
In recent years, the global rise of artificial intelligence (AI) has captured widespread attention across society. A common point of discussion surrounding AI is the concept of compute clusters—one of the three foundational pillars of AI, alongside algorithms and data. These compute clusters serve as the primary source of computational power, akin to a massive power station continuously fueling the AI revolution.

But what exactly constitutes an AI compute cluster? Why are they capable of delivering such immense computational performance? What does their internal architecture look like, and what key technologies are involved?
What Are AI Compute Clusters?
As the name suggests, an AI compute cluster is a system that delivers the computational resources required to perform AI tasks. A “cluster” refers to a group of independent devices connected via high-speed networks to function as a unified system.
By definition, an AI compute cluster is a distributed computing system formed by interconnecting numerous high-performance computing nodes (such as GPU or TPU servers) over high-speed networks.
AI workloads can generally be divided into two major categories: training and inference. Training tasks are typically more computation-intensive and complex, requiring significant computational resources. Inference tasks, by contrast, are relatively lightweight and less demanding.
Both processes heavily rely on matrix operations—including convolutions and tensor multiplications—that naturally lend themselves to parallelization. Thus, parallel computing chips such as GPUs, NPUs, and TPUs have become essential for AI processing. Collectively, these are referred to as AI chips.
AI chips are the fundamental units of AI computation, but a single chip cannot operate independently; it must be integrated into a circuit board. Depending on the application:
Embedded in mobile phone motherboards or integrated into SoCs, they power mobile AI capabilities.
Installed in modules for IoT devices, they enable edge intelligence for equipment such as autonomous vehicles, robotic arms, and surveillance cameras.
Integrated into base stations, routers, and gateways, they provide edge-side AI computing—typically limited to inference due to size and power constraints.
For more demanding training tasks, systems must support multiple AI chips. This is achieved by building AI compute boards and installing several into a single server, effectively transforming a standard server into an AI server.

Typically, an AI server houses eight compute cards, though some models support up to twenty cards. However, due to heat dissipation and power limitations, further expansion becomes impractical.
With this configuration, the computational capability increases significantly—allowing the server to easily handle inference and even perform smaller-scale training tasks. An example is the DeepSeek model, which has optimized its architecture and algorithms to significantly reduce computational demands. Consequently, many vendors now offer integrated “all-in-one” racks—consisting of AI servers, storage, and power supplies—that support private deployment of DeepSeek models for enterprise customers.
Nevertheless, the computational power of these setups remains finite. Training extremely large-scale models—those with tens or hundreds of billions of parameters—demands far greater resources. This leads to the development of large-scale AI compute clusters, which incorporate an even greater number of AI chips.
Terms like “10K-scale” or “100K-scale” refer to clusters comprising 10,000 or 100,000 AI compute boards. To achieve this, two fundamental strategies are employed: Scale Up (adding more powerful hardware) and Scale Out (expanding the number of interconnected systems).
What Is Scale Up?
In computing terminology, “scale” refers to the expansion of system resources. This concept is particularly familiar to those with experience in cloud computing.
Scale Up, also known as vertical scaling, involves increasing the resources of a single node—such as adding more computing power, memory, or AI accelerator cards to a server.
Scale Out, or horizontal scaling, means expanding a system by adding more nodes—connecting multiple servers or devices through a network.
In cloud computing, the concepts also extend to Scale Down (reducing resources of a node) and Scale In (reducing the number of nodes).
Earlier, we discussed how inserting more AI accelerator cards into a server is a form of Scale Up, with each server acting as a single node. By interconnecting multiple servers via high-speed networks, we achieve Scale Out.
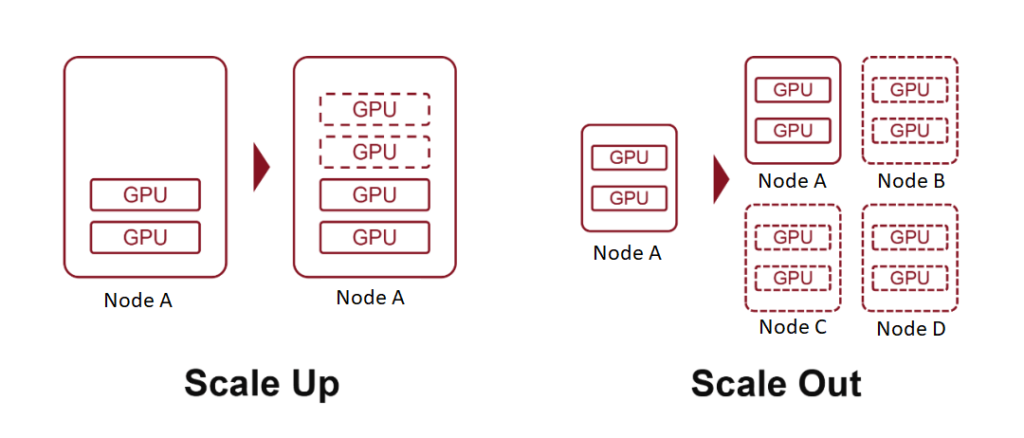
The main distinction between these two lies in the communication bandwidth between AI chips:
Scale Up involves internal node connections, offering higher speed, lower latency, and stronger performance.
Historically, internal communications within computers relied on PCIe—a protocol developed in the late 20th century during the rise of personal computing. Although PCIe has undergone several upgrades, its evolution has been slow and insufficient for modern AI workloads.
To overcome these limitations, NVIDIA introduced its proprietary NVLINK bus protocol in 2014, enabling point-to-point communication between GPUs. NVLINK delivers far greater speed and substantially lower latency compared to PCIe.
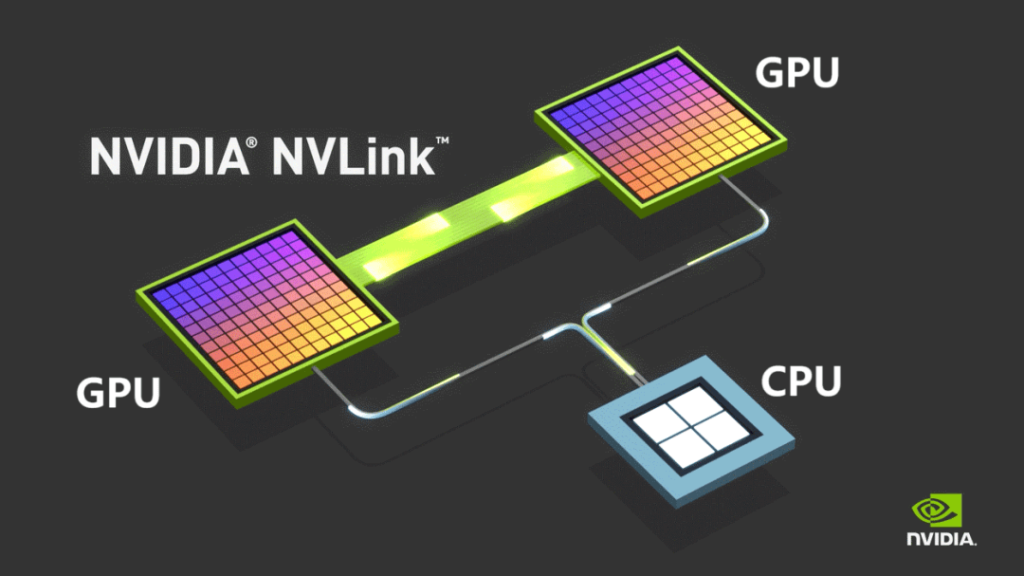
Initially used only for intra-machine communication, NVIDIA released NVSwitch in 2022—an independent switching chip designed to enable high-speed GPU connectivity across servers. This innovation redefined the concept of a node, allowing multiple servers and networking devices to work collectively within a High Bandwidth Domain (HBD).
NVIDIA refers to such systems, where more than 16 GPUs are interconnected with ultra-high bandwidth, as supernodes.
Over time, NVLINK has progressed to its fifth generation. Each GPU now supports up to 18 NVLINK connections, and the Blackwell GPU’s total bandwidth has reached 1800 GB/s, vastly exceeding PCIe Gen6.
In March 2024, NVIDIA unveiled the NVL72, a liquid-cooled cabinet that integrates 36 Grace CPUs and 72 Blackwell GPUs. It delivers up to 720 PFLOPS of training performance or 1440 PFLOPS of inference performance, further solidifying NVIDIA’s leadership in the AI computing ecosystem—powered by its popular GPU hardware and the CUDA software stack.

As AI adoption expanded, numerous other companies developed their own AI chips. Due to NVLINK’s proprietary nature, these companies had to devise alternative compute cluster architectures.
AMD, a major competitor, introduced UA LINK.
Domestic players in China—such as Tencent, Alibaba, and China Mobile—spearheaded open initiatives like ETH-X, ALS, and OISA.
Another noteworthy advancement is Huawei’s UB (Unified Bus) protocol, a proprietary technology developed to support the Ascend AI chip ecosystem. Huawei’s chips, such as the Ascend 910C, have evolved considerably in recent years.
In April 2025, Huawei launched the CloudMatrix384 supernode, integrating 384 Ascend 910C AI accelerator cards and achieving up to 300 PFLOPS of dense BF16 compute performance—nearly double that of NVIDIA’s GB200 NVL72 system.
CloudMatrix384 leverages UB technology and consists of three distinct networking planes:
- UB Plane
- RDMA (Remote Direct Memory Access) Plane
- VPC (Virtual Private Cloud) Plane
These complementary planes enable exceptional inter-card communication and significantly enhance overall computational power within the supernode.
Due to space limitations, we’ll explore the technical details of these planes separately in a future discussion.
One final note: In response to the growing pressure from open standards, NVIDIA recently announced its NVLink Fusion initiative, offering access to its NVLink technology to eight global partners. This move aims to help them build customized AI systems via multi-chip interconnectivity. However, according to some media reports, key NVLink components remain proprietary, suggesting NVIDIA is still somewhat reserved in its openness.
What Is Scale Out?
Scale Out refers to the horizontal expansion of computing systems and closely resembles traditional data communication networks. Technologies commonly used to connect conventional servers—such as fat-tree architecture, spine-leaf network topology, TCP/IP protocols, and Ethernet—form the foundational basis of Scale Out infrastructure.
Evolving for AI Demands
With the growing demands of AI workloads, traditional networking technologies have required substantial enhancements to meet performance criteria. Currently, the two dominant network technologies for Scale Out are:
- InfiniBand (IB)
- RoCEv2 (RDMA over Converged Ethernet version 2)
Both are based on the RDMA (Remote Direct Memory Access) protocol, providing higher data transfer rates, lower latency, and superior load-balancing capabilities compared to traditional Ethernet.
InfiniBand vs RoCEv2
- InfiniBand was originally designed to replace PCIe for interconnect purposes. Although its adoption fluctuated over time, it was ultimately acquired by NVIDIA through its purchase of Mellanox. Today, IB is proprietary to NVIDIA and plays a key role in their compute infrastructure. While it offers excellent performance, it comes with a high price tag.
- RoCEv2, on the other hand, is an open standard developed to counterbalance IB’s market dominance. It merges RDMA with conventional Ethernet, offering cost efficiency and steadily narrowing the performance gap with InfiniBand.
Unlike the fragmented standards seen in Scale Up implementations, Scale Out is largely unified under RoCEv2, due to its emphasis on inter-node compatibility, rather than tight coupling with chip-level products.
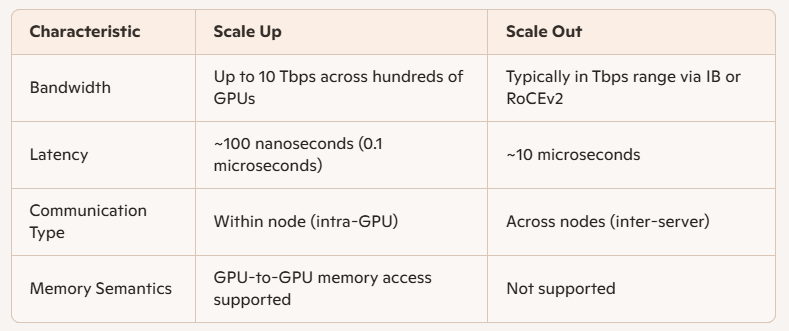
Performance Differences: Scale Up vs Scale Out
The primary technical differences between Scale Up and Scale Out lie in bandwidth and latency:

Application in AI Training
AI training involves multiple forms of parallel computation:
- TP (Tensor Parallelism)
- EP (Expert Parallelism)
- PP (Pipeline Parallelism)
- DP (Data Parallelism)
Generally:
- PP and DP involve smaller communication loads and are handled via Scale Out.
- TP and EP, which require heavier data exchange, are best supported by Scale Up within supernodes.
Advantages of Scale Up in Network Design
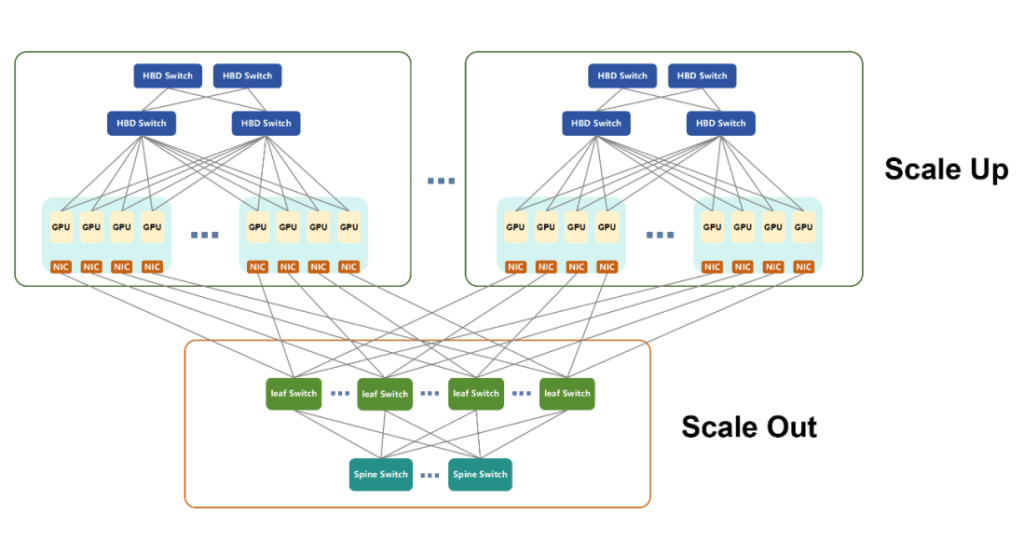
Supernodes—built on Scale Up architecture—are connected through high-speed internal buses and provide efficient support for parallel computing, GPU parameter exchange, and data synchronization. They also enable direct memory access between GPUs, a capability Scale Out lacks.
From a deployment and maintenance standpoint:
- Larger High Bandwidth Domains (HBDs) simplify the Scale Out network.
- Pre-integrated Scale Up systems reduce complexity, shorten deployment time, and ease long-term operations.
However, Scale Up cannot expand infinitely due to cost constraints. The optimal scale depends on specific usage scenarios.
A Unified Future?
Ultimately, Scale Up and Scale Out represent a trade-off between performance and cost. As technology evolves, the boundary between the two is expected to blur. Emerging open Scale Up standards like ETH-X, based on Ethernet, offer promising performance metrics:
- Switch chip capacity: Up to 51.2 Tbps
- SerDes speed: Up to 112 Gbps
- Latency: As low as 200 nanoseconds
Since Scale Out also utilizes Ethernet, this convergence hints at a unified architecture, where a single standard may underpin both expansion models in future computing ecosystems.
Trends in AI Compute Cluster Development
As the field of artificial intelligence (AI) continues to expand, AI compute clusters are evolving along several key trajectories:
Geographical Distribution of Physical Infrastructure
AI clusters are scaling toward configurations containing tens or even hundreds of thousands of AI cards. For instance:
- NVIDIA’s NVL72 rack integrates 72 chips.
- Huawei’s CM384 deploys 384 chips across 16 racks.
To build a 100,000-card cluster using Huawei’s CM384 architecture would require 432 CM384 units—equaling 165,888 chips and 6,912 racks. Such a scale far exceeds the physical and electrical capacity of a single data center.
As a result, the industry is actively exploring distributed data center deployments that can operate as a unified AI compute cluster. These architectures rely heavily on advanced data center interconnect (DCI) optical communication technologies, which must support long-distance, high-bandwidth, and low-latency transmission. Innovations such as hollow-core optical fiber are expected to accelerate in adoption.
Customization of Node Architecture
The traditional approach to building AI clusters often centered on maximizing the number of AI chips. However, there is a growing emphasis on deep architectural design, beyond sheer volume.
Emerging trends include the pooling of computational resources—such as GPUs, NPUs, CPUs, memory, and storage—to create highly adaptable clusters tailored to the requirements of large-scale AI models, including architectures like Mixture of Experts (MoE).
In short, delivering bare chips is no longer sufficient. Tailored, scenario-specific designs are increasingly necessary to ensure optimal performance and efficiency.
Intelligent Operations and Maintenance
Training large-scale AI models is notoriously error-prone, with failures potentially occurring within mere hours. Each failure necessitates retraining, prolonging development timelines and increasing operational costs.
To mitigate these risks, organizations are prioritizing system reliability and stability by incorporating intelligent operation and maintenance tools. These systems can:
- Predict potential faults
- Identify suboptimal or deteriorating hardware
- Enable proactive component replacement
Such approaches significantly reduce failure rates and downtime, thereby bolstering cluster stability and effectively enhancing overall computational output.
Energy Efficiency and Sustainability
AI computation demands massive energy consumption, prompting leading vendors to explore strategies for reducing power usage and increasing reliance on renewable energy sources.
This push for green compute clusters aligns with broader sustainability initiatives, such as China’s “East Data, West Compute” strategy, which aims to optimize energy allocation and promote long-term ecological development of AI infrastructure.
Related Products:
-
 QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$149.00
QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$149.00
-
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$400.00
-
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$450.00
-
QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$500.00
-
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optical Transceiver Module
$580.00
-
QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC Optical Transceiver Module
$600.00
-
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Silicon photonics Optical Transceiver Module
$650.00
-
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Silicon photonics Optical Transceiver Module
$750.00
-
QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Optical Transceiver Module
$900.00
-
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$450.00
-
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$850.00
-
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00















