Selecting the right networking technology is critical for optimizing data center performance, especially for high-performance computing (HPC), artificial intelligence (AI), and enterprise storage. RoCEv2 (RDMA over Converged Ethernet, version 2) and InfiniBand are two leading solutions, each offering unique advantages in speed, latency, and scalability. RoCEv2 leverages standard Ethernet infrastructure for cost-effective, low-latency RDMA, while InfiniBand provides a specialized, high-performance fabric. This guide compares RoCEv2 and InfiniBand, helping IT professionals make informed decisions based on performance, cost, and compatibility needs. Whether you’re building an HPC cluster or upgrading your data center, understanding RoCEv2 and InfiniBand is key to achieving optimal network efficiency.
Ultra-high bandwidth, ultra-low latency, and ultra-high reliability are the network requirements for large model training.
For many years, TCP/IP protocol has been the pillar of internet communication, but for AI networks, TCP/IP has some fatal drawbacks. TCP/IP protocol has high latency, usually around tens of microseconds, and also causes serious CPU load. RDMA can directly access memory data through the network interface, without the intervention of the operating system kernel. This allows high-throughput, low-latency network communication, especially suitable for use in large-scale parallel computer clusters.
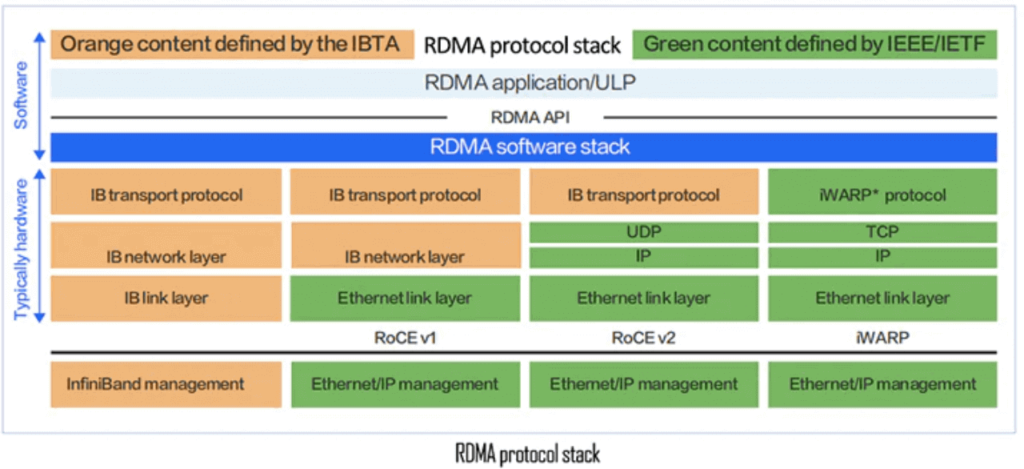
InfiniBand, RoCEv1, RoCEv2, and iWARP are the four implementations of RDMA technology. Yet, RoCEv1 is no longer used and iWARP is uncommon. The prevalent network solutions in the industry are InfiniBand and RoCEv2.
What Is RoCEv2?
RoCEv2 (RDMA over Converged Ethernet, version 2) is an advanced network protocol that enables Remote Direct Memory Access (RDMA) over standard Ethernet networks with IP-based routing. Unlike its predecessor, RoCE v1, which operates within a single Layer 2 domain, RoCEv2 uses UDP encapsulation to support routable, scalable networks, making it ideal for large-scale data centers and cloud environments. By allowing direct memory-to-memory data transfers without CPU involvement, RoCEv2 achieves sub-microsecond latency and high throughput (up to 400 Gbps), rivaling InfiniBand’s performance. It relies on lossless Ethernet features like Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) to ensure reliable data delivery.
Key Features of RoCEv2:
- Routable RDMA: Supports IP-based routing for cross-subnet communication.
- Ultra-Low Latency: Sub-microsecond latency for real-time applications.
- High Bandwidth: Up to 400 Gbps per port for data-intensive workloads.
- Ethernet Compatibility: Works with standard Ethernet switches, reducing costs.
Benefits of Choosing RoCEv2
RoCEv2 offers a compelling combination of performance and affordability, making it a top choice for data centers and enterprises. Key benefits include:
Ultra-Low Latency: RoCEv2 achieves sub-microsecond latency, ideal for AI, high-frequency trading, and real-time analytics.
High Throughput: Supports up to 400 Gbps, ensuring no bottlenecks in data-intensive applications.
Cost-Effectiveness: Leverages existing Ethernet switches and cables, reducing infrastructure costs compared to InfiniBand.
Scalability: IP-based routing enables RoCEv2 to scale across large, routable networks, perfect for cloud and enterprise environments.
CPU Offloading: RDMA bypasses the CPU, freeing resources for compute-intensive tasks.
Lossless Performance: With PFC and ECN, RoCEv2 ensures reliable data delivery in congested networks.
Flexibility: Compatible with standard Ethernet, allowing integration with existing infrastructure.
These advantages make RoCEv2 a versatile solution for organizations seeking high-performance networking without the cost of proprietary systems.
What are the Network Requirements for HPC/AI Workloads?
Most data centers today use a two-tier network architecture, while AI clusters are supercomputers built to execute complex large-scale AI tasks. Computer workloads run in parallel on multiple GPUs, requiring high utilization. Therefore, compared to traditional data center networks, AI data center networks face additional complexity:
- Parallel computing: AI workloads are a unified infrastructure of multiple machines running the same application/computing task;
- Scale: The scale of HPC/AI tasks can reach thousands of computing engines (such as GPUs, CPUs, FPGAs, etc.);
- Task types: Different tasks vary in size, running duration, data set size and quantity to consider, answer type to generate, and different languages used to code the application and the type of hardware it runs on, which all cause the traffic patterns within the network built to run HPC/AI workloads to constantly change;
- Lossless: In traditional data centers, lost messages are retransmitted, while in AI workloads, lost messages mean that the entire computation is either wrong or stuck. Therefore, AI data centers need a lossless network.
- Bandwidth: High-bandwidth traffic needs to run between servers so that applications can access data. In modern deployments, the interface speed of each computing engine for AI or other high-performance computing capabilities reaches 400Gbps.
These complexities pose significant challenges for AI networks, so AI data center networks need to have high bandwidth, low latency, no jitter, no packet loss, and long-term stability.
From TCP/IP to RDMA
For applications such as HPC/AI that require low latency and high I/O concurrency, the existing TCP/IP software and hardware architecture cannot meet the application requirements. Traditional TCP/IP network communication uses the kernel to send messages, which has high data movement and data copying overhead. For example, in a typical IP data transfer, when an application on one computer sends data to an application on another computer, the following operations occur on the receiving end:
- The kernel must receive the data.
- The kernel must determine which application the data belongs to.
- The kernel wakes up the application.
- The kernel waits for the application to perform a system call on the kernel.
- The application copies the data from the kernel memory space to the buffer provided by the application.
This process means that if the host adapter uses direct memory access (DMA), most of the network traffic is copied into the system’s main memory. In addition, the computer performs some context switches to switch between the kernel and the application. These context switches may cause higher CPU load and high traffic while slowing down other tasks.
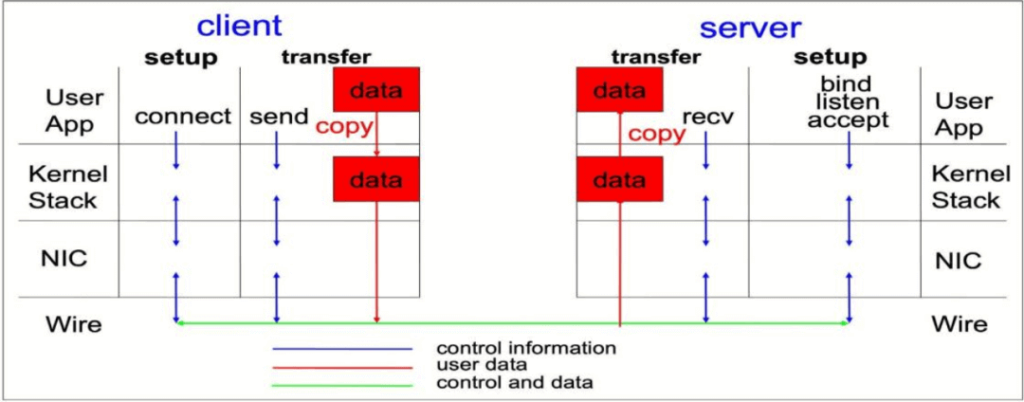
TCP/IP Transmission
Unlike traditional IP communication, RDMA communication bypasses the kernel intervention in the communication process, allowing the host to directly access the memory of another host, reducing CPU overhead. The RDMA protocol enables the host adapter to decide which application should receive it and where to store it in that application’s memory space after the packet enters the network. The host adapter does not send the packet to the kernel for processing and copy it to the user application’s memory, but instead directly puts the packet content into the application buffer.
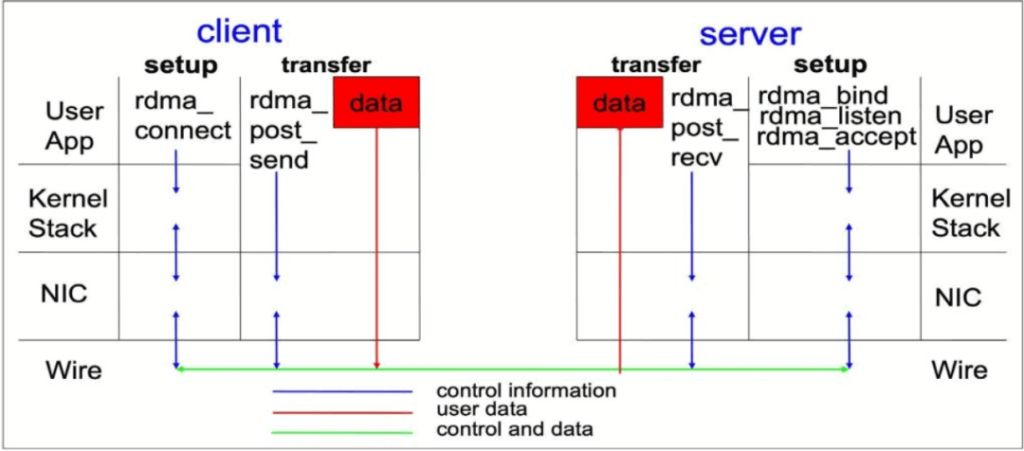
RDMA Transmission
RDMA transmission reduces the number of CPU cycles involved, which helps to improve throughput and performance. In other words, the essence of RDMA is that for large-scale distributed computing and storage scenarios, it allows the network card to bypass the CPU and directly access the memory of the remote server, accelerating the interaction between servers, reducing latency, and using the precious CPU resources for high-value computing and logic control.
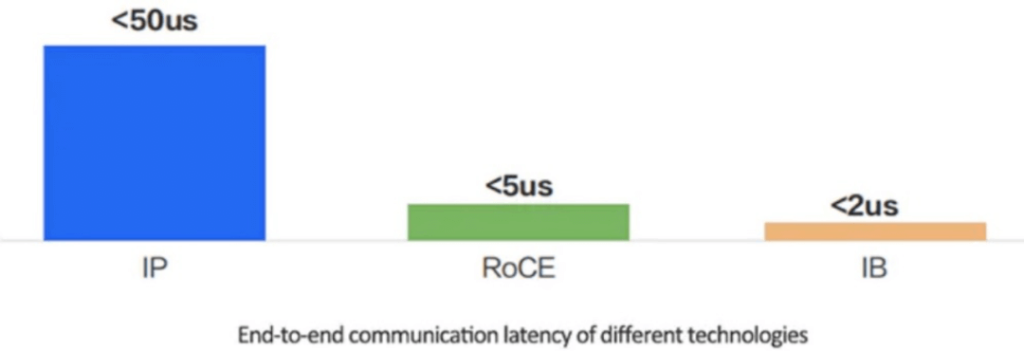
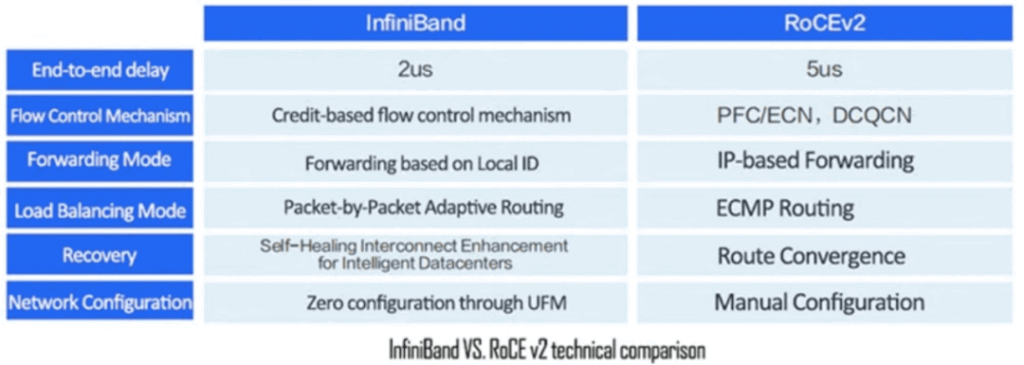
Compared to traditional TCP/IP networks, InfiniBand and RoCEv2 bypass the kernel protocol stack, and the latency performance can be improved by several orders of magnitude. When communication within the same cluster can be achieved in a single hop, experimental tests show that after bypassing the kernel protocol stack, the end-to-end latency at the application layer can be reduced from 50us (TCP/IP) to 5us (RoCE) or 2us (InfiniBand).
An Introduction to InfiniBand Networks
InfiniBand networks use InfiniBand adapters or switches instead of Ethernet to achieve data transmission. The port-to-port latency of a specific type of Ethernet switch is 230 ns, while the latency of an InfiniBand switch with the same number of ports is 100 ns.
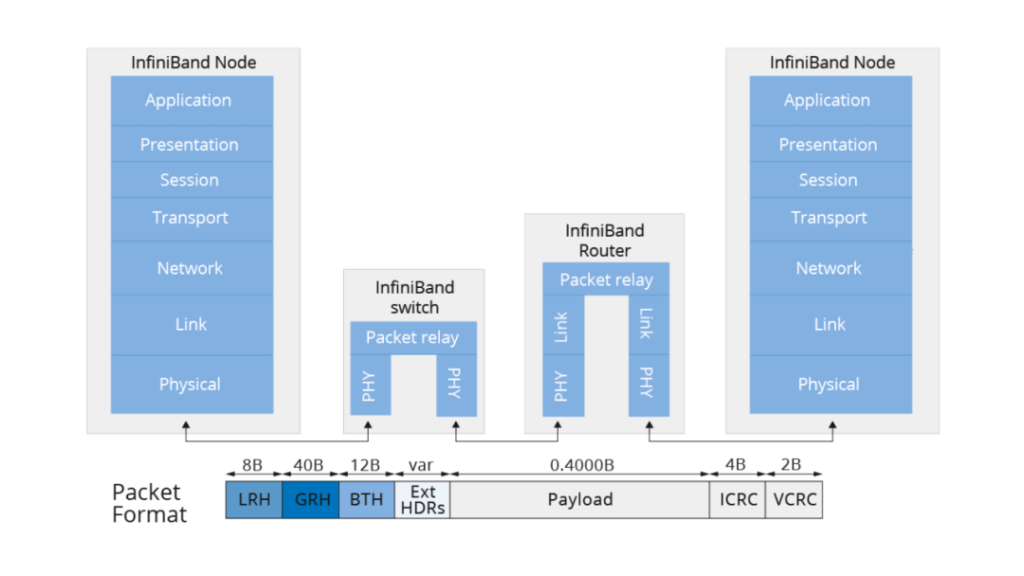
The key components of an InfiniBand network include a subnet manager (SM), an IB network card, an IB switch, and an IB cable. InfiniBand switches do not run any routing protocols, and the forwarding tables of the entire network are calculated and distributed by a centralized subnet manager. In addition to forwarding tables, the SM is also responsible for managing partitions, QoS, and other configurations in the InfiniBand subnet. InfiniBand networks require dedicated cables and optical modules to interconnect switches and connect switches to network cards.
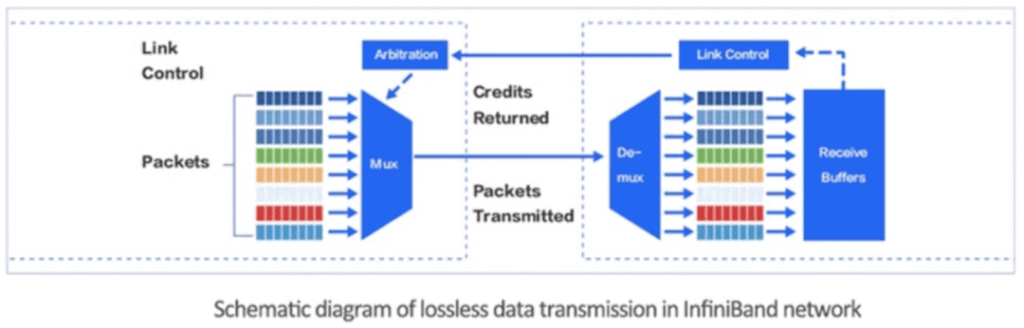
Local Lossless Network
InfiniBand networks use a credit token mechanism to fundamentally avoid buffer overflow and packet loss. The sender only initiates packet transmission after confirming that the receiver has enough credits to accept the corresponding number of packets.
Each link in the InfiniBand network has a predetermined buffer. The sender does not transmit data that exceeds the size of the predetermined buffer available at the receiver. Once the receiver completes forwarding, it releases the buffer and continuously returns the current available predetermined buffer size to the sender. This link-level flow control mechanism ensures that the sender does not send too much data, preventing network buffer overflow and packet loss.
Network Card Expansion Capability
InfiniBand’s adaptive routing is based on per-packet dynamic routing, ensuring optimal network utilization in large-scale deployments. There are many examples of large-scale GPU clusters using InfiniBand networks, such as Baidu Artificial Intelligence Cloud and Microsoft Azure.
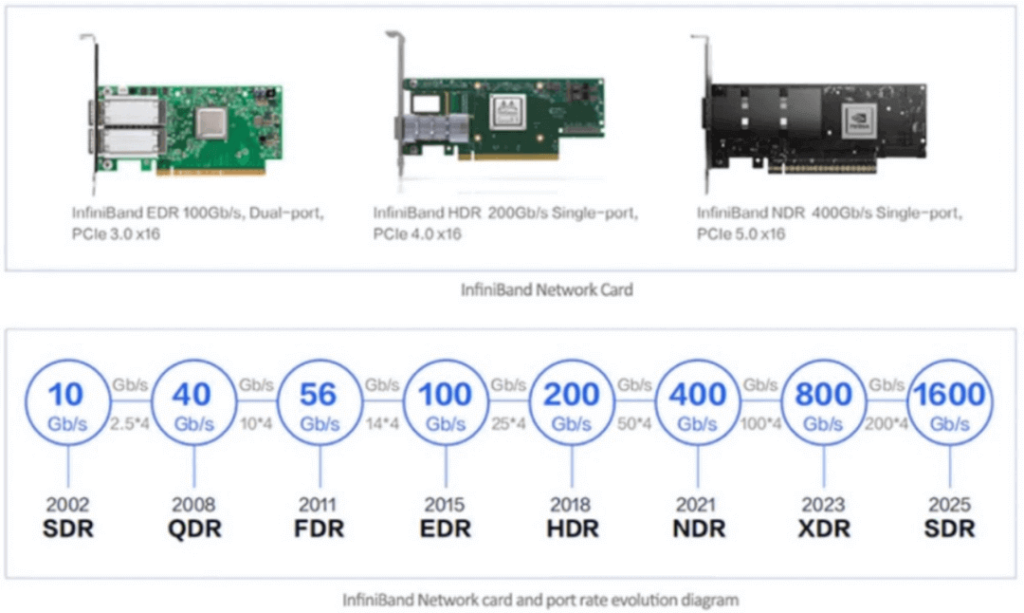
InfiniBand network cards have been rapidly evolving in terms of speed, with 200Gbps HDR already widely deployed commercially, and 400Gbps NDR network cards also starting to be commercially deployed. Currently, there are major InfiniBand network solutions and supporting equipment providers in the market, such as NVIDIA, Intel, Cisco, and HPE. Among them, NVIDIA has the highest market share, exceeding 70%. The following figure shows the commonly used InfiniBand network cards.
An Introduction to RoCEv2 Networks
RoCE implements RDMA functionality over Ethernet, which can bypass TCP/IP and use hardware offloading, thereby reducing CPU utilization. RoCE has two main versions: RoCEv1 and RoCEv2. RoCEv1 is an RDMA protocol implemented over the Ethernet link layer. Switches need to support flow control techniques such as PFC to ensure reliable transmission at the physical layer. RoCEv2 is implemented over the UDP layer of the Ethernet TCP/IP protocol and introduces the IP protocol to solve scalability issues.
RoCEv2 supports RDMA routing over layer 3 Ethernet networks. RoCEv2 replaces the InfiniBand network layer with IP and UDP headers over the Ethernet link layer, which makes it possible to route RoCE between traditional routers based on IP.
InfiniBand networks are, to some extent, centrally managed networks with SM (subnet manager), while RoCEv2 networks are pure distributed networks composed of NICs and switches that support RoCEv1, usually adopting a two-layer architecture.
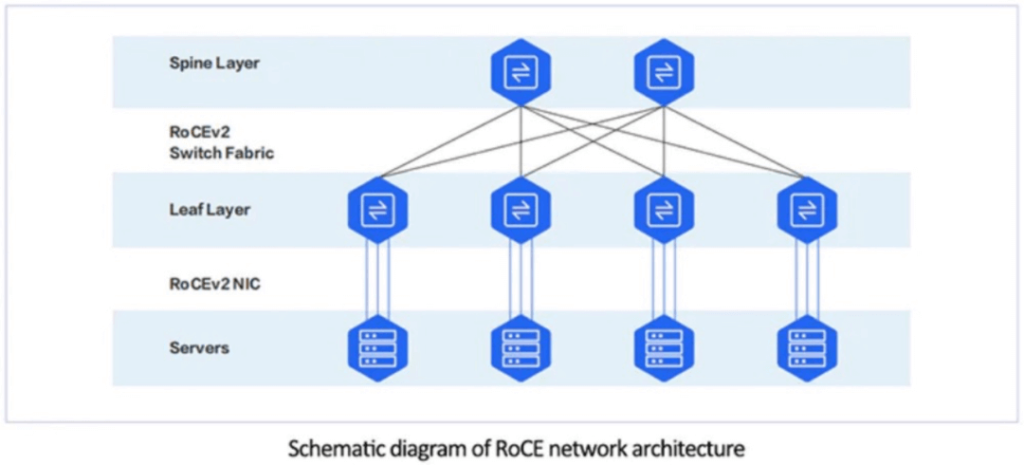
The main suppliers of RoCE network cards are NVIDIA, Intel and Broadcom, etc. PCIe cards are the main form of network cards for data center servers. The port PHY speed of RDMA cards usually starts from 50Gbps, and the currently available commercial network cards can achieve up to 400Gbps of single-port speed.

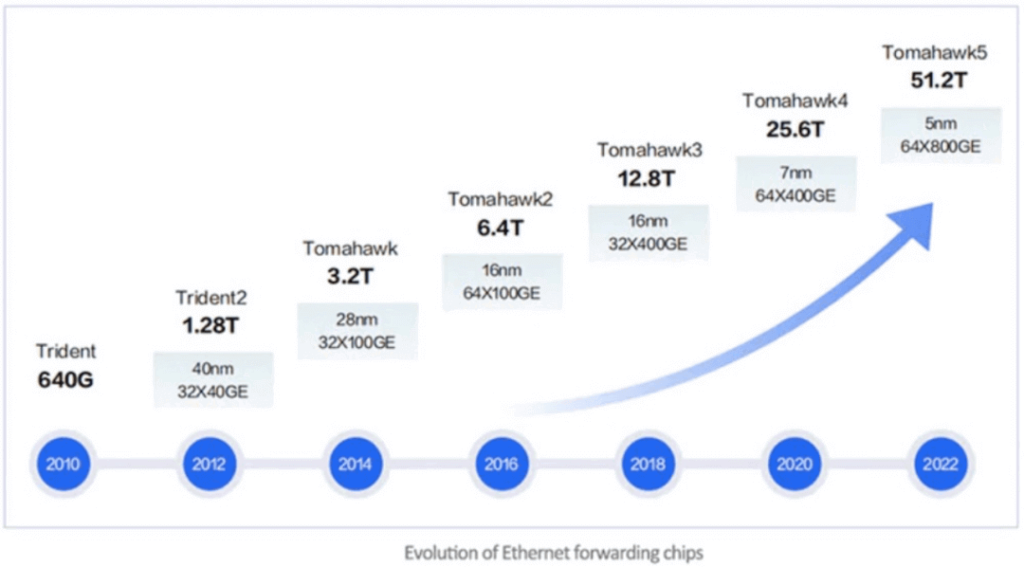
Currently, most data center switches support RDMA flow control technology, which can achieve end-to-end RDMA communication when combined with network cards that support RoCE. The main players in data center switches include Cisco, HPE, Arista, etc. The core of high-performance switches is the forwarding chip they use. Currently on the market, Broadcom’s Tomahawk series chips are widely used in commercial forwarding chips. Among them, the Tomahawk3 series chip is more commonly used in switches, and switches that support the Tomahawk4 series chip are gradually increasing on the market.
InfiniBand vs. RoCE
Compared to InfiniBand, RoCE has greater versatility and relatively lower cost. It can be used not only to build high-performance RDMA networks, but also for traditional Ethernet. However, configuring parameters such as Headroom, PFC (Priority-based Flow Control) and ECN (Explicit Congestion Notification) on switches may be complex. In large-scale deployments, the overall throughput performance of RoCE networks may be slightly lower than InfiniBand networks.
- From a technical perspective, InfiniBand adopts various technologies to improve network forwarding performance, reduce fault recovery time, enhance scalability, and reduce operational complexity.
- In terms of business performance, InfiniBand has lower end-to-end latency than RoCEv2, so networks built on InfiniBand have an advantage in application-level business performance.
- In terms of bandwidth and latency, factors such as congestion and routing affect high-performance network interconnection.
RoCEv2 excels in environments with existing Ethernet infrastructure, offering cost-effective RDMA with scalability across subnets. InfiniBand, however, provides a dedicated, high-performance fabric optimized for HPC and large-scale clusters. For organizations prioritizing compatibility and cost, RoCEv2 is often the better choice, while InfiniBand suits specialized, latency-sensitive applications.
Benefits of Choosing RoCEv2
RoCEv2 offers a compelling combination of performance and affordability, making it a top choice for data centers and enterprises. Key benefits include:
Ultra-Low Latency: RoCEv2 achieves sub-microsecond latency, ideal for AI, high-frequency trading, and real-time analytics.
High Throughput: Supports up to 400 Gbps, ensuring no bottlenecks in data-intensive applications.
Cost-Effectiveness: Leverages existing Ethernet switches and cables, reducing infrastructure costs compared to InfiniBand.
Scalability: IP-based routing enables RoCEv2 to scale across large, routable networks, perfect for cloud and enterprise environments.
CPU Offloading: RDMA bypasses the CPU, freeing resources for compute-intensive tasks.
Lossless Performance: With PFC and ECN, RoCEv2 ensures reliable data delivery in congested networks.
Flexibility: Compatible with standard Ethernet, allowing integration with existing infrastructure.
These advantages make RoCEv2 a versatile solution for organizations seeking high-performance networking without the cost of proprietary systems.
When to Choose RoCEv2 Over InfiniBand
Selecting RoCEv2 over InfiniBand depends on your network requirements and infrastructure. Consider RoCEv2 if:
You Use Ethernet Infrastructure: RoCEv2 integrates seamlessly with existing Ethernet switches, avoiding the need for specialized InfiniBand hardware.
Cost Is a Concern: RoCEv2 reduces upfront costs by leveraging standard Ethernet, offering RDMA at a lower price point.
Scalability Across Subnets Is Needed: RoCEv2’s IP-based routing supports large, routable networks, ideal for cloud and enterprise data centers.
You Need Flexibility: RoCEv2 supports hybrid environments, connecting to Ethernet-based storage or compute resources.
Applications Include AI or Storage: RoCEv2 excels in AI training, NVMe-oF storage, and cloud computing, where Ethernet compatibility is valuable.
Choose InfiniBand for dedicated HPC clusters or environments requiring maximum performance with minimal configuration. For most modern data centers, RoCEv2 offers a balanced solution.
Congestion
InfiniBand uses two different frame relay messages to control congestion: Forward Explicit Congestion Notification (FECN) and Backward Explicit Congestion Notification (BECN). When the network is congested, FECN notifies the receiving device, while BECN notifies the sending device. InfiniBand combines FECN and BECN with an adaptive marking rate to reduce congestion. It provides coarse-grained congestion control.
Congestion control on RoCE uses Explicit Congestion Notification (ECN), which is an extension of IP and TCP that enables endpoint network congestion notification without dropping packets. ECN places a mark on the IP header to tell the sender that there is congestion. For non-ECN congestion communication, lost packets need to be retransmitted. ECN reduces packet loss caused by TCP connection congestion, avoiding retransmission. Fewer retransmissions can reduce latency and jitter, thus providing better transaction and throughput performance. ECN also provides coarse-grained congestion control, which has no obvious advantage over InfiniBand.
Routing
When there is congestion in the network, adaptive routing sends devices through alternative routes to alleviate congestion and speed up transmission. RoCE v2 runs on top of IP. IP has been routable for decades through advanced routing algorithms, and now it can predict congested routes with AI machine learning and automatically send packets through faster routes. In terms of routing, Ethernet and RoCE v2 have significant advantages.
However, InfiniBand and RoCE do not do much to deal with tail latency. Tail latency is very important for the synchronization of HPC message applications.
UEC Plans to Define a New Transport Protocol
In addition to InfiniBand and RoCE, other protocols have been proposed by the industry.
On July 19, the Ultra Ethernet Consortium (UEC) was officially established. UEC’s goal is to go beyond the existing Ethernet capabilities and provide a high-performance, distributed, and lossless transport layer optimized for high-performance computing and artificial intelligence. UEC’s founding members include AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta, and Microsoft, all of whom have decades of experience in networking, artificial intelligence, cloud, and large-scale high-performance computing deployments.

UEC believes that RDMA, which was defined decades ago, is outdated in the demanding AI/ML network traffic. RDMA transfers data in large blocks of traffic, which can cause link imbalance and overload. It is time to start building a modern transport protocol that supports RDMA for emerging applications.
It is reported that the UEC transport protocol is under development, aiming to provide better Ethernet transport than the current RDMA (still supporting RDMA), while retaining the advantages of Ethernet/IP and providing the performance required by AI and HPC applications. UEC transport is a new form of near-transport layer that has some semantic adjustments, congestion notification protocol, and enhanced security features. UEC will provide more flexible transport that does not require a lossless network, allowing many-to-many artificial intelligence workloads to require multipath and out-of-order packet transmission and other features.
More Enterprise Power
As the HPC/AI network continues to evolve, more and more enterprises are launching their own network protocols or solutions to meet their specific needs.
Tencent Cloud uses its self-developed Starlink RDMA network in its Starlink network, which allows GPUs to communicate directly with each other, saving CPU resources and improving the overall performance and efficiency of computing nodes. Through its self-developed end-to-end collaborative protocol TiTa, Starlink network can achieve 90% load 0 packet loss. TiTa protocol embeds a congestion control algorithm, which can monitor the network status in real-time and optimize communication, making data transmission smoother and latency lower.
Alibaba Cloud Panjiu PredFabric uses its self-developed Solar-RDMA high-speed network protocol, which allows processors to access the memory of any other server through load/store instructions, which is very suitable for the interactive form of neural networks within deep learning models. Compared with the traditional mode, the fault self-healing time and tail latency can be reduced by 90%.
Huawei’s hyper-converged data center network uses its original iLossless intelligent lossless algorithm, which cooperates with three key technologies of traffic control technology, congestion control technology, and intelligent lossless storage network technology to prevent PFC deadlock from occurring in advance, alleviate/release congestion, and achieve fast control of hosts, thus building a lossless Ethernet network and solving the problem of congestion packet loss in traditional Ethernet networks.
The growing market demand is the fundamental driving force for technological development. According to IDC data, AI infrastructure construction investment will reach 154 billion US dollars in 2023 and increase to 300 billion US dollars by 2026. In 2022, the AI network market has reached 2 billion US dollars, of which InfiniBand contributed 75% of the revenue.
When comparing InfiniBand and RoCE, we can see that both have their own advantages and application scenarios. InfiniBand performs well in the field of high-performance computing, providing excellent performance, low latency, and scalability. RoCE is easier to integrate into existing Ethernet infrastructure and has a lower cost. The emerging transport protocols represented by UEC also represent the continuous development and innovation of technology. Only by adapting to the changing needs can we maintain core competitiveness.
Related Products:
-
 NVIDIA(Mellanox) MMA1B00-E100 Compatible 100G InfiniBand EDR QSFP28 SR4 850nm 100m MTP/MPO MMF DDM Transceiver Module
$40.00
NVIDIA(Mellanox) MMA1B00-E100 Compatible 100G InfiniBand EDR QSFP28 SR4 850nm 100m MTP/MPO MMF DDM Transceiver Module
$40.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA(Mellanox) MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MFP7E20-N050 Compatible 50m (164ft) 8 Fibers Low Insertion Loss Female to Female MPO12 to 2xMPO12 Polarity B APC to APC LSZH Multimode OM4 50/125
$145.00
-
NVIDIA MFP7E20-N015 Compatible 15m (49ft) 8 Fibers Low Insertion Loss Female to Female MPO12 to 2xMPO12 Polarity B APC to APC LSZH Multimode OM3 50/125
$67.00
-
NVIDIA MFS1S90-H015E Compatible 15m (49ft) 2x200G QSFP56 to 2x200G QSFP56 PAM4 Breakout Active Optical Cable
$830.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MFS1S50-H015V Compatible 15m (49ft) 200G InfiniBand HDR QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$505.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA NVIDIA(Mellanox) MCX653105A-HDAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR/200GbE, Single-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$1400.00
-
NVIDIA(Mellanox) MCP7H50-H003R26 Compatible 3m (10ft) Infiniband HDR 200G QSFP56 to 2x100G QSFP56 PAM4 Passive Breakout Direct Attach Copper Cable
$75.00
-
NVIDIA(Mellanox) MFS1S50-H003E Compatible 3m (10ft) 200G HDR QSFP56 to 2x100G QSFP56 PAM4 Breakout Active Optical Cable
$480.00
-
NVIDIA NVIDIA(Mellanox) MCX75510AAS-NEAT ConnectX-7 InfiniBand/VPI Adapter Card, NDR/400G, Single-port OSFP, PCIe 5.0x 16, Tall Bracket
$1650.00