
In the previous article, we discussed the differences between Scale-Out and Scale-Up. Scale-Up refers to vertical scaling by increasing the number of GPU/NPU cards within a single node to enhance individual node performance. Scale-Out, on the other hand, involves horizontal scaling by adding more nodes to expand the overall network scale, enabling support for large-model training tasks that a single node cannot handle alone. This article focuses on introducing Scale-Out networking architectures and their development trends in AI computing centers.
Common Architectures for AI Computing Center Networking
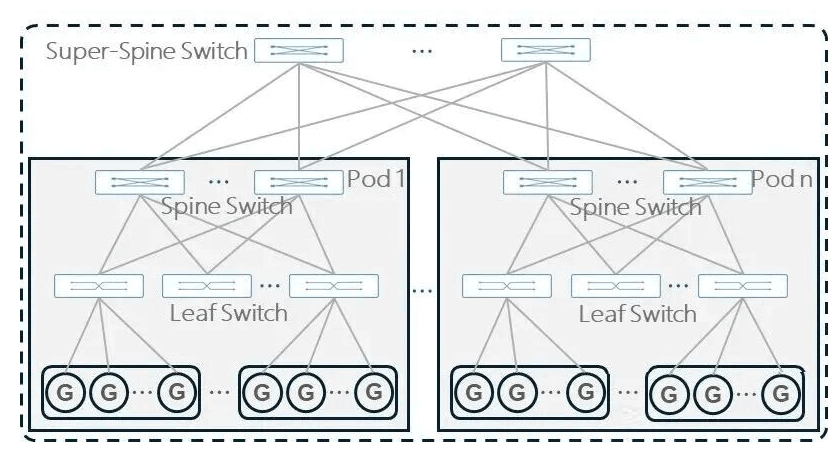
AI computing center networking comes in various forms, such as CLOS, Dragonfly, Slim Fly, Torus, and others. Additionally, several variant networking modes have evolved, including Rail-only, Rail-optimized, MPFT, ZCube, and more. Among these, the Fat-Tree CLOS architecture is widely adopted in large-model training scenarios due to its efficient routing design, excellent scalability, and ease of management. Typically, a two-layer Spine-Leaf CLOS architecture is used. When the two-layer structure cannot meet scaling needs, an additional Super-Spine layer can be added for expansion.
Two-Layer CLOS Architecture
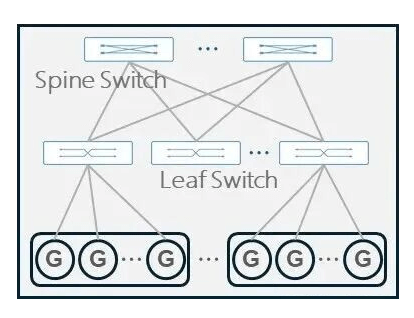
Three-Layer CLOS Architecture
Rail-only Architecture: Proposed by MIT in 2023, the Rail-only network architecture retains the HB domain and Rail switches while removing Spine switches, significantly reducing network costs and power consumption.
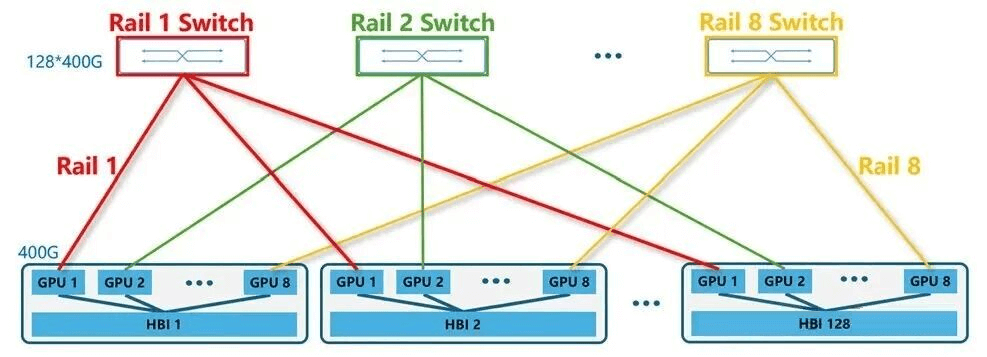
For example, using 51.2T switches, just 8 switches (128 x 400G ports) can form a thousand-card training cluster.
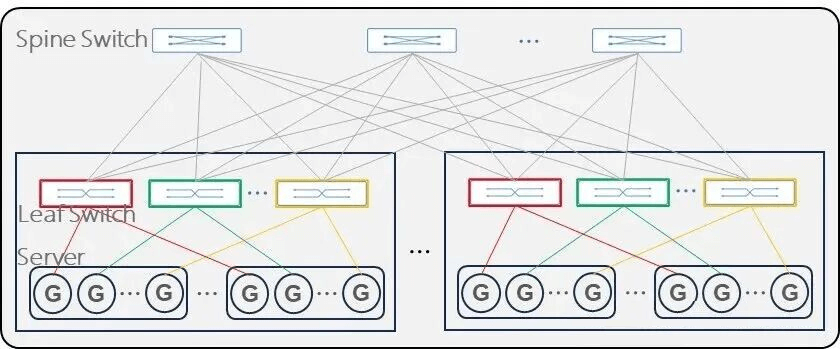
Rail-Optimized Fat-Tree Architecture (ROFT): As shown in the figure below, in a multi-rail network architecture, AI training communication demands can be accelerated through parallel transmission across multiple rails. Most traffic is aggregated and transmitted within the same rail (passing through only one level of switching), while a small portion involves cross-rail transmission (requiring two or more levels), thereby alleviating network communication pressure.
Dual-Plane Network Architecture
In 2024, Alibaba Cloud proposed the dual-port dual-plane networking architecture, which has been applied in HPN-7.0. The primary goals of this architecture are to improve performance, enhance reliability, and avoid hash polarization. This multi-rail dual-plane design builds on the ROFT architecture by splitting each NIC’s 400G port into dual 2x200G ports, connecting to two different Leaf (ToR) switches. The downlink 400G ports on Leaf switches are split into two 200G links connecting to different NIC ports.
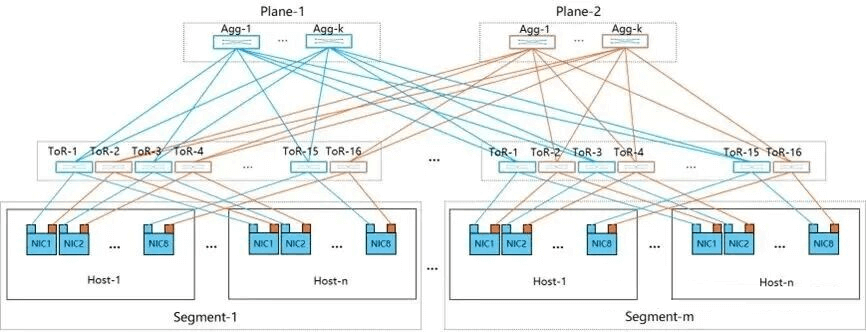
The HPN dual-plane design features the following key advantages:
- Elimination of Hash Polarization: In traditional networks, low-entropy and bursty traffic from large-model training can easily cause hash polarization, leading to uneven traffic distribution. The dual-plane design divides ToR switches into two independent groups, fixing paths for traffic entering uplink links, avoiding hash polarization at the aggregation layer, ensuring even traffic distribution, significantly reducing queue lengths, and improving network performance.
- Enhanced Scalability and Cost Control: A two-layer network can accommodate over 15K GPUs, reducing one layer compared to traditional three-layer CLOS architectures and lowering deployment costs.
- Improved Reliability and Fault Tolerance: Each GPU connects uplink to two independent ToR switches, eliminating single points of failure. During faults, only local ECMP groups need updating without global controller intervention, improving recovery efficiency. These features enhance network fault tolerance and ensure stability for large-model training.
Multi-Plane Network Architecture
In May 2025, the DeepSeek team published a paper titled Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures, introducing the multi-plane networking concept. As LLM (Large Language Model) parameter scales grow exponentially, traditional three-layer Fat-Tree CLOS topologies increasingly reveal limitations in cost, scalability, and robustness.
DeepSeek-V3 adopts an InfiniBand-based Multi-Plane Fat-Tree (MPFT) network to replace the traditional three-layer Fat-Tree architecture. In this setup, each node is equipped with 8 GPUs and 8 400Gbps IB NICs, with each GPU corresponding to an independent IB NIC belonging to a different “network plane.” The 8 GPUs per node connect to 8 different planes (i.e., 8 two-layer Fat-Tree planes). Using 64 x 400G IB switches, a two-layer Fat-Tree can support up to 16,384 GPUs (one plane includes 32 Spine and 64 Leaf switches, accommodating 64 x 32 GPUs; with 8 planes, totaling 16,384 GPUs). Cross-plane traffic exchange requires intra-node forwarding.
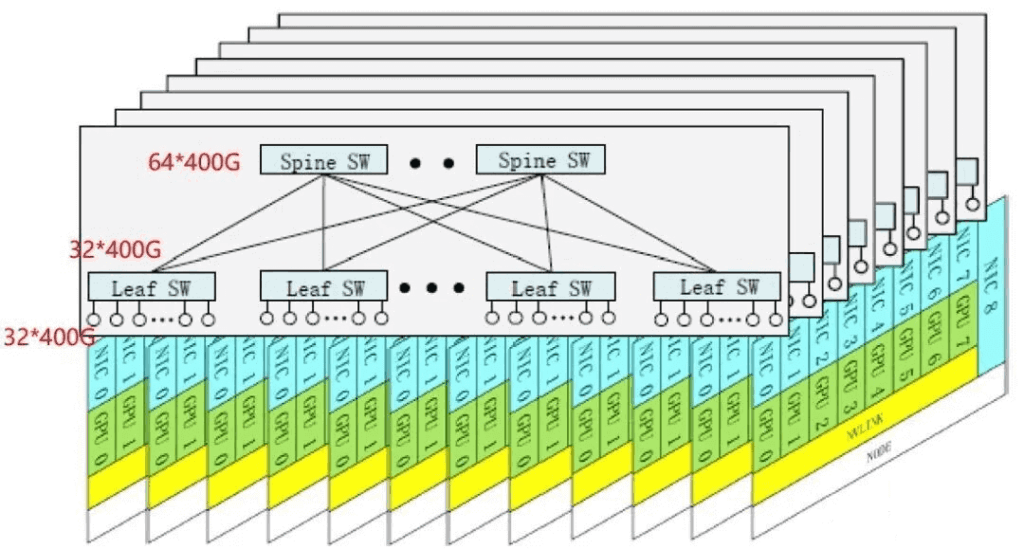
This multi-plane networking mode offers advantages similar to dual-plane networking, with the key difference being that each GPU has a single uplink to an independent plane, lacking dual-uplink fault tolerance per card:
- Lower Cost: Compared to three-layer Fat-Tree, MPFT can save up to 40% in network costs.
- Higher Scalability: Theoretically supports up to 16,384 GPUs.
- Traffic Isolation: Each plane operates independently, preventing cross-plane congestion.
The paper compares several networking modes (FT2: two-layer Fat-Tree, MPFT: multi-plane Fat-Tree, FT3: three-layer Fat-Tree, SF: Slim Fly, DF: Dragonfly):
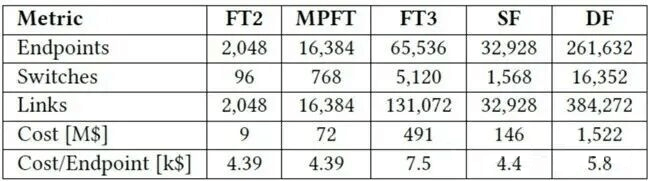
As shown, MPFT demonstrates clear advantages in per-node cost, scalability, and other aspects.
However, the MPFT described above is not the optimal implementation. A more ideal multi-plane networking mode is illustrated below:
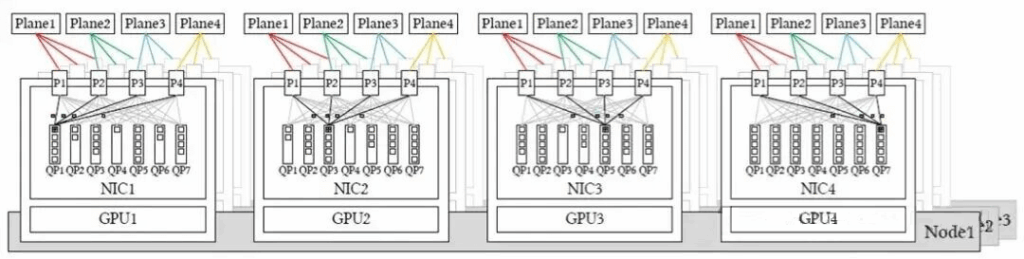
Each NIC is equipped with multiple physical ports (here, 4 x 200G interfaces), with each port connecting to an independent network plane (similar to Alibaba Cloud’s HPN 7.0 dual-plane mode, but with 4 interfaces per NIC instead of 2). A single QP (Queue Pair) can utilize all available ports for packet transmission and reception.
Zooming in on a section of this multi-plane deployment for detail:
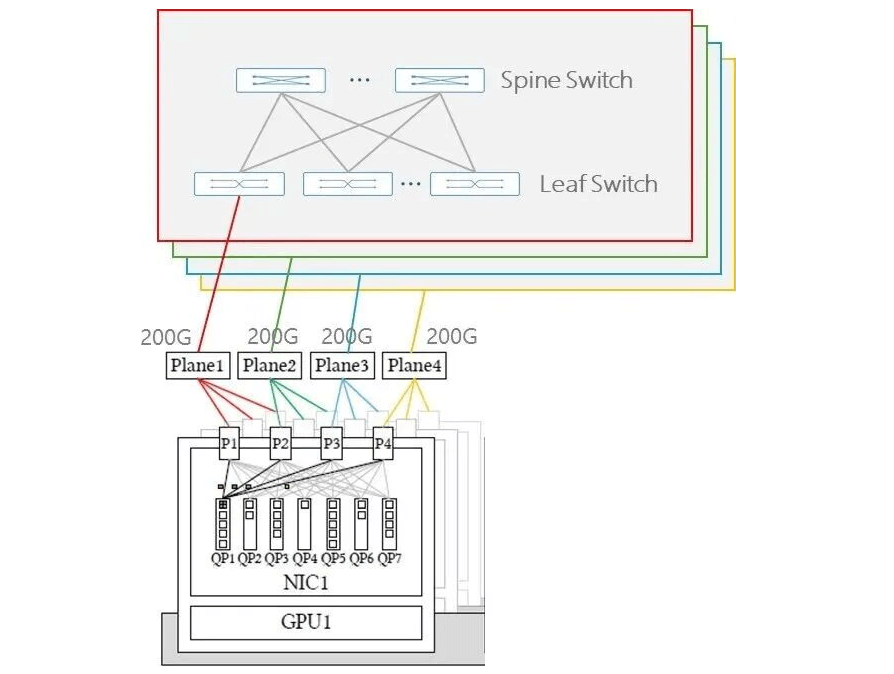
Using 102.4T switches as an example, providing 128 x 800G ports or 512 x 200G via Shuffle (Shuffle will be covered in detail in a future topic; switches can directly provide 512 x 200G links with built-in Shuffle, or use external Shuffle Box or Breakout Shuffle for optical fiber link allocation and mapping). Each GPU connects to 4 different planes via 4 x 200G ports, driven by one QP for per-packet load-balanced routing across ports. This mode is particularly friendly to MoE all-to-all traffic.
Detailed networking diagram:
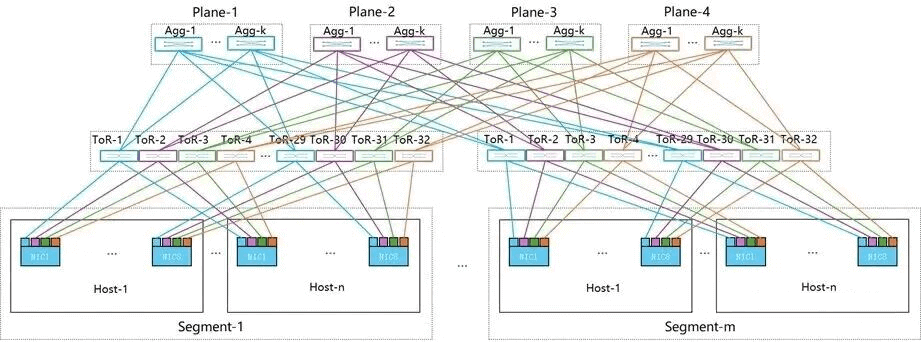
In a two-layer 4-plane setup, it can also accommodate 16,384 GPUs (note: since each NIC connects to 4 x 200G ports, the number of switches increases—requiring 1,024 Spine and 2,048 Leaf switches, 4 times the 768 switches in single-port MPFT).
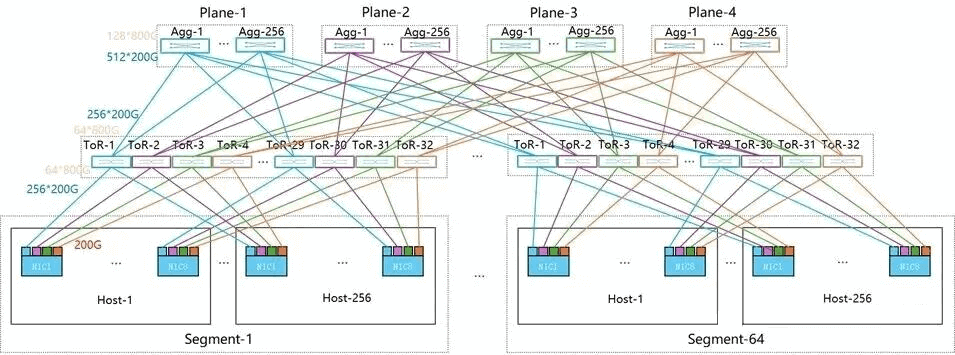
Additionally, to enable these features, new requirements are placed on NICs: support for multi-plane communication, achieving load balancing of QP packets across multiple planes. Due to out-of-order packet arrival via different planes, NICs must natively support out-of-order handling.
NVIDIA’s latest CX-8 already supports 4 network planes (4-Plane), enabling multi-path packet spraying on a single QP with hardware-level out-of-order packet processing to ensure data consistency.
In summary, for Scale-Out networking expansion in AI computing centers, trends in the near future likely include shifting from three-layer to two-layer networking, achieving ten-thousand to hundred-thousand card clusters with two layers, and adopting multi-port multi-plane networking.
This comprehensive overview of dual-plane and multi-plane networking architectures highlights their critical role in optimizing AI data center networks, GPU clustering, and high-performance computing for large-scale AI training. These innovations address key challenges in scalability, cost-efficiency, and reliability for next-generation intelligence computing centers.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4A00 (980-9IAH1-00XM00) Compatible 1.6T OSFP DR8D PAM4 1311nm 500m IHS/Finned Top Dual MPO-12 SMF Optical Transceiver Module
$2600.00
-
NVIDIA Compatible 1.6T 2xFR4/FR8 OSFP224 PAM4 1310nm 2km IHS/Finned Top Dual Duplex LC SMF Optical Transceiver Module
$3100.00
-
NVIDIA MMS4A00 (980-9IAH0-00XM00) Compatible 1.6T 2xDR4/DR8 OSFP224 PAM4 1311nm 500m RHS/Flat Top Dual MPO-12/APC InfiniBand XDR SMF Optical Transceiver Module
$3600.00











