
As artificial intelligence (AI) drives exponential growth in data volumes and model complexity, distributed computing leverages interconnected nodes to accelerate training processes. Data center switches play a pivotal role in ensuring timely message delivery across nodes, particularly in large-scale data centers where tail latency is critical for handling competitive workloads. Moreover, the scalability and ability to manage numerous nodes are essential for training large AI models and processing massive datasets, making data center switches indispensable for efficient network connectivity and data transmission. According to IDC, the global switch market reached $308 billion in 2022, reflecting a 17% year-over-year growth, with a projected compound annual growth rate (CAGR) of 4.6% from 2022 to 2027. In China, the switch market was valued at $59.1 billion, growing by 9.5%, with an anticipated CAGR of 7%-9% over the next five years, outpacing global growth.
Main Classifications of Data Center Switches
Data center switches can be categorized based on various criteria, including application scenarios, network layers, management types, OSI network models, port speeds, and physical structures. The classifications include:
- By Application Scenario: Campus switches, data center switches
- By Network Layer: Access switches, aggregation switches, core switches
- By Management Type: Unmanaged switches, web-managed switches, fully managed switches
- By OSI Network Model: Layer 2 switches, Layer 3 switches
- By Port Speed: Fast Ethernet switches, Gigabit Ethernet switches, 10-Gigabit switches, multi-rate switches
- By Physical Structure: Fixed (box) switches, modular (chassis) switches
Switch Chips and Key Performance Metrics
Ethernet data center switches comprise critical components such as chips, PCBs, optical modules, connectors, passive components, enclosures, power supplies, and fans. The core components include Ethernet switch chips and CPUs, with additional elements like PHYs and CPLD/FPGAs. The Ethernet switch chip, designed specifically for network optimization, handles data processing and packet forwarding, featuring complex logic pathways to ensure robust data handling. The CPU manages logins and protocol interactions, while the PHY processes physical-layer data.
The performance of data center switches hinges on key metrics such as backplane bandwidth, packet forwarding rate, switching capacity, port speed, and port density. Backplane bandwidth indicates a switch’s data throughput capacity, with higher values signifying better performance under heavy loads. For non-blocking forwarding, the backplane bandwidth must be at least equal to the switching capacity (calculated as port count × port speed × 2 in full-duplex mode). High-end switches with no-backplane designs rely on packet forwarding rates. Higher port speeds indicate superior processing capabilities for high-traffic scenarios, while greater port density supports larger network scales by connecting more devices.
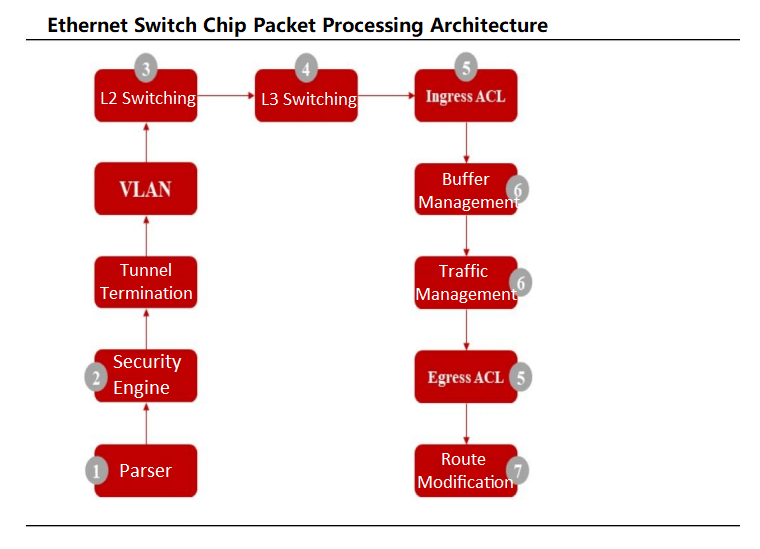
Ethernet switch chips function as specialized ASICs for data center switches, often integrating MAC controllers and PHY chips. Data packets enter via physical ports, where the chip’s parser analyzes fields for flow classification. After security checks, packets undergo Layer 2 switching or Layer 3 routing, with the flow classifier directing packets to prioritized queues based on 802.1P or DSCP standards. Schedulers then manage queue prioritization using algorithms like Weighted Round Robin (WRR) before transmitting packets.

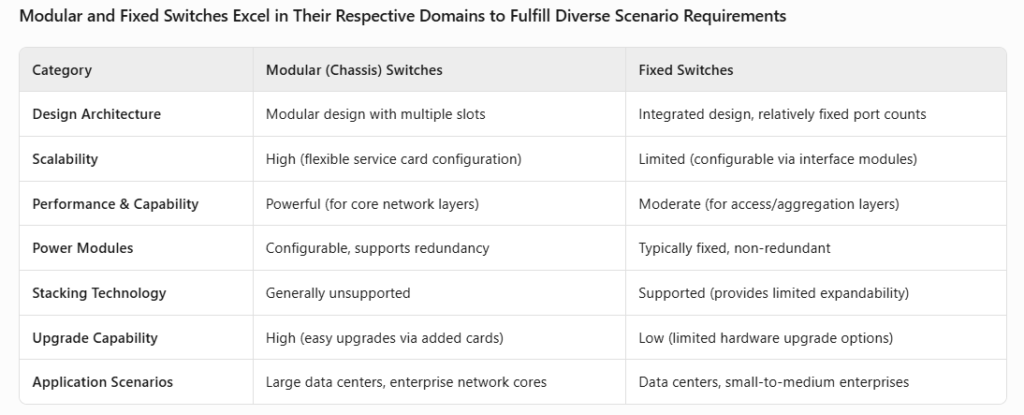
Physically, data center switches are either chassis-based or fixed. Chassis switches feature a modular design with slots for interface, control, and switching modules, offering high flexibility and scalability. Fixed switches have integrated designs with fixed port configurations, though some support modular interfaces. The primary differences lie in internal architecture and application scenarios (OSI layer usage).
Evolution and Technological Advancements in Data Center Switches
From OEO to OOO: All-Optical Switches for AI Workloads
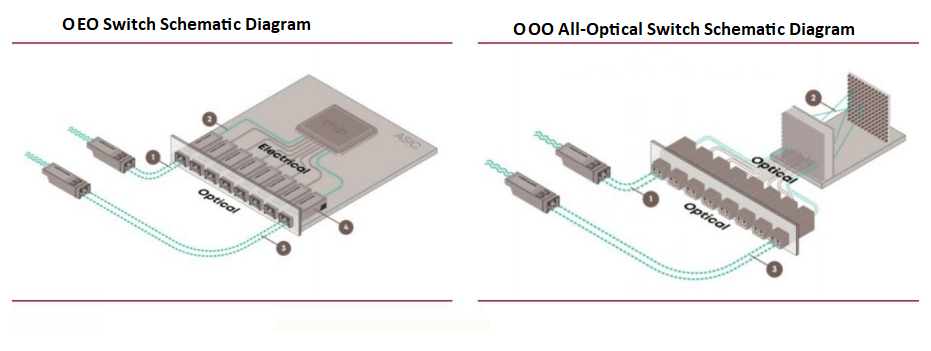
Current data center switches, based on ASIC chips, operate as Optical-to-Electrical-to-Optical (OEO) packet-circuit switches, relying on ASIC chips for core packet forwarding. These switches require optical-to-electrical conversions for signal transmission. However, all-optical (OOO) switches are emerging to meet AI-driven computational demands, reducing conversion overhead and enhancing efficiency.
NVIDIA Executive Joins Lightmatter to Advance All-Optical Switching
In July 2024, NVIDIA Vice President Simona Jankowski joined Lightmatter as CFO, signaling the company’s focus on optical interconnects. Valued at $4.4 billion, Lightmatter’s Passage technology leverages photonics for chip interconnects, using waveguides instead of fiber optics to deliver high-bandwidth, parallel data transmission for diverse computing cores, significantly boosting AI network performance.
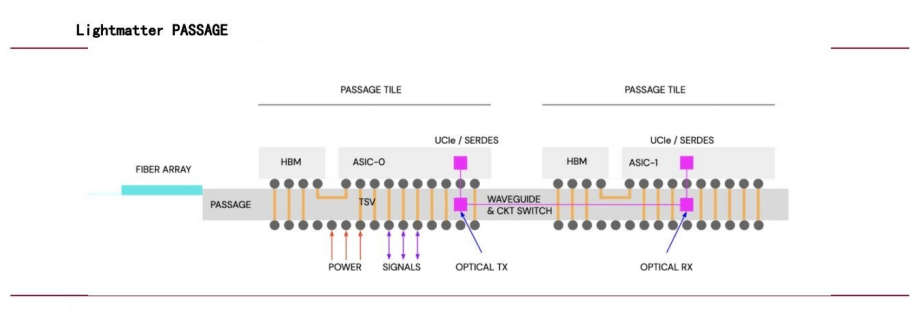
Google’s Large-Scale Deployment of OCS Switches
Google’s data center networks emphasize software-defined networking (SDN), Clos topology, and commodity switch chips. The Clos topology, a non-blocking multi-stage architecture built from smaller radix chips, supports scalable networks critical for AI workloads.
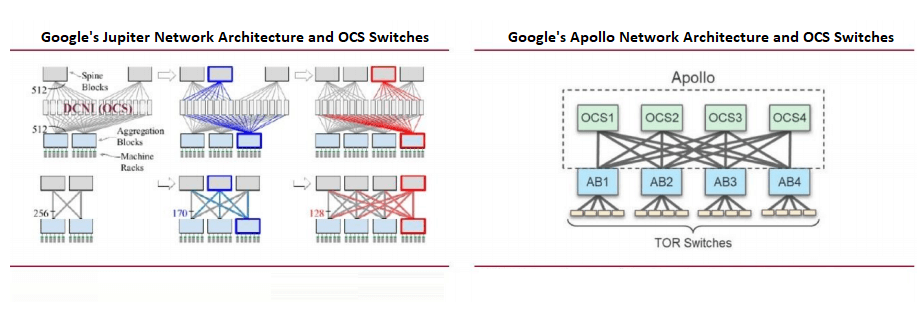
Google pioneered the large-scale use of Optical Circuit Switches (OCS) in its Jupiter architecture, integrating MEMS-based OCS to reduce optical-to-electrical conversions. At OFC 2023, Google introduced its Apollo project, replacing the spine layer’s Ethernet Packet Switches (EPS) with OCS for enhanced efficiency.
Key Technologies and Standards for Data Center Switches
- RDMA: Enabling Low-Latency, High-Throughput Communication
Remote Direct Memory Access (RDMA) enables high-throughput, low-latency network communication by bypassing operating system involvement. Unlike traditional TCP/IP, which requires multiple CPU-intensive data copies, RDMA directly transfers data between computer memories. In data center switches, RDMA is implemented via InfiniBand and RoCE (RDMA over Converged Ethernet), with InfiniBand and RoCEv2 being the dominant solutions for AI data centers (AIDCs).
- InfiniBand: Designed for high-performance computing (HPC) and data centers, InfiniBand offers high bandwidth, low latency, quality of service (QoS), and scalability. Its channelized architecture, RDMA support, and switched network design make it ideal for data-intensive applications. However, its high cost limits its adoption to specialized HPC environments.
Comparison of InfiniBand and RoCE
| Category | InfiniBand | RoCE |
| Design Philosophy | Designed with RDMA in mind, redefining physical link and network layers | Implements RDMA over Ethernet (RoCEv1: link layer; RoCEv2: transport layer) |
| Key Technology | – InfiniBand network protocol and architecture – Verbs programming interface | – UDP/IP-based implementation – Hardware offload (RoCEv2) to reduce CPU utilization – IP routing for scalability |
| Advantages | – Higher bandwidth and lower latency – Credit-based flow control ensuring data stability | – Cost-effective – Compatible with standard Ethernet – Supports large-scale deployment |
| Disadvantages | – Limited scalability – Requires specialized NICs and switches | – Implementation challenges remain – Requires RoCE-capable NICs |
| Cost | Higher (dedicated IB NICs/switches; cabling costs exceed Ethernet) | Lower (utilizes standard Ethernet switches; budget-friendly) |
| Use Cases | HPC, large-scale parallel processing, AI training | Data center internal communication, cloud service providers |
| Major Suppliers | NVIDIA (primary supplier) | Multi-vendor support (e.g., Huawei, H3C, Inspur, Ruijie in China) |
- RoCE: RoCEv2, built on Ethernet’s UDP layer, introduces IP protocols for scalability and uses hardware offloading to reduce CPU usage. While slightly less performant than InfiniBand, RoCEv2 is cost-effective, making it suitable for data center communications and cloud services.
RDMA Reduces Inter-Card Communication Latency
In distributed AI training, reducing inter-card communication latency is critical for improving acceleration ratios. The total compute time includes single-card computation and inter-card communication, with RDMA (via InfiniBand or RoCEv2) minimizing latency by bypassing kernel protocol stacks. Lab tests show RDMA reducing end-to-end latency from 50µs (TCP/IP) to 5µs (RoCEv2) or 2µs (InfiniBand) in single-hop scenarios.
Ethernet vs. InfiniBand: Strengths and Trends
- InfiniBand vs. RoCEv2: InfiniBand supports large-scale GPU clusters (up to 10,000 cards) with minimal performance degradation and lower latency than RoCEv2, but comes at a higher cost, with NVIDIA dominating over 70% of the market. RoCEv2 offers broader compatibility and lower costs, supporting both RDMA and traditional Ethernet networks, with vendors like H3C and Huawei leading the market.
- Ethernet’s Growing Momentum: According to Dell’Oro Group, switch spending for AI backend networks will exceed $100 billion from 2025 to 2029. Ethernet is gaining traction in large-scale AI clusters, with deployments like xAI’s Colossus adopting Ethernet. By 2027, Ethernet is expected to surpass InfiniBand in market share.
- NVIDIA’s Ethernet Push: In July 2023, the Ultra Ethernet Consortium (UEC), including AMD, Arista, Broadcom, Cisco, Meta, and Microsoft, was formed to develop Ethernet-based AI networking solutions. NVIDIA joined in July 2024, with its Spectrum-X platform boosting AI network performance by 1.6x compared to traditional Ethernet. NVIDIA plans annual Spectrum-X updates to further enhance AI Ethernet performance.
Related Products:
-
 QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$149.00
QSFP-DD-400G-SR8 400G QSFP-DD SR8 PAM4 850nm 100m MTP/MPO OM3 FEC Optical Transceiver Module
$149.00
-
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$400.00
-
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$450.00
-
QSFP-DD-400G-FR4 400G QSFP-DD FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$500.00
-
QSFP-DD-400G-XDR4 400G QSFP-DD XDR4 PAM4 1310nm 2km MTP/MPO-12 SMF FEC Optical Transceiver Module
$580.00
-
QSFP-DD-400G-LR4 400G QSFP-DD LR4 PAM4 CWDM4 10km LC SMF FEC Optical Transceiver Module
$600.00
-
QDD-4X100G-FR-Si QSFP-DD 4 x100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS3.0 Silicon photonics Optical Transceiver Module
$650.00
-
QDD-4X100G-FR-4Si QSFP-DD 4 x 100G FR PAM4 1310nm 2km MTP/MPO-12 SMF FEC CMIS4.0 Silicon photonics Optical Transceiver Module
$750.00
-
QSFP-DD-400G-SR4.2 400Gb/s QSFP-DD SR4 BiDi PAM4 850nm/910nm 100m/150m OM4/OM5 MMF MPO-12 FEC Optical Transceiver Module
$900.00
-
Arista Q112-400G-SR4 Compatible 400G QSFP112 SR4 PAM4 850nm 100m MTP/MPO-12 OM3 FEC Optical Transceiver Module
$450.00
-
Cisco Q112-400G-DR4 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
OSFP-800G-DR8D-FLT 800G-DR8 OSFP Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
OSFP-800G-SR8D-FLT OSFP 8x100G SR8 Flat Top PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
OSFP-800G-SR8D OSFP 8x100G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
OSFP-800G-DR8D 800G-DR8 OSFP PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$850.00
-
OSFP-800G-2FR4L OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00















