
Selecting the right 400G transceiver for multimode fiber involves many factors. Here are some of the key considerations:
Distance: The range of operations for each type of transceiver varies. Before choosing a transceiver, you should know the exact distance between the systems you plan to connect. Short-range transceivers are typically used for distances up to 70m, while long-range variants can cover distances above 2km.
Power Consumption: Power usage can vary substantially from one transceiver type to another. Higher capacity transceivers often use more power. Ideally, you should aim for a transceiver that offers the required data rate at the lowest possible power consumption.
Cost: Pricing can vary significantly between different transceivers. The overall cost should be evaluated in the context of your specific networking needs and budgetary constraints.
Compatibility: Not all transceivers will be compatible with your switches, routers, or other network devices. Be sure to confirm that the transceiver you choose works with your existing hardware.
Interconnection: Consider how different transceivers suit your interconnection environments. Transceivers come in different form factors such as QSFP-DD, OSFP, CFP2, CFP8, or COBO, and each has its own specifications for things like power consumption, size, and interface.
Reliability and Durability: The lifespan and durability of the transceivers also come into play. High-quality transceivers are built to last, reducing the need for replacements and maintenance.
The key features and common applications of each of these transceivers are described below.
1.The OSFP-400G-SR8 / SR8-C and QDD-400G-SR8 / SR8-C
The 400G-SR8 was the first 400G MMF transceiver available and has been deployed for point-to-point 400GE applications, such as leaf-to-spine connectivity, illustrated below.
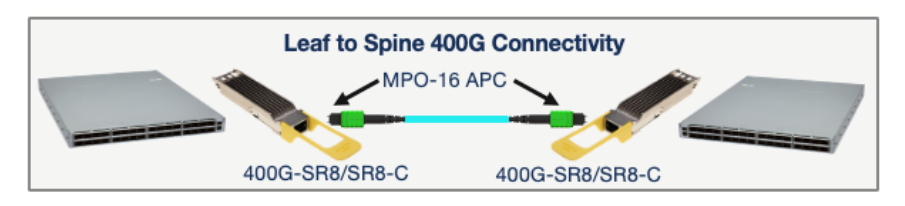
While the 400G-SR8 provides cost-effective 400GE connectivity over MMF, it requires 16 fibers per transceiver and uses an MPO-16 APC fiber connector. Most 40G and 100G parallel MMF optics (such as the 40G-SR4 and 100G-SR4) use MPO-12 UPC fiber connectors. MPO-16 to 2x MPO-12 patch cables are required to use a 400G-SR8/SR8-C transceiver over an MPO-12 UPC-based fiber plant.
Another key application for 400G-SR8 transceivers is optical breakout into 2x 200G-SR4 links, enabling TOR-to-host connectivity where 200G to the host is required, as illustrated below.
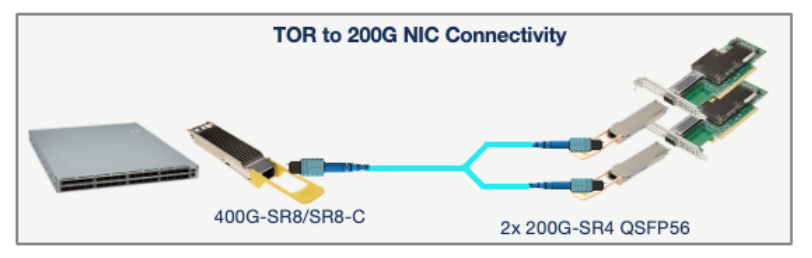
The 400G-SR8-C transceiver has the same features as the 400G-SR8, with the added ability to breakout into 8x 50G-SR or 8x 25G-SR optical links. It can therefore be used in applications that require high-density 50G or 25G breakouts – as illustrated below.
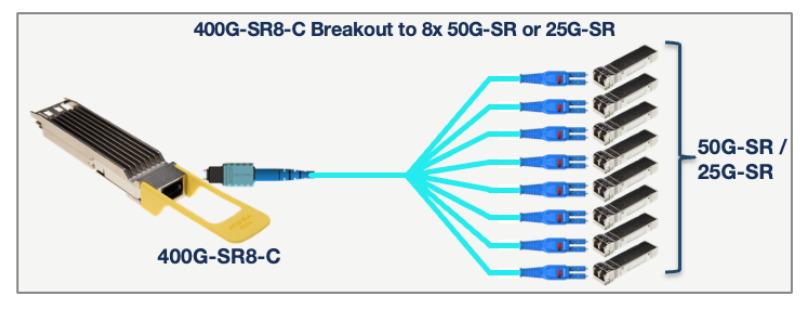
- The OSFP-400G-SRBD and QDD-400G-SRBD, or “400G-BIDI”transceivers.
400G-BIDI transceivers use the widely deployed MPO-12 UPC connector for parallel multimode fiber. This allows existing 40G or 100G links that use 40G-SR4 or 100G-SR4 QSFP optics to be upgraded to 400GE with no change to the fiber plant, as illustrated below:
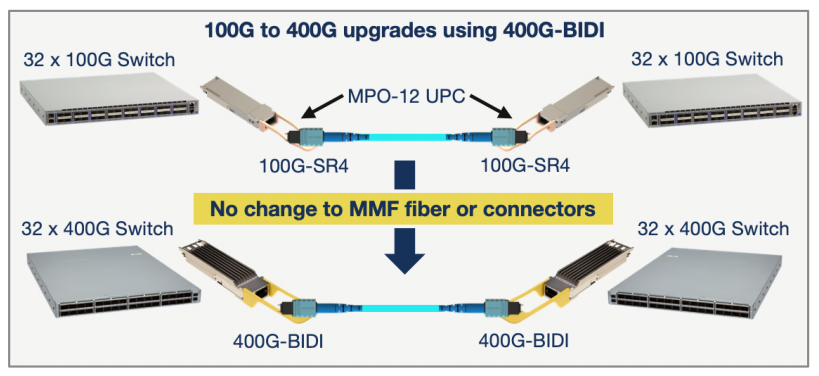
When configured for 400GE operation, the 400G-BIDI transceiver is compliant with the IEEE 400GBASESR4.2 specification for 400GE over 4 pairs of MMF.
Arista’s 400G-BIDI transceivers are also capable of breaking out into 4x 100GE links and can be configured (via EOS) to interoperate either with the widely deployed base of 100G-BIDI (100G-SRBD) transceivers, or newer 100G-SR1.2 transceivers, as indicated below.

In summary, Arista’s 400G-BIDI transceiver is software configurable to operate in any one of three operating modes:
i) 400G-SR4.2 for point-to-point 400GE links
ii) 4x 100G-BIDI for breakout and interop with 4x 100G-BIDI (100G-SRBD) transceivers
iii) 4x 100G-SR1.2 for breakout and interop with 4x 100G-SR1.2 transceivers

800G SR8 and 400G SR4 Optical Transceiver Modules Compatibility and Interconnection Test Report
Version Change Log Writer V0 Sample Test Cassie Test Purpose Test Objects:800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. By conducting corresponding tests, the test parameters meet the relevant industry standards, and the test modules can be normally used for Nvidia (Mellanox) MQM9790 switch, Nvidia (Mellanox) ConnectX-7 network card and Nvidia (Mellanox) BlueField-3, laying a foundation for

Analysis of Management Methods for Unmanaged InfiniBand Switches
Why Unmanaged IB Switches Have No Web-UI 1) Positioning and Functional Simplification 2) Differences in Protocol Stack 3) Reducing Cost and Complexity How to Manage and Configure Unmanaged IB Switches Although there is no Web-UI, they can be managed via the following methods: 1) Connect to the Subnet Manager via

Analysis of Core Port Ratios in Intelligent Computing Center Network Design
Two Key Design Principles for GPU Cluster Networks The Definition of Core Ports In a typical Spine-Leaf (CLOS) network architecture for intelligent computing centers: Consistent Access-to-Core Port Ratios The number and bandwidth of “downlink ports” (used to connect servers) on a Leaf switch should maintain a fixed and sufficient ratio—typically 1:1

NVIDIA Spectrum-X Network Platform Architecture Whitepaper
Improving AI Performance and Efficiency AI workload demands are growing at an unprecedented rate, and the adoption of generative AI is skyrocketing. Every year, new AI factories are springing up. These facilities, dedicated to the development and operation of artificial intelligence technologies, are increasingly expanding into the domains of Cloud

NVIDIA GB200 NVL72: Defining the New Benchmark for Rack-Scale AI Computing
The explosive growth of Large Language Models (LLM) and Mixture-of-Experts (MoE) architectures is fundamentally reshaping the underlying logic of computing infrastructure. As model parameters cross the trillion mark, traditional cluster architectures—centered on standalone servers connected by standard networking—are hitting physical and economic ceilings. In this context, NVIDIA’s GB200 NVL72 is

In-Depth Analysis Report on 800G Switches: Architectural Evolution, Market Landscape, and Future Outlook
Introduction: Reconstructing Network Infrastructure in the AI Era Paradigm Shift from Cloud Computing to AI Factories Global data center networks are undergoing the most profound transformation in the past decade. Previously, network architectures were primarily designed around cloud computing and internet application traffic patterns, dominated by “north-south” client-server models. However,

Why Is It Necessary to Remove the DSP Chip in LPO Optical Module Links?
If you follow the optical module industry, you will often hear the phrase “LPO needs to remove the DSP chip.” Why is this? To answer this question, we first need to clarify two core concepts: what LPO is and the role of DSP in optical modules. This will explain why