelligence is driving the sustained increase in computing power demand, which in turn boosts the demand for AI hardware such as servers, optical modules, and switches. If the deployment of AI large models or applications falls short of expectations, or the commercialization path is hindered, it may adversely affect the investment intensity and determination of AI industry participants, represented by leading cloud providers, in AI-related infrastructure, which could impact the market growth and product iteration speed of upstream AI hardware equipment.
Related Products:
-
 OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
-
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km Dual Duplex LC SMF Optical Transceiver Module
$20000.00
-
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF Optical Transceiver Module
$12000.00


