
Introduction: Reconstructing Network Infrastructure in the AI Era
Paradigm Shift from Cloud Computing to AI Factories
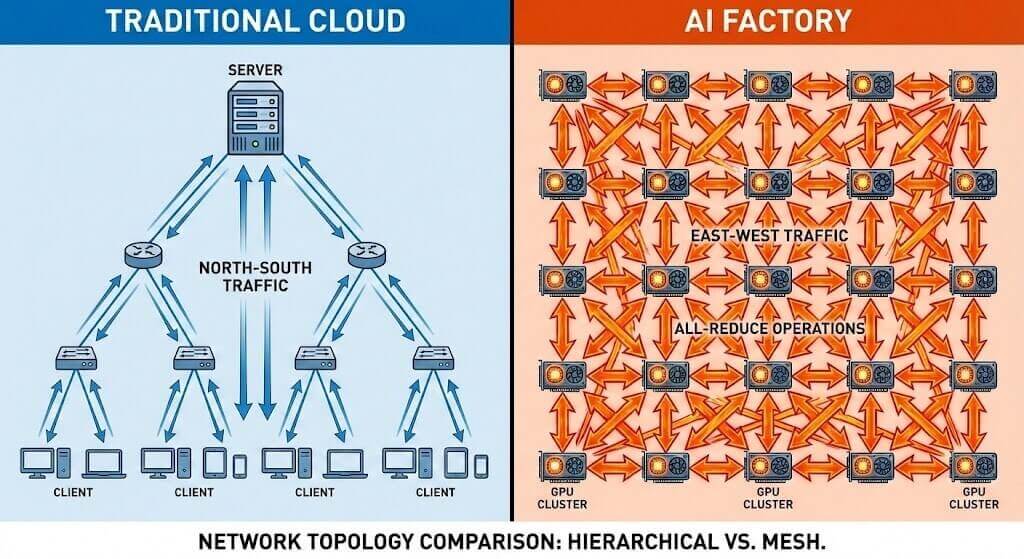
Global data center networks are undergoing the most profound transformation in the past decade. Previously, network architectures were primarily designed around cloud computing and internet application traffic patterns, dominated by “north-south” client-server models. However, with the explosion of generative AI (represented by GPT-4) and large language models (LLMs), the traffic characteristics inside data centers have fundamentally inverted. In AI training clusters, thousands or even tens of thousands of GPUs perform All-Reduce operations, generating massive “east-west” traffic. This traffic exhibits high burstiness, extremely high bandwidth demands, and extreme sensitivity to latency. The network is no longer merely a pipeline connecting compute units—it has become a critical component that determines overall compute efficiency. In million-GPU-scale clusters, even minor network performance jitter can cause expensive GPU compute resources to sit idle.
To address this challenge, data center networks must accelerate from traditional 400G architectures toward 800G and eventually 1.6T. 800G Ethernet represents not only a doubling of bandwidth, but a comprehensive redesign of network topology, congestion control mechanisms, and physical-layer signal integrity. Analysis shows that AI and machine learning workloads are driving 800G port shipments to record highs in 2025, a trend that will reshape the entire Ethernet switch market over the next five years.
Technical Drivers and Timeline of 800G
From a technical evolution perspective, the commercial deployment of 800G has arrived earlier than anticipated—largely driven by the urgent demands of AI compute power. In the context of slowing Moore’s Law, scaling compute through parallelism has become the only viable path, and the efficiency of parallelism is fundamentally limited by interconnect bandwidth.
Bandwidth demand: AI model parameter counts are growing exponentially, causing communication bandwidth requirements to multiply several times every two years—far outpacing Moore’s Law. 800G ports enable higher-density interconnects, allowing single-layer switch architectures to support much larger GPU clusters, thereby reducing hop count and latency.
Cost & energy efficiency: Although absolute per-port cost increases, 800G offers significant advantages in cost-per-bit and power-per-bit compared to 400G. Studies indicate that 800G solutions can effectively reduce total cost of ownership (TCO) by decreasing the number of fibers required and improving spectral efficiency.
This report will deeply analyze the technical standards, core silicon photonics landscape, system vendors’ solutions, and revolutionary changes in optical interconnect technologies (LPO/CPO) for 800G switches, along with an outlook on the evolution toward 1.6T.
Technical Standards and Physical Layer Architecture
Dual-Track Approach: IEEE 802.3df and 802.3dj
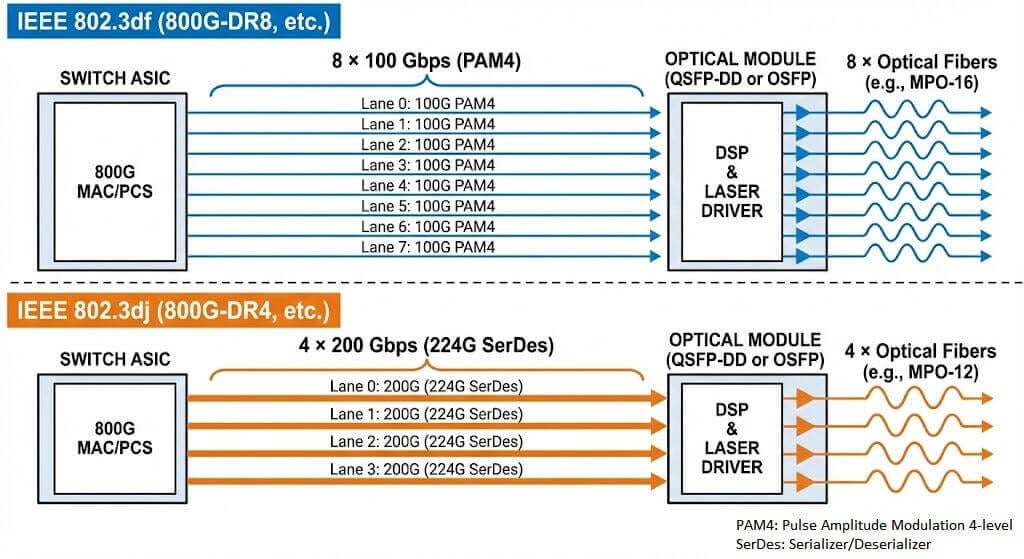
The IEEE 802.3 working group adopted a pragmatic phased strategy when defining next-generation Ethernet standards. The original P802.3df project aimed to cover both 800G and 1.6T rates simultaneously. However, due to differences in single-lane technology maturity, the project was split in November 2022 into two separate efforts: IEEE 802.3df and IEEE 802.3dj.
IEEE 802.3df serves as the cornerstone for current 800G deployments. It specifies the use of 8 parallel lanes, each running at 100 Gbps (actually 106.25 Gbps or 112 Gbps using PAM4 modulation) to achieve an aggregate 800G bandwidth. This standard enables the rapid commercialization of 800G products by leveraging mature 100G/lane optical and electrical components. For example, the 800G OSFP SR8 module is a typical product compliant with this standard and supports fan-out to two 400G links or eight 100G links.
IEEE 802.3dj targets the future. As switch chip capacities move toward 102.4 Tbps, single-lane 200G (224G SerDes) will become essential. This standard covers not only 1.6T but also “second-generation 800G” based on 4 lanes of 200G. This evolution will further reduce fiber cabling complexity and power consumption, while introducing major signal integrity challenges.
SerDes Evolution: From 112G to 224G
SerDes (serializer/deserializer) is the critical interface between the switch chip and the external world. Current mainstream 51.2T switch chips (e.g., Broadcom Tomahawk 5, NVIDIA Spectrum-4) all use 112G PAM4 SerDes.
112G challenges: Transmitting signals at 112 Gbps over PCB traces results in severe medium loss and crosstalk. This forces system designs to use ultra-low-loss materials (such as Megtron 7/8) or flyover cable techniques that bypass PCB loss by connecting directly from chip to front-panel interface.
224G outlook: Next-generation 102.4T chips will adopt 224G SerDes. At this rate, traditional copper interconnects (DAC) will shrink to unusable distances, strongly driving adoption of active electrical cables (AEC), linear-drive pluggable optics (LPO), and eventually co-packaged optics (CPO).
Modulation Formats and FEC (Forward Error Correction)
To transmit more data within limited bandwidth, 800G universally adopts PAM4 (4-level pulse amplitude modulation). Compared to traditional NRZ encoding, PAM4 transmits 2 bits per symbol period, doubling spectral efficiency but reducing SNR by approximately 9.5 dB.
To compensate for the SNR loss, robust FEC mechanisms are mandatory. The IEEE standard defines RS(544,514) Reed-Solomon codes as the baseline. However, FEC inevitably introduces latency. For AI networks that demand ultra-low latency, certain vendors (e.g., NVIDIA and Marvell) have deeply optimized FEC in their chip designs and are exploring low-latency FEC modes for specific short-reach links to minimize end-to-end transmission delay.
Core Silicon Landscape: The Battle for 51.2T Chips
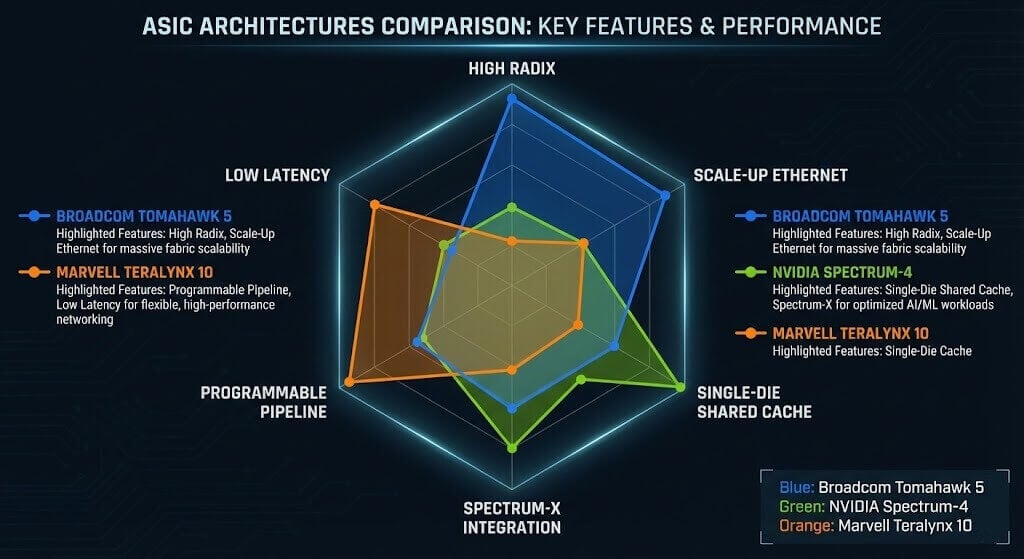
The core engine of 800G switches is the 51.2 Tbps switching ASIC. This generation of chips represents not only a bandwidth increase but also a watershed in architecture. The market has formed a three-way contest among Broadcom, NVIDIA, and Marvell, with each company’s chip architecture differences directly determining the characteristics of downstream system vendor products.
Broadcom: Dual Drivers of Tomahawk 5 and Jericho3-AI
Broadcom continues to cover different market needs through a segmented product line, with a strategy of “total domination” in hyperscale cloud and AI intelligent computing networks.
Tomahawk 5 (StrataXGS series):
- Positioning: High-throughput chip for Spine/Leaf layers in hyperscale data centers.
- Specifications: Single chip 51.2 Tbps, supporting 64 × 800G ports or 256 × 200G ports.
- Architectural highlights: Built on 5nm process, integrates 512 × 100G PAM4 SerDes. Beyond bandwidth, Tomahawk 5 introduces “Scale-Up Ethernet” features, including Cognitive Routing, Dynamic Load Balancing (DLB), and global congestion control. These address hash collisions in AI traffic, significantly reducing tail latency.
- Latency: Achieves an ultra-low forwarding latency of approximately 250 ns—critical for building high-performance AI clusters over Ethernet.
Jericho3-AI (DNX series):
Positioning: Core-layer switch for AI backend networks requiring deep buffers and more complex traffic scheduling.
Differentiation: Unlike Tomahawk’s on-chip shared buffer, the Jericho architecture relies on modular VoQ (Virtual Output Queue) and external HBM memory, providing millisecond-level buffering to handle extreme Incast bursts and ensure zero packet loss in tens-of-thousands-GPU clusters.
NVIDIA: Spectrum-4’s Vertical Integration Logic
NVIDIA is not just selling chips—it is selling the entire “AI factory” interconnect architecture. Spectrum-4 is the core of its Ethernet strategy, aiming to challenge InfiniBand’s dominance in AI via the Spectrum-X platform.
Spectrum-4 ASIC:
Specifications: Custom 4N process (optimized 5nm), integrates 100 billion transistors, delivers 51.2 Tbps bandwidth.
Core advantage: Single-die shared cache. Unlike competitors’ possible multi-slice cache architectures, Spectrum-4 uses a fully shared single-die packet buffer. This allows all ports to dynamically share the entire cache pool, greatly improving absorption of micro-bursts and ensuring fairness and deterministic low latency across ports.
RoCE optimization: As part of the Spectrum-X platform, Spectrum-4 works closely with NVIDIA BlueField-3 DPU to achieve end-to-end congestion control and telemetry. This hardware-software integration boosts effective bandwidth utilization by 1.6× under AI workloads.
Marvell: Teralynx 10’s Programmability and Ultra-Low Latency
Through the acquisition of Innovium, Marvell’s Teralynx product line has become Broadcom’s strongest competitor, especially in the cloud service provider (CSP) market.
Teralynx 10:
Specifications: 51.2 Tbps bandwidth, supports 512 × 112G SerDes lanes, configurable as 64 × 800G.
Low-latency features: Marvell claims industry-leading forwarding latency as low as 500 ns, with deterministic performance across packet sizes.
High radix: Supports up to 512 logical ports, enabling flatter network topologies (e.g., 2-layer architecture for tens of thousands of nodes), reducing hop count, end-to-end latency, and power.
Programmability: Features a programmable forwarding pipeline, allowing customers to support new routing protocols or telemetry standards without hardware changes—providing better investment protection.
Cisco: Silicon One G100’s Unified Architecture
Cisco’s Silicon One G100 chip, while primarily used in 25.6T devices (e.g., Nexus 9232E), embodies the “One Architecture” philosophy that covers both routing and switching markets. G100 uses a 7nm process, supports 32 × 800G ports, and emphasizes high energy efficiency and unified P4 programmability.
Chip Parameter Comparison
| Parameter | Broadcom Tomahawk 5 | NVIDIA Spectrum-4 | Marvell Teralynx 10 | Cisco Silicon One G100 / G200 |
| Process Node | 5nm | Custom 4N (optimized 5nm) | 5nm | 7nm (G100) / 5nm-class (G200) |
| Total Bandwidth | 51.2 Tbps | 51.2 Tbps | 51.2 Tbps | 51.2 Tbps (G200 series) |
| SerDes Technology | 512 × 112G PAM4 SerDes | 112G PAM4 SerDes | 512 × 112G PAM4 SerDes (long-reach) | 112G PAM4 SerDes |
| Typical Port Configurations | 64 × 800G 128 × 400G 256 × 200G | 64 × 800G 128 × 400G | 64 × 800G 128 × 400G 256 × 200G | 64 × 800G / 32 × 800G (platform-dependent) |
| Architecture | Monolithic, shared buffer | Monolithic, fully shared single-die cache | Monolithic, programmable pipeline | Unified programmable (routing + switching) |
| Packet Buffer | On-chip shared (~tens of MB) | Large single-die shared cache | >200 MB deep buffer | Deep buffer options in variants |
| Forwarding Latency | ~250 ns (cut-through) | Ultra-low (~sub-300 ns, AI-optimized) | ~500 ns or lower (deterministic) | Low hundreds ns (optimized) |
| Key AI Features | Cognitive Routing, DLB, global congestion control, Scale-Up Ethernet | RoCEv2 optimization, Spectrum-X integration with BlueField DPU, telemetry | Programmable forwarding, congestion-aware routing | P4 programmability, telemetry-assisted Ethernet, scale-across |
| Target Market | Hyperscale Spine/Leaf, high-throughput AI | AI factories, RoCE fabrics, GPU clusters | Cloud providers, programmable AI networks | Enterprise + cloud, unified routing/switching |
| Power / Efficiency Focus | High radix, low power-per-bit | 1.6× effective bandwidth in AI workloads | Low latency + cost-per-bit | Up to 77% lower power in platforms |
| Status (2025-2026) | Widely shipping since 2023-2024 | Shipping since 2023-2024 | Production/sampling 2023-2025 | Sampling/production 2023-2025 |
System Vendor Products and Solutions
With mature 51.2T chips, major network equipment manufacturers (OEMs) have launched their respective 800G switch products. These go beyond simple chip packaging, showcasing engineering strengths in thermal design, power management, network operating systems (NOS), and optical compatibility.
Arista Networks: Leader in AI Networking
Arista leverages its EOS operating system advantage to hold a strong position in AI networking.
7060X6 series: Flagship 800G product line based on Broadcom Tomahawk 5.
- 7060X6-64PE: 2U fixed-configuration switch with 64 × 800G OSFP ports, optimized for AI backend networks, equipped with 165 MB system cache for effective congestion handling.
- 7060X6-32PE: 1U device with 32 × 800G OSFP ports, total capacity 25.6 T, suitable for smaller clusters or Leaf nodes in Leaf-Spine architectures.
- LPO support: Arista is a strong proponent of Linear Pluggable Optics (LPO). The 7060X6 series explicitly supports LPO modules, reducing power and latency by eliminating DSPs in modules—crucial for large-scale AI cluster efficiency.
Cisco Systems: Evolution of Nexus
Cisco continues to consolidate its position in enterprise and cloud markets via the Nexus series while actively embracing 800G.
Nexus 9232E: Cisco’s first 1RU 800G switch.
- Configuration: 32 × QSFP-DD800 ports, total capacity 25.6 Tbps, based on self-developed Silicon One G100 chip.
- Energy efficiency: Cisco claims 77% lower power consumption and 83% space savings compared to equivalent modular solutions. Supports fan-out modes such as 2×400G, 8×100G—ideal as high-density Spine switch.
Cisco 8100/8800 series: Targeted at service providers and hyperscale data centers, also based on Silicon One architecture with 800G expansion.
Huawei: Comprehensive Layout for Intelligent Computing Networks
As the leader in the Chinese market, Huawei possesses full-stack self-developed capabilities from chips to systems.
CloudEngine 16800 series: Flagship core switch for the AI era.
- Architectural innovation: Orthogonal CLOS architecture (backplane-free design) greatly improves thermal efficiency and signal integrity. CE16800-X series supports high-density 800GE line cards, with up to 288 × 800GE ports per chassis—industry-leading.
- iLossless intelligent lossless algorithm: Huawei’s core competitiveness. iLossless enables real-time learning and training of full-network traffic models, dynamically adjusting queue congestion windows to achieve “zero packet loss” Ethernet transmission—vital for RoCEv2 in AI training.
- Full liquid cooling design: Addresses 800G heat dissipation with advanced liquid + air hybrid cooling for core components and optical modules.
H3C (New H3C): Dual Bets on CPO and LPO
H3C is particularly aggressive in next-generation optical packaging, aiming to overtake via technological innovation.
S9827 series: Covers multiple technology paths for 800G switches.
- S9827-64EO (CPO version): World’s first released 51.2T CPO silicon-photonics switch. Co-packages optical engines with the switch chip, dramatically shortening electrical signal paths to reduce power and latency. H3C claims up to 30% TCO reduction per cluster.
- S9827-64E/EP (LPO/standard versions): Support QSFP-DD800 and OSFP800 interfaces. LPO versions use linear-drive technology combined with AI ECN and dynamic load balancing, tailored for AIGC intelligent computing scenarios.
Ruijie Networks and ZTE Ruijie Networks
Launched RG-S6990-64OC2XS, a 64-port 800G OSFP switch positioned for AI data center Spine layer. Emphasizes low latency and lossless features in “intelligent speed” networks, with LPO optical module solutions. Core switch RG-N18000-X already supports evolution to 800G line cards.
ZTE: ZXR10 9900X series data center switches support high-density 400GE with smooth evolution to 800GE, using backplane-free orthogonal architecture and maximum switching capacity up to 198 Tbps. ZTE has also achieved breakthroughs in long-haul 800G transmission (OTN), completing 1200 km 800G transmission tests.
Juniper Networks QFX5240 series
Based on Broadcom Tomahawk 5.
- Specifications: 2U device supporting 64 × 800G ports (OSFP or QSFP-DD).
- Management: Combined with Apstra software for intent-based networking (IBN), simplifying AI Fabric deployment and operations.
Optical Interconnect Revolution: The Contest Between Pluggable, LPO, LRO, and CPO
The biggest technical variable in the 800G era lies not in the electrical layer but in the optical layer. As rates rise, DSP power consumption in optical modules surges, becoming a bottleneck for system energy efficiency. This has sparked fierce debate over optical interconnect form factors.
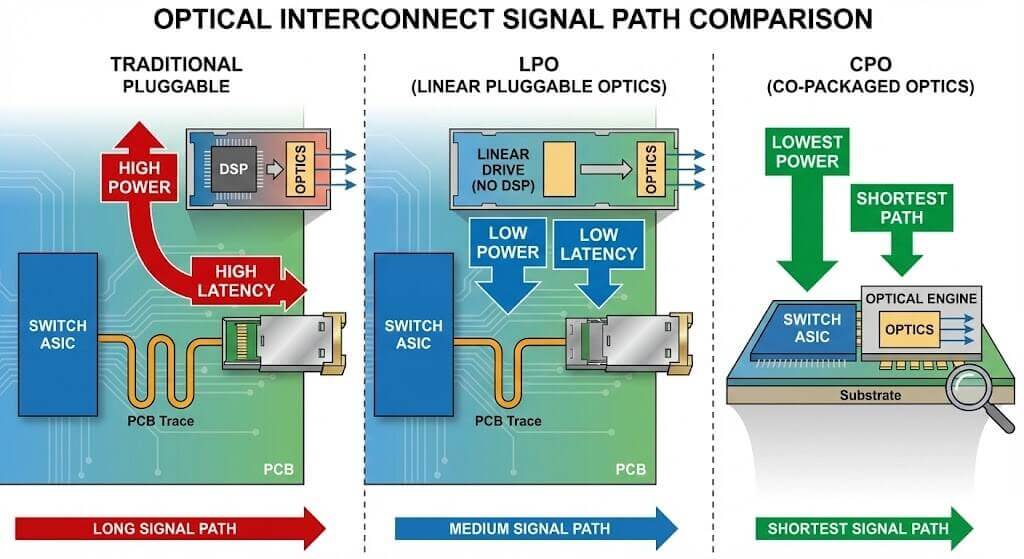
Traditional Pluggable Optics (Retimed/TRX)
Current mainstream (QSFP-DD800, OSFP). Modules integrate DSP for retiming and equalization.
- Advantages: Mature ecosystem, good interoperability, easy fault isolation and replacement.
- Disadvantages: High power (16–20 W per 800G module, ~50% from DSP). In a fully loaded 64-port switch, module power alone can exceed 1000 W, creating huge thermal pressure.
Linear Pluggable Optics (LPO – Linear Drive)
LPO is seen as the most effective short-term solution to the “power wall,” especially inside AI clusters.
- Principle: Removes DSP, retaining only TIA and Driver; equalization/retiming handled by switch ASIC SerDes.
- Advantages: ~50% lower power per module (~7 W savings), nanosecond-level latency reduction, lower BOM cost.
- Challenges: Extremely high signal integrity requirements on host side; limited to short reaches (~500 m). Lacks DSP isolation, so interoperability requires deep coupling between system and module vendors (e.g., Arista’s partnerships).
Linear Receive Optics (LRO/Half-Retimed)
Compromise between LPO and full retimed modules.
- Principle: Removes DSP only on receive (Rx) path; retains DSP on transmit (Tx) for signal quality.
- Advantages: Better signal consistency and interoperability than pure LPO (Tx quality guaranteed by module DSP), while still offering lower power/cost than full-DSP modules (though savings roughly half of LPO).
- Positioning: Suited for customers wanting power reduction but concerned about pure LPO risks.
Co-Packaged Optics (CPO)
Regarded as the ultimate form factor for optical interconnects under Moore’s Law.
- Principle: Optical engines directly co-packaged on switch ASIC substrate, eliminating front-panel pluggable interfaces.
- Advantages: Minimizes electrical path → lowest power and highest density.
- Challenges: Poor maintainability (failure may require full switch replacement); disrupts traditional decoupled supply chain.
- Status: H3C and Broadcom have released prototypes/products, but large-scale commercial use remains limited to specific hyperscale scenarios or future reserves.
Economic Analysis: TCO Advantages of 800G
Although single-port price is higher than 400G, system-level TCO is highly attractive.
Price crossover: Market data shows that by 2025, the cost of one 800G port has fallen below the combined cost of two 400G ports—“cost-per-bit” crossover achieved.
Operational savings: LPO-based 800G solutions can save millions of dollars annually in electricity and cooling for large data centers.
Thermal Management and Mechanical Engineering Challenges
As single-chip power consumption approaches 1000 W (Tomahawk 5 under full load) and optical module density continues to increase, traditional air cooling is approaching its physical limits.
Limitations of Air Cooling
Dissipating the heat load of a 51.2T switch (typically exceeding 2000–3000 W) inside a 2U chassis pushes air-cooling systems to extremes. According to fan affinity laws, fan power scales with the cube of rotational speed. To maintain acceptable temperatures, fan speeds must increase dramatically, causing fan power itself to account for a significant portion of total system power (often >20%)—an unsustainable situation.
Introduction of Liquid Cooling
800G switches are becoming the vanguard for liquid-cooling adoption in data centers.
- Cold-plate liquid cooling: Primarily targets high-power ASIC chips with direct liquid cooling, while optical modules remain air-cooled. This is currently the most practical and widely implemented integration approach.
- Immersion liquid cooling: The entire system is submerged in a dielectric coolant. This requires optical modules to be fully sealed and coolant-compatible. Several vendors have already developed 800G optical modules suitable for immersion environments.

System design innovations: Both H3C’s S9827 series and Huawei’s CE16800 series emphasize advanced thermal engineering—orthogonal architectures for optimized airflow, hybrid air-liquid cooling options, and overall PUE (Power Usage Effectiveness) reduction.
Market Economics and Future Outlook
Market Size and Forecast
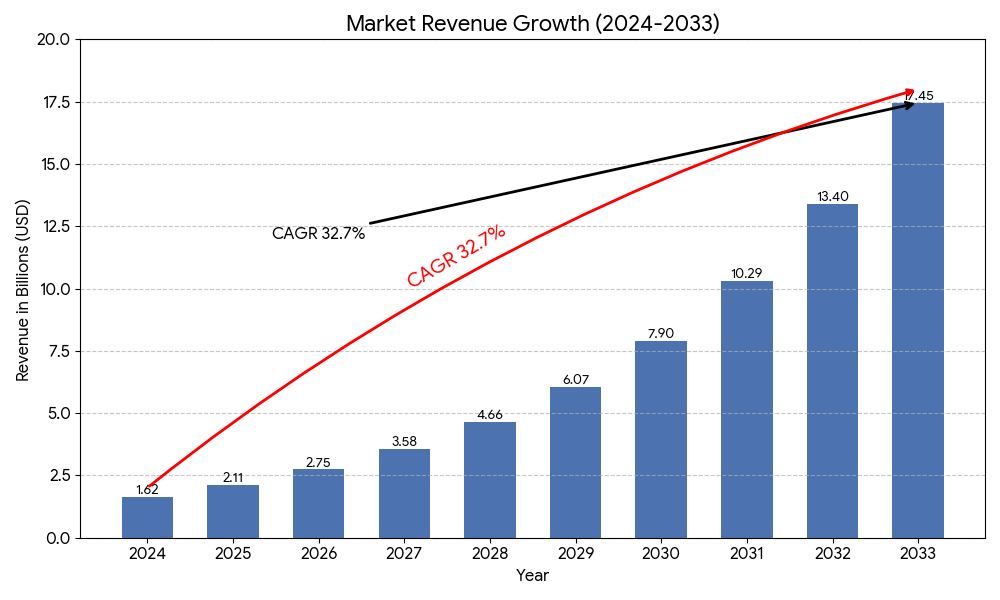
The 800G switch market is in the early stages of explosive growth.
- According to Dell’Oro and Dataintelo reports, the global 800G switch market reached approximately $1.62 billion in 2024 and is projected to reach $17.45 billion by 2033, with a compound annual growth rate (CAGR) of 32.7%.
- 2025 is widely regarded as the “year of 800G,” with port shipments expected to hit record levels—particularly in AI backend networks—where 800G ports are rapidly displacing 400G and 200G.
Vendor Market Share Analysis Global landscape
(excluding China): Arista, NVIDIA, and Cisco dominate. Arista holds a very high share among hyperscalers; NVIDIA effectively monopolizes turnkey AI fabric solutions.
China landscape: Huawei and H3C (New H3C) form a duopoly. Huawei benefits from self-developed silicon and a massive installed base; H3C is more aggressive in adopting next-generation technologies such as CPO. Ruijie Networks is an active challenger, particularly in white-box/ODM deals with major internet companies.
The Road to 1.6T
The industry is already looking ahead to 1.6T Ethernet.
Chip readiness: Broadcom’s Tomahawk 6 (102.4T) and Marvell’s next-generation silicon are on roadmap, with samples expected in 2025–2026.
Technical hurdles: 1.6T will fully adopt 224G SerDes. This effectively ends the era of practical copper interconnects (DAC/AEC), pushing LPO (very short reach) and especially CPO into mainstream roles.
Timeline: With IEEE 802.3dj standardization expected to complete in 2026, early 1.6T deployments are anticipated in 2026–2027, primarily to support training of next-generation trillion-parameter models.
Conclusion
800G switches represent far more than a bandwidth upgrade—they are the foundational infrastructure of AI-era data centers. The extreme challenges at the physical layer, the dramatic shift in optical interconnect form factors (from traditional pluggable → LPO → CPO), and the rise of purpose-built AI networking features (Spectrum-X, Tomahawk 5 AI enhancements, iLossless, etc.) together define this technology cycle.
For enterprises and data center operators, selecting an 800G solution is no longer just about comparing port prices. The decision must now balance end-to-end latency (directly impacting AI training efficiency), power & cooling TCO (affecting long-term operating expense), and long-term supply-chain security. With the 2025 price crossover point already here, large-scale 800G deployment is inevitable. In this race, the vendors that most effectively solve the dual “power wall” and “latency wall” challenges will emerge as the biggest winners.
Related Products:
-
 NVIDIA SN5600 (920-9N42F-00RI-7C0) Spectrum-4 based 800GbE 2U Open Ethernet switch with Cumulus Linux authentication, 64 OSFP ports and 1 SFP28 port, 2 power supplies (AC), x86 CPU, Secure Boot, standard depth, C2P airflow, tool-less rail kit
$50000.00
NVIDIA SN5600 (920-9N42F-00RI-7C0) Spectrum-4 based 800GbE 2U Open Ethernet switch with Cumulus Linux authentication, 64 OSFP ports and 1 SFP28 port, 2 power supplies (AC), x86 CPU, Secure Boot, standard depth, C2P airflow, tool-less rail kit
$50000.00
-
NVIDIA MQM8790-HS2F Quantum HDR InfiniBand Switch, 40 x HDR QSFP56 Ports, Two Power Supplies (AC), Unmanaged, x86 Dual Core, Standard Depth, P2C Airflow, Rail Kit
$14000.00
-
NVIDIA MQM8700-HS2F Quantum HDR InfiniBand Switch, 40 x HDR QSFP56 Ports, Two Power Supplies (AC), Managed, x86 Dual Core, Standard Depth, P2C Airflow, Rail Kit
$17000.00
-
NVIDIA Q3400-RA Quantum-3 XDR InfiniBand Switch, 4U, 144x 800Gb/s XDR Ports, 72 OSFP Cages, 8 PSUs (No Power Cords), Managed, C2P Airflow, Standard Depth, Rail Kit
$105000.00



