

100G Lambda Optics is an optical transceiver transmitting 100 gigabits per second (Gbps) of data over a single wavelength or lambda. They use a modulation technique called PAM4, which stands for Pulse Amplitude Modulation 4, to encode two bits of information per symbol. This allows them to achieve higher data rates than traditional NRZ (Non-Return-to-Zero) modulation, which encodes one bit per symbol.
100G Lambda Optics are compatible with 200G and 400G Ethernet standards, which use multiple lanes of 100G signals to achieve higher bandwidth. They can also interoperate with other 100G optics that use different modulation schemes or wavelengths, such as 100G DR (Duplex Reach), 100G FR (Four Wavelengths), or 100G LR4 (Long Reach). They can support various distances and applications, depending on the type and model of the transceiver.
- QSFP-100G-DR: 100GBASE-DR single lambda QSFP, up to 500m over duplex SMF.
- QSFP-100G-FR: 100GBASE-FR single lambda QSFP, up to 2km over duplex SMF.
- QSFP-100G-LR: 100GBASE-LR single lambda QSFP, up to 10km over duplex SMF.
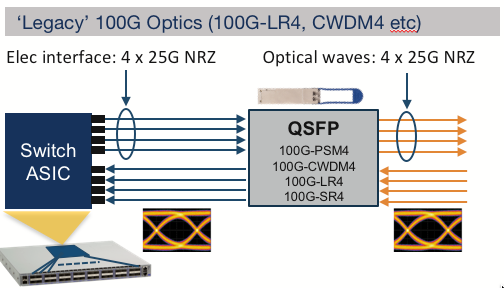
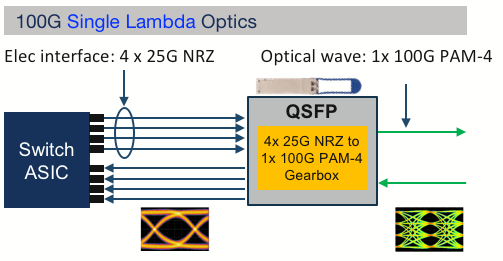
Some of the benefits of 100G Lambda Optics are:
They reduce the complexity and cost of the optical modules and the fiber infrastructure, as they use fewer components and wavelengths than other 100G optics.
They enable future-proofing and scalability of the network, as they can be reused or upgraded to new form factors or higher data rates without sacrificing performance or compatibility.
They provide operational flexibility and efficiency for data center operators, as they can connect to different types of devices and networks using the same type of optic.

800G SR8 and 400G SR4 Optical Transceiver Modules Compatibility and Interconnection Test Report
Version Change Log Writer V0 Sample Test Cassie Test Purpose Test Objects:800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. By conducting corresponding tests, the test parameters meet the relevant industry standards, and the test modules can be normally used for Nvidia (Mellanox) MQM9790 switch, Nvidia (Mellanox) ConnectX-7 network card and Nvidia (Mellanox) BlueField-3, laying a foundation for

Key Design Constraints for Stack-OSFP Optical Transceiver Cold Plate Liquid Cooling
Foreword The data center industry has already adopted 800G/1.6T optical modules on a large scale, and the demand for cold plate liquid cooling of optical modules has increased significantly. To meet this industry demand, OSFP-MSA V5.22 version has added solutions applicable to cold plate liquid cooling. At present, there are

NVIDIA DGX Spark Quick Start Guide: Your Personal AI Supercomputer on the Desk
NVIDIA DGX Spark — the world’s smallest AI supercomputer powered by the NVIDIA GB10 Grace Blackwell Superchip — brings data-center-class AI performance to your desktop. With up to 1 PFLOP of FP4 AI compute and 128 GB of unified memory, it enables local inference on models up to 200 billion parameters and fine-tuning of models
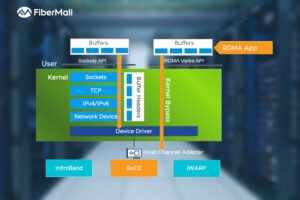
RoCEv2 Explained: The Ultimate Guide to Low-Latency, High-Throughput Networking in AI Data Centers
In the fast-evolving world of AI training, high-performance computing (HPC), and cloud infrastructure, network performance is no longer just a supporting role—it’s the bottleneck breaker. RoCEv2 (RDMA over Converged Ethernet version 2) has emerged as the go-to protocol for building lossless Ethernet networks that deliver ultra-low latency, massive throughput, and minimal CPU

Comprehensive Guide to AI Server Liquid Cooling Cold Plate Development, Manufacturing, Assembly, and Testing
In the rapidly evolving world of AI servers and high-performance computing, effective thermal management is critical. Liquid cooling cold plates have emerged as a superior solution for dissipating heat from high-power processors in data centers and cloud environments. This in-depth guide covers everything from cold plate manufacturing and assembly to development requirements

Unveiling Google’s TPU Architecture: OCS Optical Circuit Switching – The Evolution Engine from 4x4x4 Cube to 9216-Chip Ironwood
What makes Google’s TPU clusters stand out in the AI supercomputing race? How has the combination of 3D Torus topology and OCS (Optical Circuit Switching) technology enabled massive scaling while maintaining low latency and optimal TCO (Total Cost of Ownership)? In this in-depth blog post, we dive deep into the
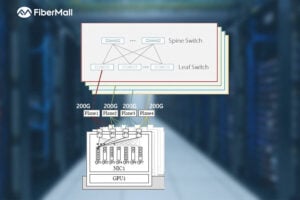
Dual-Plane and Multi-Plane Networking in AI Computing Centers
In the previous article, we discussed the differences between Scale-Out and Scale-Up. Scale-Up refers to vertical scaling by increasing the number of GPU/NPU cards within a single node to enhance individual node performance. Scale-Out, on the other hand, involves horizontal scaling by adding more nodes to expand the overall network scale, enabling