
In the fast-evolving world of AI data centers, liquid-cooled servers are the backbone of high-performance computing. If you’re exploring cutting-edge solutions for cloud computing, enterprise networks, or AI-enabled environments, Meta’s GB300 liquid-cooled AI server – codenamed Clemente – stands out. This 1U powerhouse packs 4x GPUs into a compact form factor, pushing the boundaries of density, efficiency, and scalability. In this blog post, we’ll dive into its architecture, cooling innovations, power management, and how it fits into broader AI rack trends. Whether you’re an IT architect or a data center enthusiast, understanding the GB300 Clemente can help optimize your next-gen setups.
The Evolution of AI Super Nodes: From Aggregated to Disaggregated Racks?

Before we geek out on the GB300 specifics, let’s zoom out to the bigger picture of AI infrastructure scaling. At the 2025 OCP Global Summit, Meta’s presentation on “Scaling the AI Infrastructure to Data Center Regions” highlighted a shift in AI rack designs. From left to right in their visuals: existing cabinets leveraging AMD’s MI300X, Meta’s in-house MTIA accelerators, and now the NVIDIA-powered GB300.

Large-scale Scale-Up compute domains require bigger racks.
| Aspect | ORv3 HPR | ORW (Open Rack Wide) | Future Models |
| Status/Time Node | Deployed (Current) | Q3 2026 | Q3 2027 |
| Supported Accelerator Count | ≤ 72 | ≤ 144 | ≥ 256 |
| Interconnect Type | Cabled Backplane | Cabled Backplane | (Not specified, expected to be more advanced) |
| Power Supply Scheme | 48 VDC / ±400 VDC | 48 VDC / ±400 VDC | ±400 VDC |
| Cooling Method | Air Cooling / Liquid Cooling | Air Cooling / Liquid Cooling | Primarily Liquid Cooling |
| Rack Specifications | IT/Power Cabinet Single Width | IT Cabinet Double Width | IT Cabinet Size TBD |
| Power Capacity | (Not specified) | (Not specified) | > 900 kW |
Key Trends in Large-Scale AI Compute Domains
- Bigger Racks for Bigger Compute: As AI workloads demand more xPUs (accelerators), racks are evolving. Meta’s roadmap shows scaling from current setups to 256+ xPUs by Q3 2027, with power draws exceeding 900kW. This is where Open Rack Wide (ORW) standards come in – a collaboration between Meta and AMD, set for Q3 2026 deployment. It supports future Instinct MI450 GPUs and emphasizes openness in AI infrastructure.
- The Rise of Disaggregation: Traditional “aggregated” designs use backplanes (think green and orange lines in diagrams) to tightly integrate components within one or two racks. But as xPU counts grow, interconnection complexity skyrockets. Enter disaggregation: Resources spread across lower-density racks, connected via optical interconnects for low-latency, high-bandwidth communication.
Why does this matter for AI servers like the GB300? Disaggregation enhances elasticity for massive AI training, bypasses single-rack power and cooling limits, and leverages optics to overcome electrical bottlenecks. It’s a game-changer for hyperscale data centers chasing efficiency in AI and HPC workloads.
For more on open rack standards, check out our recent insights on AMD’s “Helios” and Meta’s 2025 OCP Dual-Wide Open Rack.
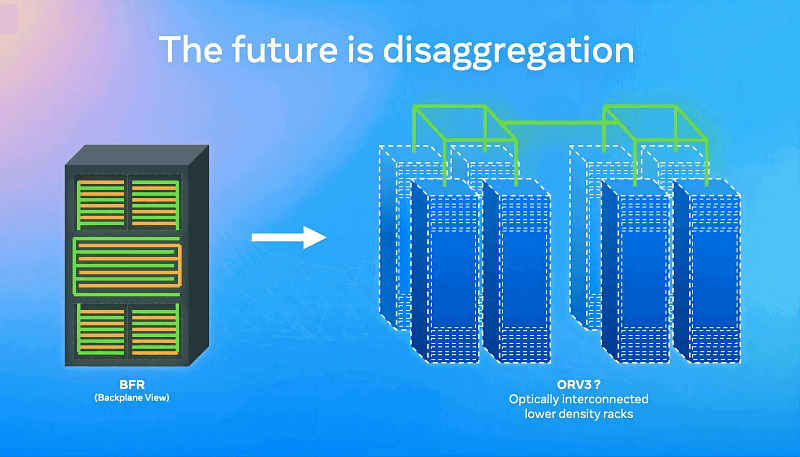
GB300 NVL72 Density: Packing 1U with 2x CPUs + 4x GPUs
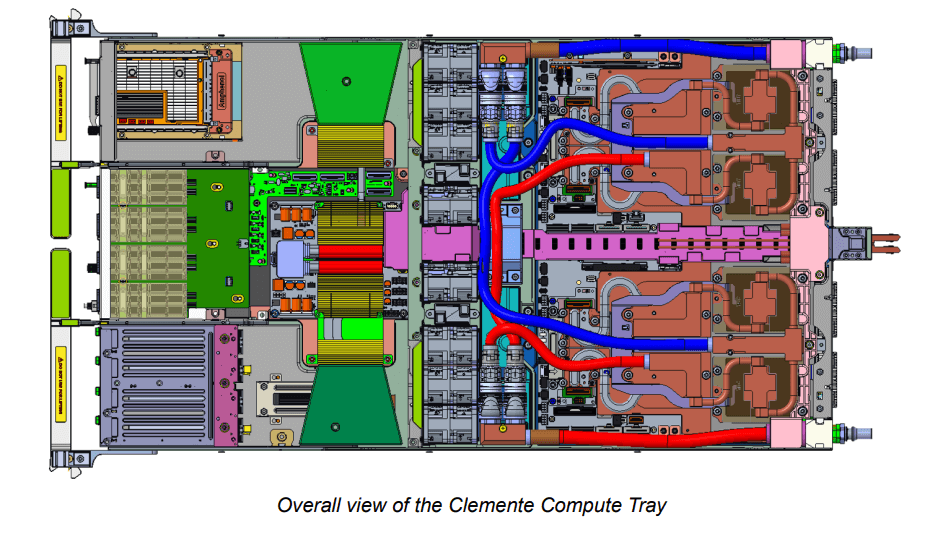
At the heart of the GB300 ecosystem is the NVL72 configuration, and Meta’s Clemente Compute Tray delivers impressive density. This 1OU tray houses two NVIDIA GB300 HPM modules, each featuring one Grace ARM CPU paired with two B300 GPUs. That’s 4x GPUs total in a single 1U slot – a doubling of density compared to the earlier GB200 Catalina (which managed 2x GPUs per 1U).

Front View and Connectivity Breakdown
The Clemente’s front panel is a connectivity hub:
- Scale-Out Networking: 4x 800G OSFP ports for high-speed AI fabric.
- Management: DC-SCM module below.
- Additional I/O: 2x 400G ports on the left; 4x E1.S NVMe SSD bays on the right for fast storage.
Power density? The tray’s TDP hits around 4,200W, with peaks up to 7,740W – demanding robust cooling, which we’ll cover next.
Block Diagram: Inside the GB300 Clemente Architecture
The real magic unfolds in the block diagram. For context, here’s a quick comparison to the GB200 Catalina (updated for CX8 NIC support):
- CPU-GPU Interconnects: Each Grace CPU links to its two B300 GPUs via NVLink C2C. The two Graces connect via Clink x12, while B300s use NVLink 5 for intra-GPU chatter.
- Networking Prowess: The CX8 NIC delivers one 800G port and integrates a PCIe switch for CPU (Gen5 x16), GPU (Gen6 x16), and SSD connectivity. It also ties in as a PCIe x1 endpoint for management. Each Grace gets a dedicated CX7 400G NIC (Gen5 x16), with the primary Grace0 linking to the BMC via PCIe Gen5 x4.
This setup ensures seamless data flow in AI super nodes, minimizing bottlenecks in training massive models.
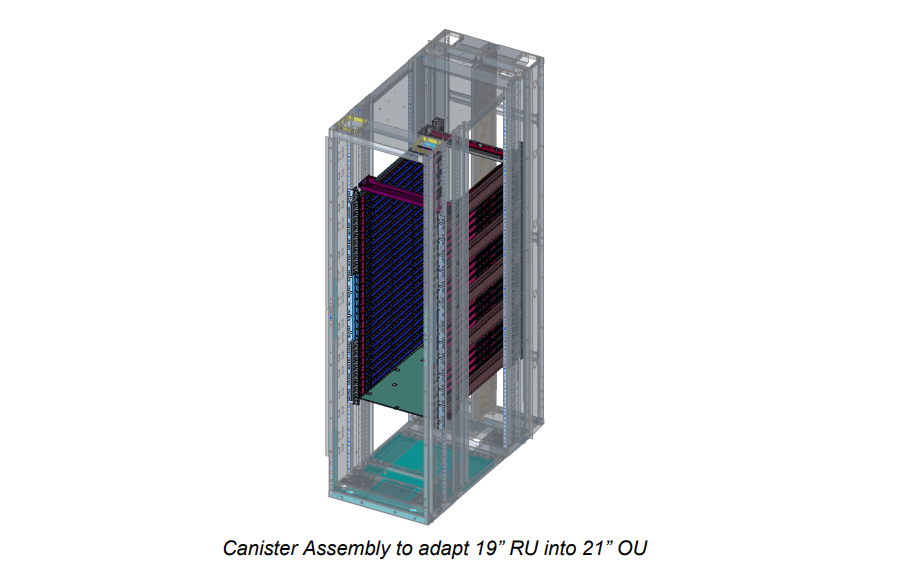
Compatibility: 19-Inch Chassis in 21-Inch Open Racks
Clemente stays true to OCP roots: It’s a 1RU tray fitting standard 19-inch racks, with adapters for 21-inch Open Rack V3 HPR frames. Dimensions and weight are optimized for easy deployment – check the specs diagram for exacts (typically under 30kg unloaded).
A split cooling approach shines here: Air cooling for low-heat components (left side in diagrams), liquid cooling via cold plates for the hot stuff (right side).
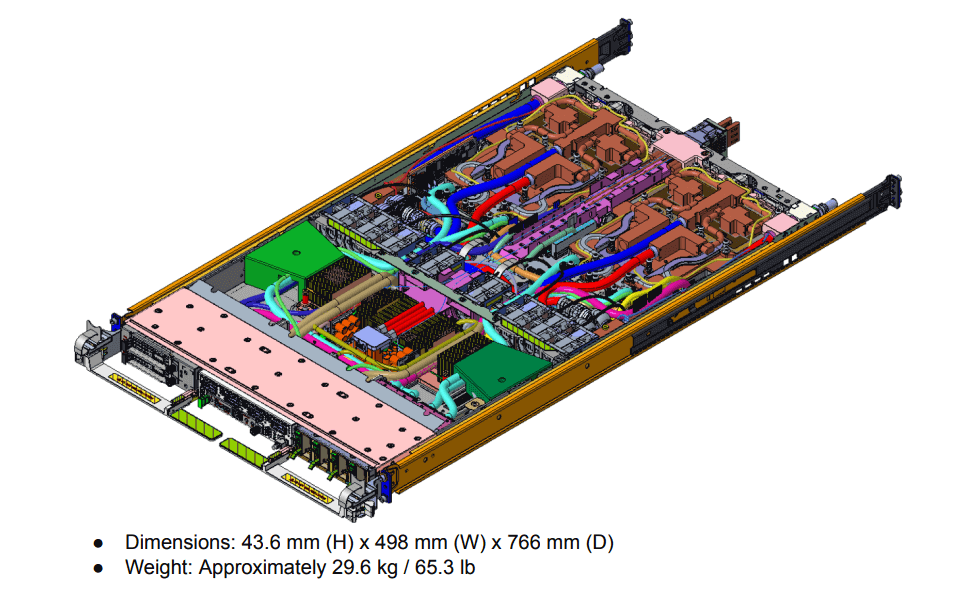
Liquid Cooling Essentials: Channel Island Design
Meta’s Channel Island liquid cooling is engineered for full TDP under load. Key specs for GB300 Clemente:
- Coolant: 25% propylene glycol (PG25) blend, like Dow’s Frost LC-25.
- Supply Temp: 40°C standard (up to 42°C max deviation).
- Flow & Pressure: Up to 140 LPM at 15 psi delta.
- Delta T: 10-12°C at full load, equating to 1.25-1.5 LPM/kW.
This keeps B300 GPUs (each ~1,100W TDP) and Graces chill, enabling sustained AI performance without thermal throttling.
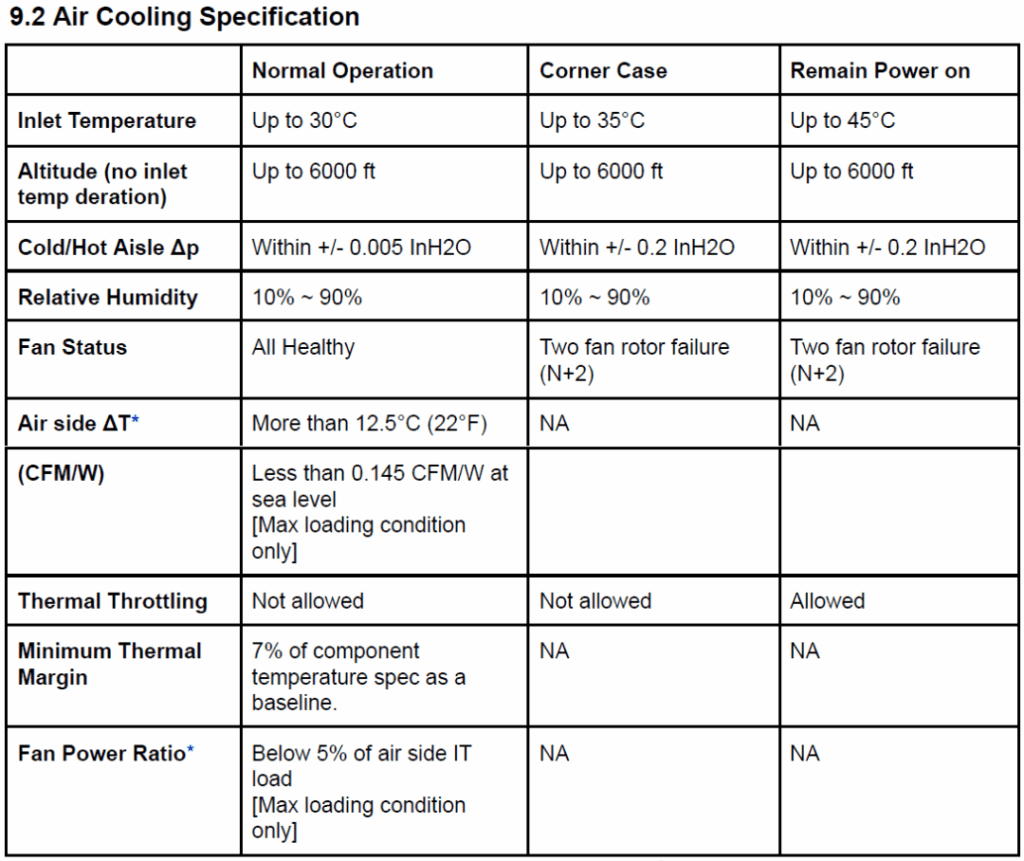
For air-cooled peripherals, norms include standard fan curves – but liquid rules the roost for density.
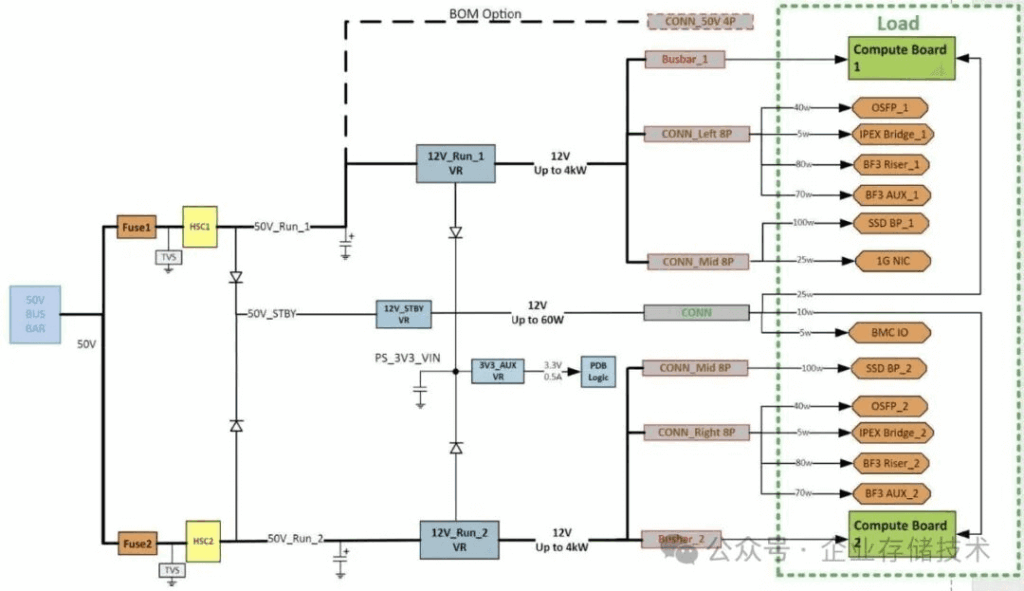
Power Delivery: From 50V Input to 200kW Racks
Power-wise, Clemente steps up from GB200’s 48V to 50V input, down-converting to 12V for VRMs on CPUs and GPUs. In an NVL72 rack (18x Clemente trays), expect ~200kW total, factoring in switches, caps, and losses. (Pro tip: Read up on GB300 NVL72’s new features for stable AI power.)
Notes on scale:
- Liquid-cooled cabinets often hit 40-200kW+ (per data center experts).
- Future dual-wide racks (e.g., Alibab’s Panjiu) aim for 650kW+.
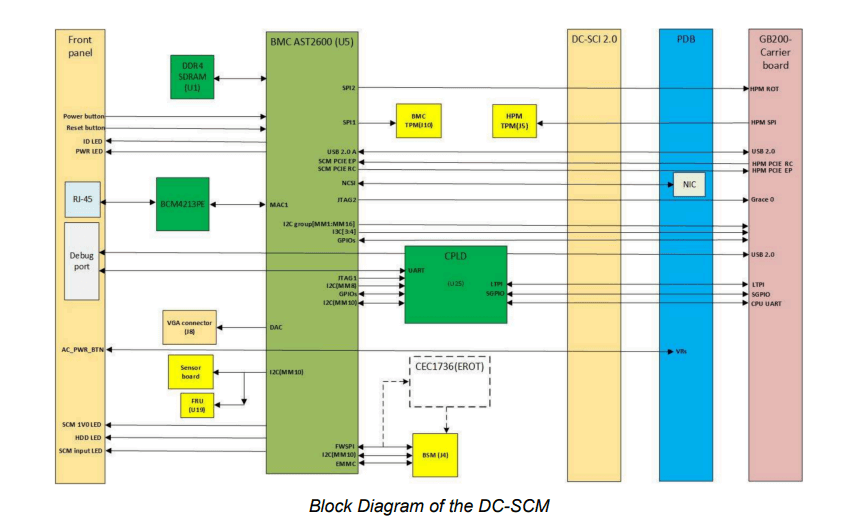
The DC-SCM module? A straightforward BMC setup with AST2600 chip and CPLD for monitoring.
Wrapping Up: Why GB300 Clemente Matters for AI Data Centers
Meta’s GB300 liquid-cooled AI server via Clemente isn’t just denser – it’s a blueprint for disaggregated, optically linked AI futures. With 1U 4xGPU muscle, efficient cooling, and OCP compatibility, it’s primed for 2026+ hyperscalers. As AI racks push 900kW+ boundaries, designs like this ensure scalability without compromise.
At FiberMall, we’re all about empowering these ecosystems with cost-effective optical-communication products and solutions. As a leader in AI-enabled networks, we deliver high-quality transceivers, cables, and modules tailored for data centers, cloud, and enterprise setups. Whether integrating NVLink fabrics or optical interconnects for disaggregated racks, FiberMall has you covered. Visit our official website or contact our support team for tailored advice.
Related Products:
-
 Q112-400GF-MPO1M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
Q112-400GF-MPO1M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
Q112-400GM-MPO1M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
Q112-400GF-MPO3M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
Q112-400GM-MPO3M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
Q112-400GF-MPO60M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
Q112-400GM-MPO60M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 Female Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 Male Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
OSFP-400GF-MPO60M 400G OSFP SR4 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-400GM-MPO60M 400G OSFP SR4 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-800G85F-MPO60M 800G OSFP SR8 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2400.00
-
OSFP-800G85M-MPO60M 800G OSFP SR8 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2400.00
-
OSFP-800G85F-MPO5M 800G OSFP SR8 MPO-12 Female Plug Pigtail 5m Immersion Liquid Cooling Optical Transceivers
$2330.00
-
OSFP-800G85M-MPO5M 800G OSFP SR8 MPO-12 Male Plug Pigtail 5m Immersion Liquid Cooling Optical Transceivers
$2330.00
-
OSFP-800G85F-MPO1M 800G OSFP SR8 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$2250.00
-
OSFP-800G85M-MPO1M 800G OSFP SR8 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$2250.00

















