
New Generation Blackwell Platform
On March 19, 2024, NVIDIA unveiled a new generation of the Blackwell architecture platform at the GTC.
This new platform includes The new AI chip GB200, The second-generation Transformer engine (utilizing proprietary Blackwell Tensor core technology to double AI inference capabilities and model sizes), The fifth-generation NVLink solution (designed to accelerate trillions of parameters and complex AI models, capable of interconnecting up to 576 GPUs, providing a 9x increase in GPU throughput), The RAS (Reliability, Availability, and Serviceability) engine (identifying potential faults early, reducing downtime, enhancing intelligent recovery and maintenance capabilities), Intelligent security services (protecting AI models and customer data without compromising overall performance, supporting next-generation native interface encryption protocols tailored for industries with high data privacy requirements such as healthcare and finance).
Figure 1: NVIDIA Unveils Next-Generation Blackwell Platform

NVIDIA’s NVLink Next-Generation Network Architecture Analysis
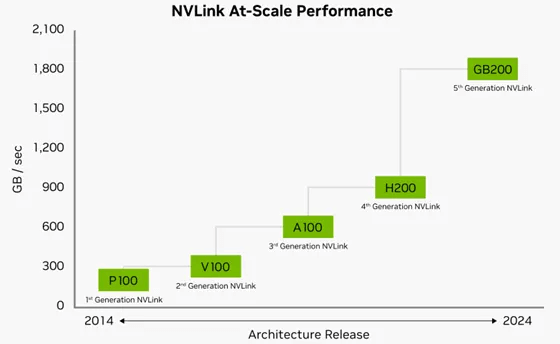
NVIDIA’s fifth-generation NVLink significantly enhances the scalability of large multi-GPU clusters, with a total bandwidth of 1.8TB/s per single-core Blackwell GPU. Each Blackwell Tensor Core GPU can support up to 18 NVLink 100GB/s connections, providing a total bandwidth of up to 1.8TB/s. This bandwidth performance is twice that of NVIDIA’s previous generation H200 product and 14 times that of PCIe 5.0 technology. The GB200 NVL72 server platform leverages NVIDIA’s latest NVLink technology to offer greater scalability for the world’s most complex large AI models.
Figure 2: Performance of NVIDIA’s 5th Generation NVLink Network Architecture
NVIDIA’s New IB Switch Platform Quantum-X800 Supporting Thousand-Card Clusters
NVIDIA has introduced the world’s first end-to-end 800G InfiniBand network switch platform, Quantum-X800, tailored for trillion-parameter scale AI large models. The new NVIDIA IB switch platform supports hardware-based in-network computing technology, scalable hierarchical aggregation reduction protocol SHARP v4, adaptive routing, and network congestion control based on remote monitoring. It consists of three core components:
NVIDIA Quantum-X800 Q3400-RA 4U InfiniBand switch: The world’s first switch utilizing single-channel 200Gb/s technology significantly enhancing network performance and transmission speed. This switch provides 144 ports with speeds of 800GB/s each, facilitated by 72 1.6T OSFP-XD optical modules (connected via NVIDIA’s UFM unified fabric manager). Leveraging the high performance of the new Quantum-X800 Q3400 switch, its two-layer fat-tree network topology can connect up to 10,368 network interface cards (NICs) with extremely low latency while maintaining maximum network locality. The Q3400 switch employs air cooling and is compatible with standard 19-inch racks; NVIDIA also offers the Q3400-LD parallel liquid cooling mode suitable for Open Compute Project (OCP) 21-inch racks.
Figure 3: NVIDIA’s new-generation IB switch platform Quantum-X800

NVIDIA ConnectX-8 SuperNIC Network Interface Card: Utilizing NVIDIA’s latest generation network adapter architecture, it offers end-to-end 800Gb/s network and performance isolation, specifically designed for efficiently managing multi-tenant generative AI clouds. The ConnectX-8 SuperNIC provides 800Gb/s data throughput via PCIe 6.0, offering up to 48 transmission channels for various applications including NVIDIA GPU system internal PCIe switching. Additionally, the new SuperNIC supports NVIDIA’s latest In-Network Computing technology, MPI_Alltoall, and MPI tag-matching hardware engines, as well as structural enhancements like high-quality service and network congestion control. The ConnectX-8 SuperNIC supports single-port OSFP224 and dual-port QSFP112 connectors, compatible with various form factors including OCP3.0, and CEM PCIe x16. It also supports NVIDIA Socket Direct 16-channel auxiliary expansion.
Figure 4: NVIDIA ConnectX-8 SuperNIC New IB Network Interface Card

LinkX Cables and Transceivers: NVIDIA’s Quantum-X800 platform interconnect product portfolio includes connection transceivers with passive Direct Attach Cables (DAC) and linear active copper cables (LACC), providing higher flexibility for building preferred network topologies. This interconnect solution specifically includes dual-port single-mode 2xDR4/2xFR4 connection transceivers, passive DAC cables, and linear active copper cables LACC.
Figure 5: NVIDIA LinkX cables and transceivers

NVIDIA GB200 NVL72 Solution
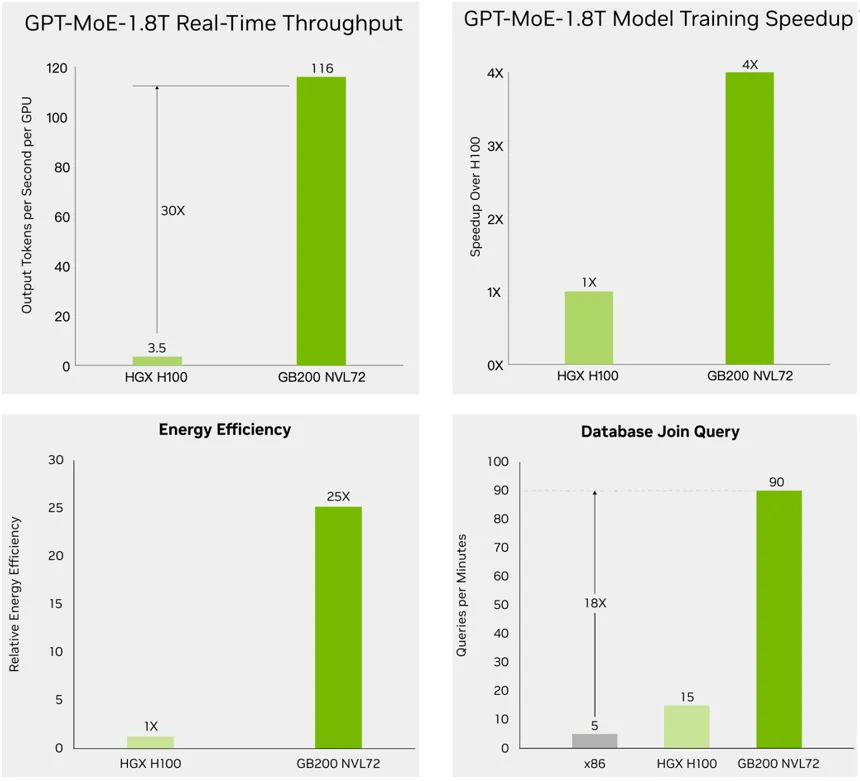
The NVIDIA GB200NBL72 solution offers a 30x increase in inference speed, 4x increase in training speed, a 25x improvement in power efficiency, and an 18x enhancement in data processing performance for trillion-parameter AI models.
Figure 6: NVIDIA releases GB200 NVL72 solution

- In terms of inference performance, the GB200 NVL72 solution utilizes the latest generation Transformer engine supporting FP4 AI and employs the fifth-generation NVLink to provide a 30x improvement in Large Language Model (LLM) inference performance for trillion-parameter large models. It achieves higher precision and throughput with the new Tensor Core microformat and implements a large GPU cluster of 72 GPUs in a single cabinet through liquid cooling.
- For training performance, the second-generation Transformer engine with FP8 precision accelerates large language models and large-scale training speeds by 4x. It provides a GPU-to-GPU interconnect speed of 1.8Tb/s through the fifth-generation NVLink using InfiniBand switch networks and NVIDIA Magnum IO software.
- Regarding power efficiency, the liquid-cooled GB200 NVL72 significantly reduces data center energy consumption. Liquid cooling technology enhances computing density while reducing server rack footprint, enabling high-bandwidth, low-latency GPU communication within large NVLink domain architectures. Compared to the previous generation NVIDIA H100 air-cooled cabinet, the GB200 liquid-cooled cabinet delivers a 25x performance improvement at the same power consumption while effectively reducing water usage.
- In terms of data processing performance, leveraging high-bandwidth memory performance in the NVIDIA Blackwell architecture, NVLink-C2C technology, and dedicated decompression engines, the GB200 boosts critical database query speeds by 18x compared to CPUs while reducing TCO costs by 5x.
Figure 7: NVIDIA’s GB200 NVL72 solution with 30x better inference performance, 4x better training performance and 25x better power efficiency
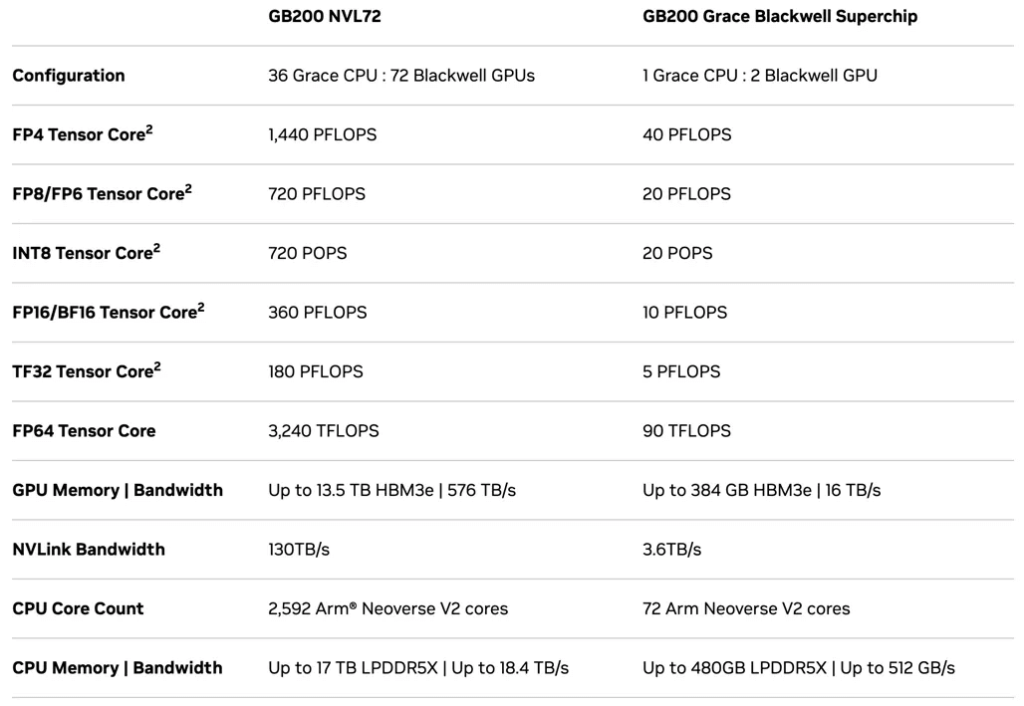
NVIDIA’s GB200 NVL72 single cabinet comprises 9 L1 NV Switch switches and 18 compute nodes. Each compute node consists of a single-layer GPU tray in the cabinet, with each tray containing 2 modules. Each unit comprises 2 Blackwell GPUs and 1 Grace CPU, totaling 4 GPUs per tray. The cabinet houses 18 compute nodes (10 in the upper and 9 in the lower half), totaling 72 Blackwell GPUs and 36 Grace CPUs. The computational performance achieves 1440PFLOPS (FP4)/720PFLOPS (FP8/FP6)/720PFLOPS (INT8), with a maximum GPU memory of 13.5TB (HBM3e). The interconnect parameters include 72 OSFP single-port ConnectX-7 VPIs (400G InfiniBand), with performance parameters for the ConnectX-8 network card yet to be updated. The GB200 AI chip performance can achieve 40PFLOPS (FP4)/20PFLOPS (FP8/FP6)/10PFLOPS (INT8), with a maximum GPU memory of 384GB (HBM3e).
Figure 8: NVIDIA Announces GB200 Superchip AI Chip

NVIDIA Releases GB200 Superchip AI Chip
Detailed Performance Parameters of NVIDIA GB200 NVL72 and GB200 AI Chip
Analysis of NVIDIA’s Next-Generation GB200 Network Architecture Requirements for Copper Connectivity and Optical Modules
Copper connectivity has cost-effective advantages in the 224GB switch era
Copper connectivity has price/performance and power consumption advantages in the trend of high-density clustering of switches and servers, and copper cable connectivity is expected to be the best solution for the 224Gb/s switch era stage by stage. An important change in NVIDIA’s GB200 solution lies in the interconnection between switches and compute nodes in a single cabinet, and the internal connection of switches by copper cable connection instead of the previous PCB-optical module-cable connection. GB200 interconnections are divided into three main categories:
(1) GB200 NVL72 inter-cabinet connection (external cable): large data centers often require a large number of cabinets for parallel computing, if the cabinets need to be networked externally, they are connected through the TOR switch with a DAC/AOC cable (as shown in Figure 10). For a large number of cabinets, the external interconnection needs to be installed in the cabinet above the cabling equipment for orderly connection, cable length is often long, copper cable is more than 2 to 4 meters after the connection requirements can not be met, so the long-distance interconnection of the main use of fiber-optic cables to connect, copper cables in this link can not completely replace the fiber-optic cables.
Figure 9: NVIDIA GB200 NVL72 interconnection diagram between cabinets

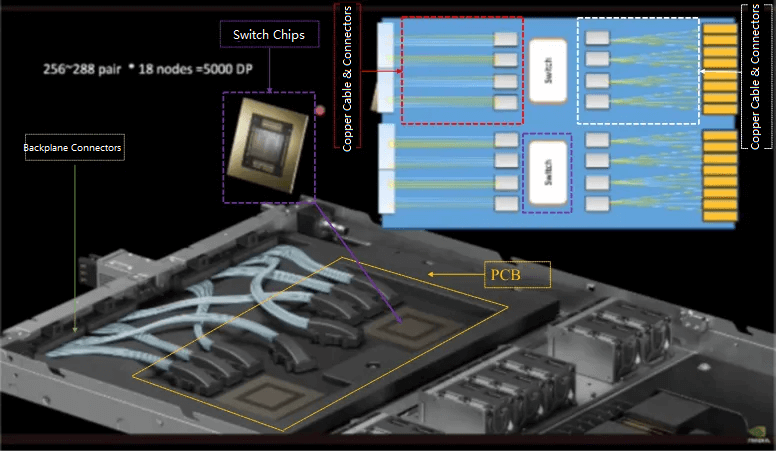
(2) GB200 NVL72 single cabinet connection (cabinet internal cables) – all replaced by copper cables: In Figure 10, eight computing nodes and nine switches are connected internally through the copper cables in the yellow area of Figure 10, and the copper cable backplane replaces the previous use of TOR switches and computing nodes through the PCB backplane-optical module-cable connection. For the new generation of switches with a single channel of 224GB/s, the power consumption of 800G/1.6T optical modules is usually more than 16W, and if the connection scheme of GB200 NVL72 is based on the previous connection of optical modules, it will cause high power consumption problems. Copper connections consume less power and are more cost-effective than optical modules. Broadcom CEO also recently showed support for copper connection attitude: “Optical devices in the communication network will consume a lot of power and cost, so in Broadcom’s new generation of switch development to avoid the use of optical devices, but as far as possible to use copper connection program. Optical devices will only be used when copper transmission cannot meet the demand”.
Figure 10: Schematic diagram of switch and compute node connections inside the NVIDIA GB200 NVL72 single chassis

Figure 11: NVIDIA GB200 NVL72 copper cable backplane and backplane connector schematic

3) NV switch internal – using copper cable to realize the connection from the backplane connector to the switch chip: for a single-channel 224Gb/s switch, as shown in the yellow part of Figure 13, the PCB board area is also limited, not enough to cover the whole area, so it is not possible to realize the link connection over a longer distance, and the copper jumper way can realize the connection from the backplane to switch chip.
Figure 12: Schematic diagram of NVIDIA GB200 NVL72 switch internal copper connection solution
1.6T optical module is expected to usher in accelerated volume opportunities driven by GB200 solutions.
NVIDIA’s new-generation Blackwell platform will drive demand for 1.6T optical modules with higher transmission rates. According to the performance of NVIDIA’s newly released Quantum-X800 Q3400-RA 4U InfiniBand switch, the world’s first switch with single-channel 200Gb/s technology, providing 144 ports with connection speeds of 800GB/s, which is realized by 72 1.6T OSFP optical modules. Therefore, it is expected that the gradual application of the new generation of switches in GB200 solutions will drive up the demand for 1.6T optical modules.
Blackwell platform in large-scale GPU cluster application scenarios still needs optical modules to realize inter-cabinet interconnection, the demand for 800G optical modules will be maintained.
(1) GB200 single cabinet (corresponding to 72 GPUs): the new generation of GB200 single cabinet program will no longer require optical modules to achieve interconnection.
(2) Between 1-8 GB200 NVL72 clusters (corresponding to 72-576 GPUs), some 800G optical modules are still needed to realize the interconnection between cabinets. If 20% of the data needs to be transmitted across cabinets, NVLink unidirectional total transmission bandwidth of 7200Gb corresponds to a single GPU and 800G optical module demand ratio of 1:2.
(3) More than 8 large-scale GB200 NVL72 clusters (corresponding to more than 576 GPUs), it is expected to configure the InfiniBand Layer 3 network, according to the ratio of demand for GPU and 800G optical modules 1:2.5, and the second layer 1:2, it is expected that the overall GB200 demand ratio is 1:4.5.
Related Products:
-
 OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
-
OSFP-800G-2FR2L 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Duplex LC SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-2FR2 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Dual CS SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-DR4 800G OSFP DR4 (200G per line) PAM4 1311nm MPO-12 500m SMF DDM Optical Transceiver Module
$3000.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
-
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km Dual Duplex LC SMF Optical Transceiver Module
$20000.00
-
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF Optical Transceiver Module
$12000.00













