

800G SR8 and 400G SR4 Optical Transceiver Modules Compatibility and Interconnection Test Report
Version Change Log Writer V0 Sample Test Cassie Test Purpose Test Objects:800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. By conducting corresponding tests, the test parameters meet the relevant industry standards, and the test modules can be normally used for Nvidia (Mellanox) MQM9790 switch, Nvidia (Mellanox) ConnectX-7 network card and Nvidia (Mellanox) BlueField-3, laying a foundation for

Comprehensive Guide to AI Server Liquid Cooling Cold Plate Development, Manufacturing, Assembly, and Testing
In the rapidly evolving world of AI servers and high-performance computing, effective thermal management is critical. Liquid cooling cold plates have emerged as a superior solution for dissipating heat from high-power processors in data centers and cloud environments. This in-depth guide covers everything from cold plate manufacturing and assembly to development requirements

Unveiling Google’s TPU Architecture: OCS Optical Circuit Switching – The Evolution Engine from 4x4x4 Cube to 9216-Chip Ironwood
What makes Google’s TPU clusters stand out in the AI supercomputing race? How has the combination of 3D Torus topology and OCS (Optical Circuit Switching) technology enabled massive scaling while maintaining low latency and optimal TCO (Total Cost of Ownership)? In this in-depth blog post, we dive deep into the
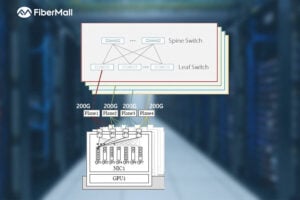
Dual-Plane and Multi-Plane Networking in AI Computing Centers
In the previous article, we discussed the differences between Scale-Out and Scale-Up. Scale-Up refers to vertical scaling by increasing the number of GPU/NPU cards within a single node to enhance individual node performance. Scale-Out, on the other hand, involves horizontal scaling by adding more nodes to expand the overall network scale, enabling
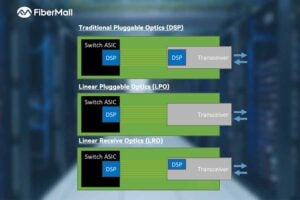
OCP 2025: FiberMall Showcases Advances in 1.6T and Higher DSP, LPO/LRO, and CPO Technologies
The rapid advancement of artificial intelligence (AI) and machine learning is driving an urgent demand for higher bandwidth in data centers. At OCP 2025, FiberMall delivered multiple presentations highlighting its progress in transceiver DSPs for AI applications, as well as LPO (Linear Pluggable Optics), LRO (Linear Receive Optics), and CPO

What is a Silicon Photonics Optical Module?
In the rapidly evolving world of data communication and high-performance computing, silicon photonics optical modules are emerging as a groundbreaking technology. Combining the maturity of silicon semiconductor processes with advanced photonics, these modules promise higher speeds, lower power consumption, and reduced costs. This in-depth guide explores the fundamentals, principles, advantages, industry

Key Design Principles for AI Clusters: Scale, Efficiency, and Flexibility
In the era of trillion-parameter AI models, building high-performance AI clusters has become a core competitive advantage for cloud providers and AI enterprises. This article deeply analyzes the unique network requirements of AI workloads, compares architectural differences between AI clusters and traditional data centers, and introduces two mainstream network design