
Recently, New H3C introduced its groundbreaking lossless network solution and compute cluster switch—the H3C S12500AI—built upon the DDC (Diversity Dynamic-Connectivity) architecture. Tailored to meet the demanding requirements of scenarios involving the interconnection of tens of thousands of compute cards, this solution redefines the network architecture of intelligent computing centers. Performance tests indicate that, compared with traditional networking schemes, the DDC-based design enhances effective bandwidth by up to 107%, with bandwidth utilization comparable to that of InfiniBand networks. Moreover, it is sufficiently adaptable to support diverse cluster deployments ranging from 1,000 to 70,000 nodes.

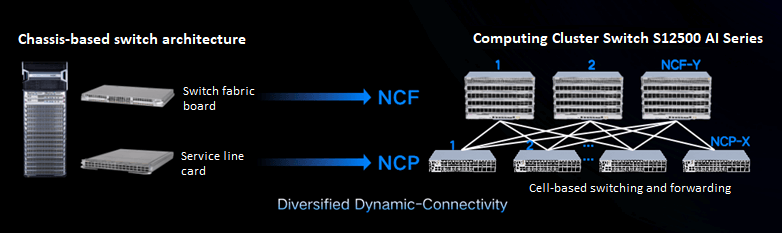
Designed for ultra-large-scale intelligent computing environments, the H3C S12500AI fully embraces the DDC architecture, offering superior scalability and adaptability. Its network switching unit (NCF) is delivered in a box-style format and supports up to 128×800G OSFP cell ports, while its network processing unit (NCP) features downlink ports compatible with 36×400G Q112 Ethernet ports and 18×800G OSFP Ethernet ports—ensuring seamless integration with mainstream network interface cards to guarantee an efficient and stable access experience.

Leveraging a multi-tier network design that integrates NCF and NCP units, the DDC architecture is capable of interconnecting large-scale clusters comprising over 70,000 cards. In addition, by adopting an open networking approach based on independent network elements, the solution eliminates the need for centralized network control units, thereby effectively mitigating the management risks associated with single-point failures. Test data further confirms that the DDC architecture not only achieves a 107% improvement in effective bandwidth over traditional setups but also significantly enhances the throughput and operational stability of intelligent computing networks.
What Is the DDC Architecture?
DDC (Diversity Dynamic-Connectivity) represents a revolutionary network architectural innovation. It decouples the core switching board from the service modules of traditional chassis-based switches, reconstructing the system as a distributed, interconnected cluster of independent units. By employing cell-based technology, DDC achieves non-blocking transmission. In an innovative twist, New H3C has merged cell switching with Ethernet protocols, enabling the architecture to accommodate diverse compute resources while facilitating multi-brand interconnection of network devices. In simple terms, the conventional chassis-based switch—comprising service cards and switching matrix cards—has been transformed into a set of independent, box-style devices.
Central to DDC technology is its novel cell spraying method, which segments data streams into standardized, fixed-length cells. This process can be likened to converting various models of vehicles into uniformly sized “mini cars,” where every unit shares identical dimensions, thereby maximizing the effective utilization of each lane. Importantly, this technique is entirely transparent to data flow characteristics and does not concern itself with the specific protocol contents.
In contrast to the packet-by-packet forwarding methods employed by InfiniBand (IB) and ROCE, DDC technology reassembles data packets on the network side without requiring hardware-based packet reassembly support on network interface cards. This approach ensures compatibility across NICs from various brands. Traditional transmission methods, such as stream-based forwarding—where all data flows with identical features (for example, a common five-tuple) are routed along a single link—are highly sensitive to flow characteristics, often resulting in overloading of certain channels while leaving others underutilized. Although packet-level spraying attempts to disperse data packets across multiple links, the variability in packet sizes often prevents ideal load balancing; it is analogous to managing a multi-use roadway where bulky trucks encroach upon the space allocated for smaller vehicles, thus leading to uneven load distribution.

What Value Does the DDC Architecture Offer?
The DDC architecture delivers significant benefits through its cell-based multipath load balancing. By employing both flow-level and packet-level forwarding, it markedly enhances network bandwidth utilization. This advantage is particularly beneficial for AI tensor parallelism and multi-expert parallelism; such applications are able to fully exploit the bandwidth advantages of scale-out networks. In addition, by implementing cell reordering on the switch side, the architecture decouples the packet-reordering responsibilities that would otherwise fall on the network interface cards (NICs). This decoupling not only broadens compatibility with devices from various manufacturers but also allows for more competitively priced NIC solutions. Given the current climate of U.S. restrictions on AI technology, the approach aligns well with the heterogeneous networking demands of a multi-vendor ecosystem comprising domestic GPUs and NICs. Moreover, by reducing network congestion and mitigating the latency penalties associated with endpoint packet reordering, the system significantly improves the efficiency of AI pre-training processes.

What Chip Solution Is Employed?
At present, the most mature chip solution in the field of cell-based forwarding is embodied in Broadcom’s StrataDNX product line—most notably, in its Jericho series chips. In fact, the StrataDNX series is based on the valuable asset acquired in 2009 when Broadcom purchased Dune Networks, a leader in the Ethernet switching chip market. At that time, Dune Networks enjoyed an excellent reputation with both superior technological expertise and market share relative to Broadcom. Post-acquisition, Broadcom integrated Dune’s technology into its StrataDNX product line, thereby creating high-performance, highly reliable switching chips.
The Jericho series itself is further divided into two complementary sub-series—Jericho and Ramon—according to specific functional roles. The Jericho chips are primarily deployed in line-card applications for chassis-based switches, corresponding to the NCP (Network Control Processor) component in the DDC solution. In contrast, the Ramon series functions as the switching NIC chip, or NCF, within chassis-based switching systems.
In 2023, Broadcom unveiled a significant innovative update with the launch of the Jericho3-Ramon3 chip. This breakthrough product marks a successful transition of the Jericho series into the era of artificial intelligence computing.

The Ramon3 chip, with a bandwidth of 51.2T, is employed in H3C’s S12500AI DDC solution, which uses a 128 × 800G (OSFP112) NFC interface configuration that typically incorporates two Ramon3 chips.
Meanwhile, the Jericho3 chip offers a bandwidth of 14.4T and supports two NCP interface configurations in the H3C solution—one with 18 × 800G and another with 36 × 400G—each of which generally employs a single Jericho3 chip.
Within AI computing environments, DDC technology demonstrates robust adaptability. Its architectural design achieves a breakthrough in scalability: a single-cluster configuration is capable of supporting interconnections among nearly ten thousand GPU cards, while a multi-cluster arrangement extends this capability to tens of thousands of cards. This capacity is well-suited to meet the training demands of the largest AI models currently in operation.
On the network performance front, DDC delivers optimizations targeted at eradicating key bottlenecks in distributed training. By leveraging an innovative traffic scheduling algorithm, the architecture achieves an effective bandwidth improvement of 107% compared to traditional ECMP-based networking solutions. This breakthrough is particularly effective for All-to-All communication modes, where it alleviates network congestion during coordinated multi-GPU training. Furthermore, in high-demand scenarios such as All-to-All communications, RoCE network bandwidth performance based on the DDC architecture improves by an average of 2.5% over standard industry solutions. The overall performance metrics are comparable to those of InfiniBand networks, and the system retains the benefits of plug-and-play capability, inherent load balancing, and complete decoupling of endpoint functionalities.

The advanced nature of the DDC architecture is further demonstrated by its multi-tenant support and compatibility with heterogeneous environments. By integrating both hardware and software features, the system achieves tenant isolation at a 16K granularity. Compared to traditional ACL and VxLAN approaches, this results in finer isolation and supports a larger number of tenants, all while maintaining zero bandwidth loss—a feature that is particularly beneficial for multi-tenant AI training deployments. Moreover, DDC seamlessly connects NICs and GPU devices from various vendors and models, thereby effectively addressing technical challenges arising from differing NIC ecosystems.
From an operational standpoint, DDC introduces a revolutionary simplification in network management. With native support for flit-level traffic scheduling in its switching mechanism, it eliminates the need for complicated tuning procedures, thus achieving true plug-and-play functionality. The system also supports one-click automatic deployment and provides end-to-end interconnection visualization, enabling network operations personnel to obtain a clear overview of the network status at any given time. Additionally, its chip-level fault detection mechanism permits immediate automatic switchover in the event of a failure, ensuring uninterrupted service continuity and providing dependable support for long-duration AI training sessions.
Related Products:
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MCP4Y10-N00A Compatible 0.5m (1.6ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Passive Direct Attach Copper Cable
$105.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00









