
In the fast-evolving world of AI training, high-performance computing (HPC), and cloud infrastructure, network performance is no longer just a supporting role—it’s the bottleneck breaker. RoCEv2 (RDMA over Converged Ethernet version 2) has emerged as the go-to protocol for building lossless Ethernet networks that deliver ultra-low latency, massive throughput, and minimal CPU overhead. As AI models scale to trillions of parameters, RoCEv2 powers the massive GPU clusters behind breakthroughs like Llama 3 and beyond.
This comprehensive guide dives deep into RoCEv2 technical principles, optimization strategies, deployment best practices, and future trends. Whether you’re architecting a wan-card AI cluster or optimizing a data center, understanding RoCEv2 is essential in 2026.
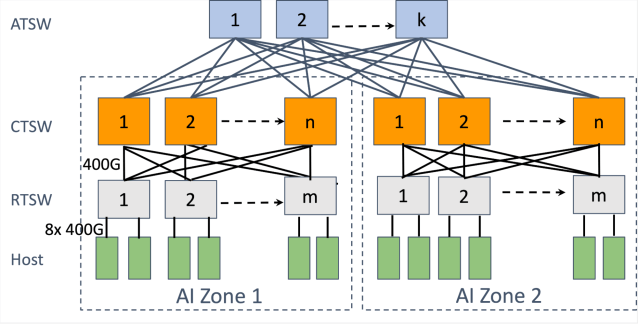
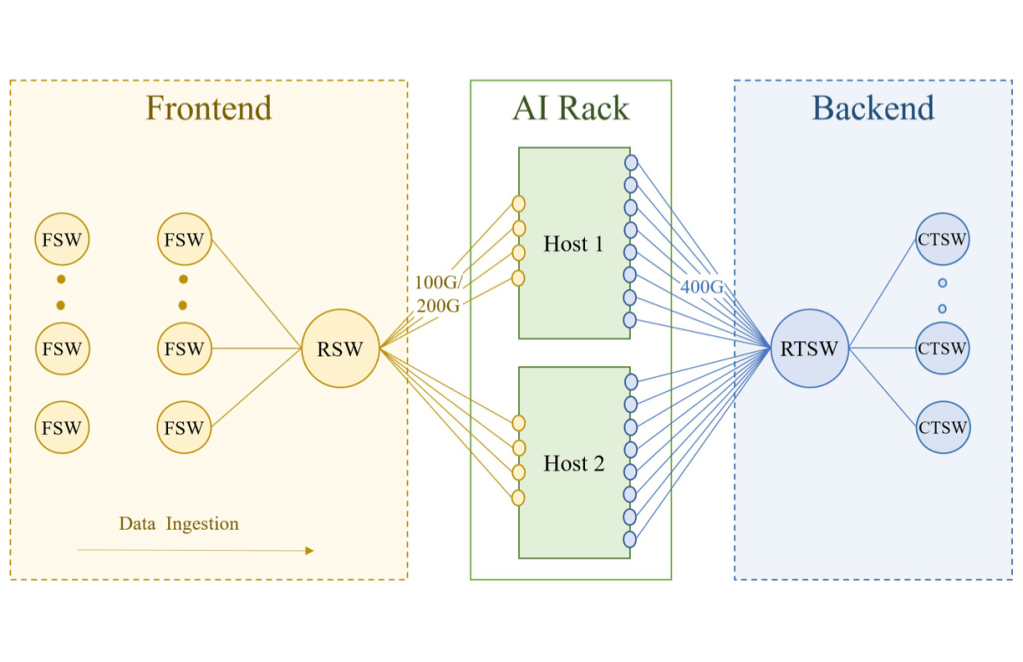
Meta’s massive RoCE-based AI training clusters showcase the scale possible with modern lossless Ethernet.
What is RDMA and Why Does It Matter?
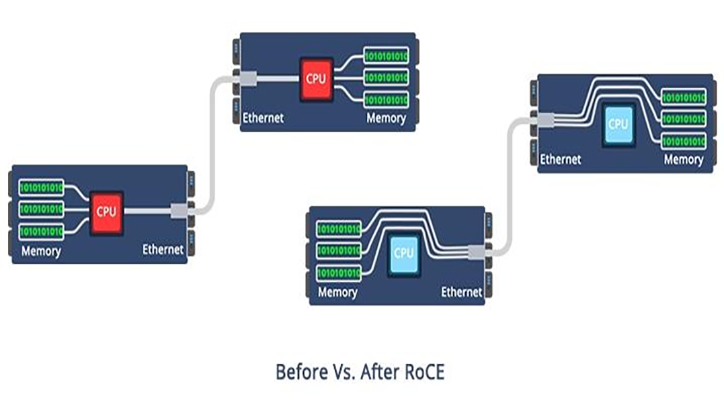
Remote Direct Memory Access (RDMA) allows data to move directly from the memory of one computer to another without involving the CPU, OS kernel, or multiple data copies. This bypasses the traditional TCP/IP stack’s overheads, slashing latency from tens of microseconds to sub-microsecond levels and freeing CPU cycles for actual computation.
Traditional TCP/IP networks suffer from:
- Multiple context switches and data copies
- High CPU utilization for protocol processing
- Fixed delays that scale poorly with bandwidth
RDMA eliminates these, enabling zero-copy, kernel-bypass, and CPU offload—perfect for AI workloads where GPUs need to exchange gigabytes of gradients instantly.
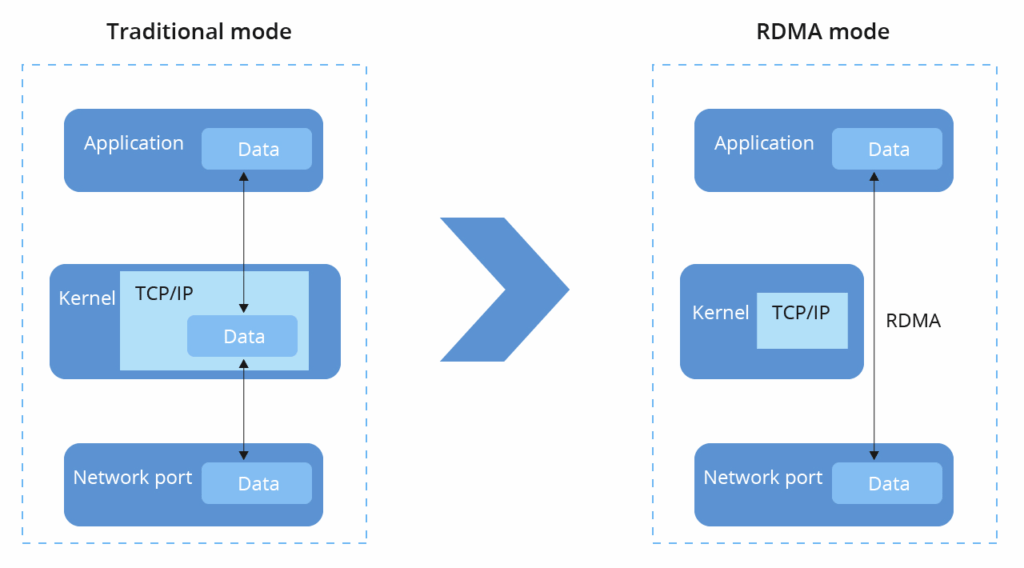
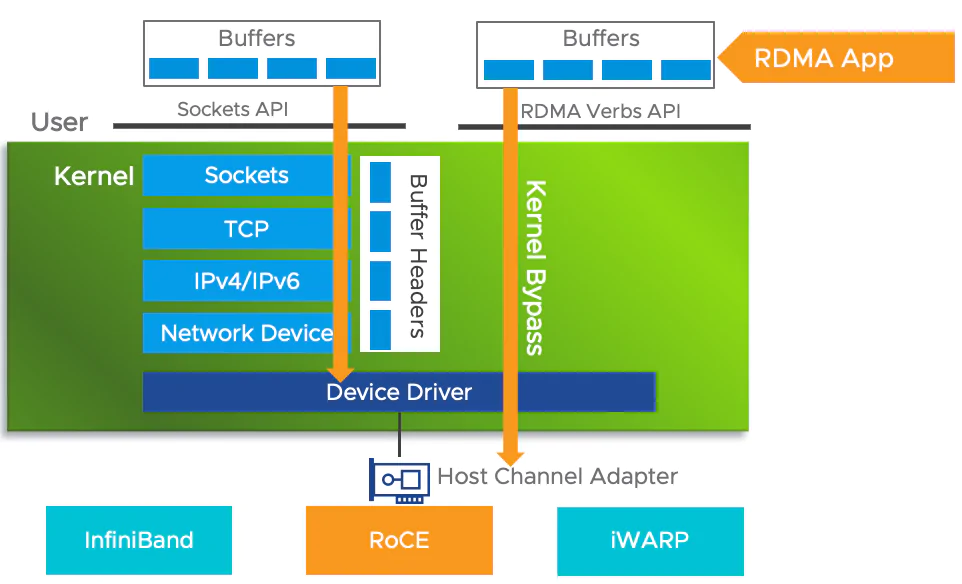
Visual comparison: RDMA vs. traditional TCP/IP data paths—highlighting the dramatic reduction in copies and CPU involvement.
RoCEv2: The Mainstream RDMA Protocol
There are three primary RDMA implementations:
- InfiniBand (IB): Native RDMA with dedicated hardware—excellent performance but high cost and closed ecosystem.
- iWARP: TCP-based RDMA—reliable but complex and resource-heavy.
- RoCEv2: UDP/IP-based RDMA over standard Ethernet—routable, cost-effective, and performant.
RoCEv1 was limited to Layer 2 networks (Ethertype 0x8915), restricting it to single subnets. RoCEv2 (released 2014) adds UDP/IP headers (port 4791), enabling Layer 3 routing and massive scalability.
Today, RoCEv2 dominates because:
- Compatible with existing Ethernet infrastructure (just need RoCE-capable NICs)
- Lower cost than InfiniBand
- Comparable performance: Tests show IB and RoCEv2 training times nearly identical for models like 7B parameters in BF16 precision.
Major players like Meta (24,000 H100 GPUs for Llama 3) and leading Chinese vendors choose RoCEv2 for ultra-scale AI fabrics.
Typical RoCEv2 packet structure and network diagrams.
Key Technical Principles of RoCEv2
Lossless Ethernet: The Foundation
RoCEv2 demands zero packet loss, as RDMA has no built-in retransmission for unreliable transports. Traditional Ethernet drops packets under congestion—unacceptable for RDMA.
Solutions:
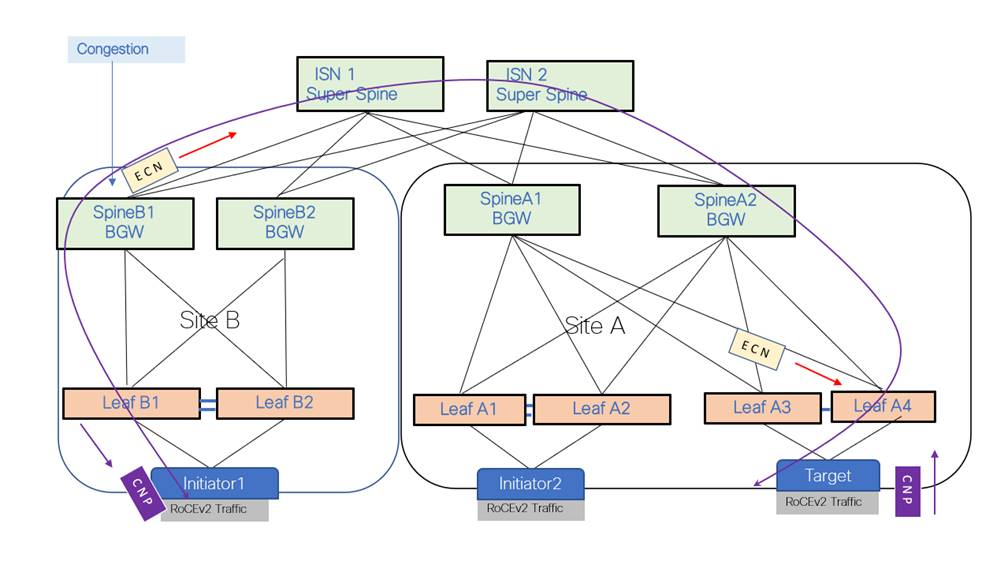
- PFC (Priority Flow Control): Per-priority pause frames to prevent buffer overflow without affecting other traffic classes.
- ECN (Explicit Congestion Notification): Marks packets at congestion points; endpoints reduce rates proactively.
- DCQCN (Data Center Quantized Congestion Notification): Combines ECN with rate adjustment for fair, high-utilization congestion control.
Advanced implementations add AI-driven tuning (e.g., dynamic ECN thresholds based on traffic patterns).
PFC and ECN mechanisms ensuring lossless behavior in RoCE fabrics.
Traffic and Congestion Management
- Priority queues for different traffic types
- Scheduling like WFQ (Weighted Fair Queuing) or WRR
- QoS configuration for AI-specific flows (e.g., AllReduce vs. P2P)
In AI clusters:
- Data Parallel (DP): High-bandwidth AllReduce operations
- Pipeline Parallel (PP): Latency-sensitive Send/Recv
Larger PODs (Points of Delivery) minimize cross-Spine traffic and congestion.
RoCEv2 vs. InfiniBand: Why Ethernet is Winning
The Ultra Ethernet Consortium (UEC), founded in 2023 with members like Meta, Intel, Cisco, and AMD, signals Ethernet’s dominance. Ethernet port speeds (400G/800G/1.6T) outpace IB, with massive industry scale driving innovation.
Performance parity:
- End-to-end latency comparable
- RoCE supports VXLAN for cloud/multi-tenancy (IB does not)
Cost advantage: Switch to RoCE by upgrading NICs only—no full IB rip-and-replace.
Deployment Strategies: Multi-Rail for Maximum Scale
In AI clusters, multi-rail deployment connects each server’s 8 GPUs to separate Leaf switches, maximizing POD size and reducing cross-POD congestion.
Example with high-capacity Leaf switches:
- 51.2T Leaf: Multi-rail supports 512 x 400G cards (thousands of GPUs) per POD
- Single-rail limits to ~64 cards, increasing inter-POD traffic by 8x+
Combined with Spine-Leaf or three-tier topologies, multi-rail enables wan-card (10k+) clusters with 1:1 oversubscription.
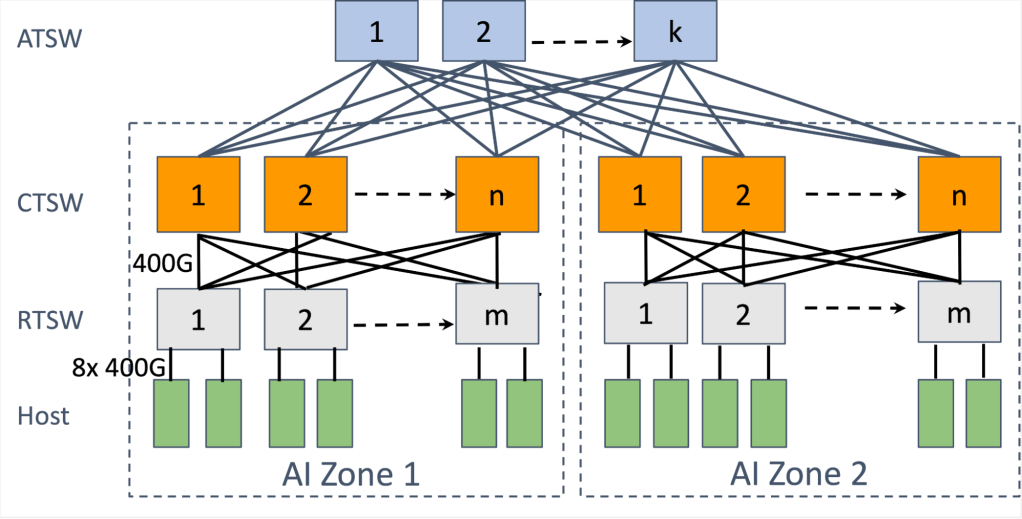
RoCE networks for distributed AI training at scale – Engineering …
Multi-rail topology enabling larger, less congested PODs.
H3C’s RoCEv2 Solutions: Leading in Intelligent Lossless Networks
H3C (New H3C Group) delivers end-to-end RoCEv2 data center solutions, powering national labs and commercial AI centers in China.
Key products:
- S12500 series core switches (up to 800G ports)
- S9827/S6890 high-density Leaf for 400G/800G
- Full portfolio from <1K to 512K GPUs
Innovations:
- AD-DC SeerFabric: AI-powered management platform for automated deployment, visualization, and operations.
- AI ECN: Reinforcement learning optimizes ECN thresholds dynamically.
- One-click pre-training validation: Connectivity, perftest, NCCL tests in hours vs. days.
Real-world cases:
- National lab: 2120 NV GPUs with 400G RoCE
- Wan-card cluster: 16,000+ GPUs, multi-vendor (NVIDIA, Huawei, domestic)
- Enterprise: Breaking IB lock-in with three-network convergence

H3C high-performance data center switches supporting massive RoCE deployments.
Automated Operations with AD-DC
Traditional deployment: Weeks of manual config for thousands of cables/IPs.
H3C AD-DC:
- Intent-based one-click provisioning
- End-to-end topology visualization (GPU-to-NIC-to-switch)
- Fault detection in minutes (wiring errors, PFC storms)
- In-training monitoring: RTT, ECN marks, congestion heatmaps
- Optical module health prediction
Result: Deployment from weeks to days; troubleshooting from days to minutes.
Optimization Strategies for Peak Performance
- Hardware: Jumbo frames (9000 MTU), large buffers, RoCE-capable NICs (e.g., ConnectX series or equivalents).
- Network: Enable PFC on RoCE priority, ECN marking, ECMP load balancing.
- Application: Batch small messages, prefer RDMA Write over Read.
- Security: IPsec for encryption, VLAN isolation, hardware monitoring.
- Tuning: AI-driven congestion control for incast scenarios.
Future Trends in RoCEv2 (2026 and Beyond)
- Ultra Ethernet: Enhancements for even lower tail latency.
- 800G/1.6T ports: Standard in 2025–2026 deployments.
- In-Network Computing: Offload aggregation/reduction to switches.
- Multi-vendor Interop: Open ecosystems breaking proprietary silos.
- AI-Native Fabrics: Self-optimizing networks predicting traffic patterns.
As AI models grow (e.g., GPT-4 scale with trillions of tokens), RoCEv2’s routable, lossless design will remain central.
Conclusion: Embrace RoCEv2 for Next-Gen AI Infrastructure
RoCEv2 isn’t just an upgrade—it’s the foundation for scalable, efficient AI data centers. With performance rivaling InfiniBand at a fraction of the cost, plus intelligent solutions from leaders like H3C, organizations can build wan-card clusters that train models faster and cheaper.
Ready to deploy RoCEv2? Start with lossless fabric design, multi-rail topologies, and automated management. The future of high-performance networking is Ethernet—and RoCEv2 leads the way.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$800.00
-
NVIDIA MCP7Y60-H01A Compatible 1.5m (5ft) 400G OSFP to 2x200G QSFP56 Passive Direct Attach Cable
$116.00
-
NVIDIA(Mellanox) MCP1600-E00AE30 Compatible 0.5m InfiniBand EDR 100G QSFP28 to QSFP28 Copper Direct Attach Cable
$25.00
-
NVIDIA NVIDIA(Mellanox) MCX653106A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Dual-Port QSFP56, PCIe3.0/4.0 x16, Tall Bracket
$828.00
-
NVIDIA NVIDIA(Mellanox) MCX653105A-ECAT-SP ConnectX-6 InfiniBand/VPI Adapter Card, HDR100/EDR/100G, Single-Port QSFP56, PCIe3.0/4.0 x16, Tall bracket
$965.00











