
As a leading specialist in optical-communication products and solutions, FiberMall is dedicated to providing cost-effective options for global data centers, cloud computing, enterprise networks, access networks, and wireless systems. With our expertise in AI-enabled communication networks, we’re the perfect partner for those seeking high-quality, value-driven optical-communication solutions. In this blog, we’ll dive deep into the evolving world of AI network architectures, focusing on the key debate of scale out vs scale up. We’ll explore predictions for 2028, highlighting trends in high throughput, high radix, high reliability, low latency, low power consumption, and low cost. For more on how FiberMall can support your AI networking needs with advanced optical interconnects, visit our official website or contact our customer support team.
AI networks are evolving rapidly, and understanding scale out vs scale up is crucial for future-proofing your infrastructure. In this post, we’ll predict the landscape for 2028, drawing from current trends and expert insights. Whether you’re scaling vertically (scale up) or horizontally (scale out), these architectures will shape the next generation of AI systems.
Executive Summary: Future AI Network Architecture Predictions
The future of AI networks will continue to evolve toward the “3 highs and 3 lows”: high reliability, high throughput, high radix; low cost, low latency, low power consumption.
AI network changes happen incredibly fast. Just a year ago, DeepSeek wasn’t in the spotlight, but now its domestic super-node networks have undergone massive transformations. From 2025 to 2028, who knows what hotter large models will emerge in those three years? Predicting AI network demands three years ahead is challenging. On the other hand, developing AI switch chips takes a three-year cycle, so we must have a clear vision of 2028’s AI networks to define chip requirements and specifications.
In the summer of 2025, the author attempts to forecast AI network architecture trends for 2028. In this fast-paced, innovation-driven environment, having ideas is better than none. It may not be 100% accurate, but getting the technical direction roughly right is key—we can refine it later.
Scale-Out (SO) Network Trends:
- Shift from 3-layer to 2-layer networking, enabling 2-layer CLOS for 100,000 cards in a single rail with multiple planes.
- 100T switch chip with Radix=512 supports 512×512/2=128,000 cards.
- 800G AI-NIC splits into multiple ports for multi-plane fat-tree networking (from DeepSeek paper).
- 800G NIC divided into 4x200G ports, accessing 4 independent planes. Single QP drives 4 ports with packet spray.
- Fusion of Scale-Out and Scale-Up, allowing one-layer CLOS for 100,000 cards (Huawei UB-Mesh paper).
Scale-Up (SU) Network Trends:
- 224G optical interconnects as the primary form, with intra-frame cable interconnects and inter-frame convergence.
- Intra-frame terminates with TP (cables), inter-frame uses EP (optical interconnects); intra-frame bandwidth/frame bandwidth = 2-4 times for convergence.
- Optical module monthly flap rate is 2.9%, 100 times less reliable than cables—requires black-box key technologies to resolve.
- Frame-based networking: Inter-frame one-time CLOS switching, 128-8,000 cards.
- First hop uses cable backplane interconnects, boosting reliability by 100 times.
- Few frames can use back-to-back, nD-Mesh, Torus, etc.
- Box-based networking: Inter-box one-time CLOS switching, 128-1,024 cards.
- Challenge: First hop is optical interconnect, with 100 times higher flap rate.
Fusion of Scale-Up and Scale-Out Networking:
- Primary benefit: Reliability improvement by over 10 times.
- Other benefits: Bandwidth sharing, cost reduction, reduced maintenance workload.
224G Optical Interconnect Trends:
- Optical links are 100 times less reliable than cable, requiring high-reliability link-level interconnect tech.
- Scale-Up networks primarily use 224G LPO/NPO; DSP is secondary.
- LPO/NPO are crucial for their 3 lows: a) 60% power savings; b) 120ns latency savings; c) cost savings.
- CPO isn’t essential and has ecosystem decoupling issues. LPO/NPO can replace CPO.
- Scale-Out networks stick with pluggable DSP, DPO/LRO as main forms.
- DSP-free LPO/XPO won’t be widely used due to interoperability issues.
- 224G optical interconnects have huge cost advantages over 112G, becoming mainstream.
- 50% fewer silicon photonics OEs, 50% fewer fibers, 50% fewer cable connectors. 224G per-bit cost is 2/3 of 112G.
- SU bandwidth is 10x SO; SU uses the most optical modules. Domestic GPUs can use 8:4 retimer to convert 112G electrical to 224G optical.
The rest of the article elaborates on these conclusions.
Current AI Network Status in 2025: Independent SU/SO/VPC Networking
The diagram [1] from the UEC forum shows AI interconnects with three networks: This document also introduces them.
Huawei CloudMatrix384 has revealed the current network structure for 910C, also with three independent networks: SU (LD/ST), SO (RDMA), and VPC.
Scale-Up Network
Used for both inference and training, mainly for TP model parallel traffic and EP expert parallel traffic. Current DeepSeek has 256 MoE experts, proposing 320-card large EP parallel for inference; Kimi K2 has 384 experts; future DeepSeek rumored to expand to 1,024 MoE experts. Current representatives: NVLink 72 cards; Huawei CloudMatrix 384 cards (as shown below):
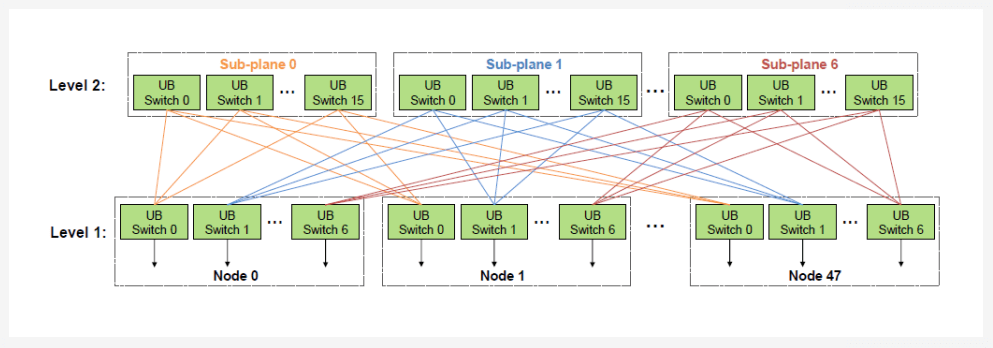
Scale-Out Network
Mainly for training’s DP/PP parallel. Current training scales to 100,000 cards. Networking uses AI-NIC or integrated NIC in AI chips. DP can be hierarchical: First converge with ReduceScatter in super-nodes, then to Scale-Out, further reducing SO bandwidth needs. Current representatives: HPN 7.0 (Sigcomm ’24 paper [3]), Tencent Xingmai network (Sigcomm ’25 paper [4]), features: 3-layer CLOS, 8 rails, NIC 2x200G dual planes.
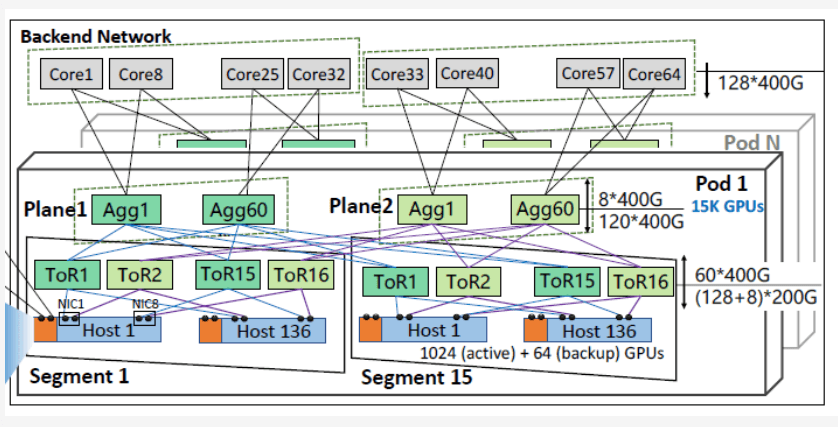
VPC Network
VPC network is DPU on CPU for VxLAN etc., connected to external storage. Currently three networks are separate; future will fuse, e.g., three-into-two or three-into-one. Usually current DCN: TOR+Spine+Core 3-layer CLOS.
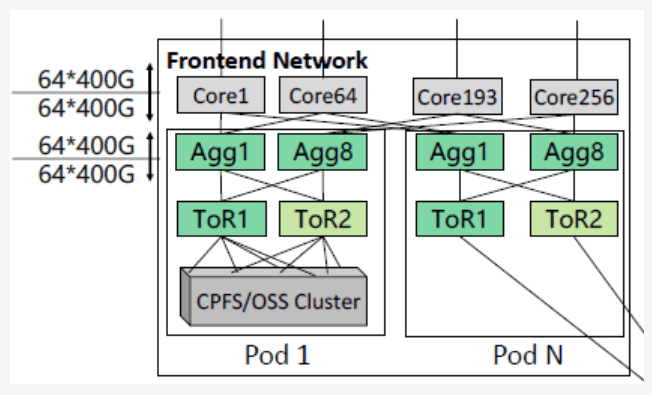
Future AI Network Design Principles
“3 Highs and 3 Lows” Principle
3 Highs: High throughput, high reliability, high radix. 3 Lows: Low cost, low latency, low power.
Data Locality Principle: Interconnect Bandwidth Converges Gradually
A rough formula from large model experts: TP = 5x EP = 50x DP = 100x PP.
Physical implementation:
- Rack bandwidth > super-node Scale-Up bandwidth > cluster Scale-Out bandwidth.
- TP terminates in rack with low-cost cables, max bandwidth.
- EP terminates in super-node with LPO/NPO optical modules, medium bandwidth, balanced cost/power.
- DP/PP in Scale-Out, min bandwidth, lowest cost. DP hierarchical: ReduceScatter in super-node first, then Scale-Out.
Simplified Switching Architecture Principle: Cluster 3-Layer to 2-Layer; Super-Node 2-Layer to 1-Layer
- Cluster SO: 3-layer to 2-layer, 2-layer 100,000 cards.
- Super-node SU: 2-layer to 1-layer, 1-layer 1,024 cards.
- “Simple Core, Smart Edge”: AI switches simplest, intelligence in edge AI-NIC/IO-Die.
- Large-scale DF+ variant architectures unlikely—too complex; CLOS is simple and flexible.
Insights into Scale-Out Network Architectures for 2028
Tencent Proposes 3-Layer to 2-Layer, 2-Layer 100,000 Cards
If Scale-Out remains independent, change: 3-layer to 2-layer, 2-layer 100,000 cards. This idea first from a Tencent colleague. Relies on Radix=512 switches. Huawei’s mass-produced 50T chip supports Radix=512 for 2-layer 100,000 cards.
Radix=512: 2-layer CLOS capacity = 512*512/2 = 131,072 cards. Single rail, no multi-rail.
For 100T switches in 2-layer 100,000 cards, each port 200GE. GPU Scale-Out typical bandwidth 800G, so 4 independent planes. AI-NIC splits traffic to 4 planes, per-packet load balancing, one QP drives 4 ports. Single rail + multi-plane, friendlier to MoE all2all.
From 3-layer to 2-layer CLOS: Each GPU saves 2 optical modules (6 to 4, -33%), switches save 2 ports (5 to 3, -40%).
256 cards access same switch single rail: Min latency and traffic conflicts.
Radix=512 requires passive shuffle: Fiber min granularity 4L, but 100T switches output 512x224G as 1-lane plugs. Solutions:
- External optical shuffle: 4×4 passive crossover, 1.6dB loss.
- Internal optical/electrical shuffle. Huawei 100T (2x50T) has cable shuffle. NVIDIA 400T CPO has internal passive optical shuffle with 4x100T chips, outputting 512x4L connectors, each to 4 switches.
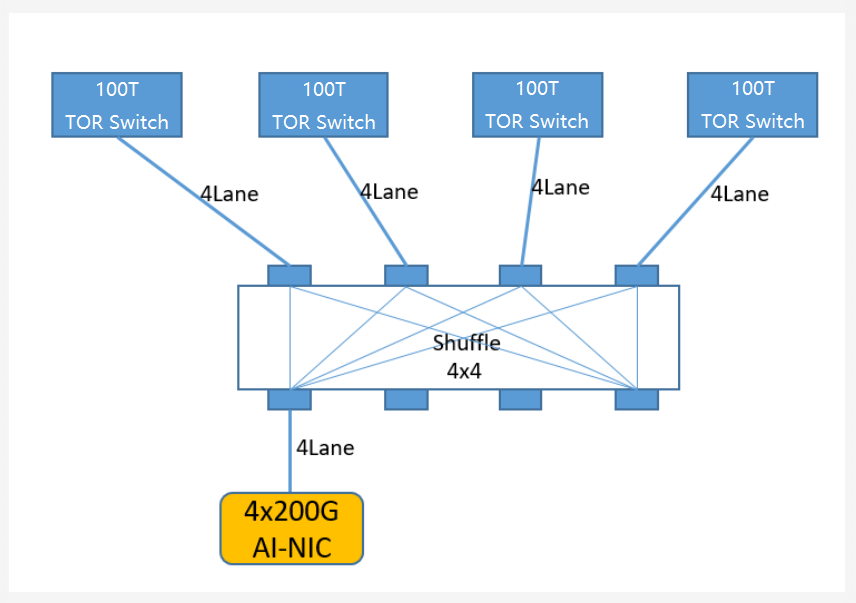
DeepSeek Proposes Multi-Port Multi-Plane, e.g., 800G NIC to 4x200G Ports
DeepSeek ISCA paper: Future Scale-Out is multi-plane, each NIC to 4 uplink planes. Ideally, one QP drives 4 planes.
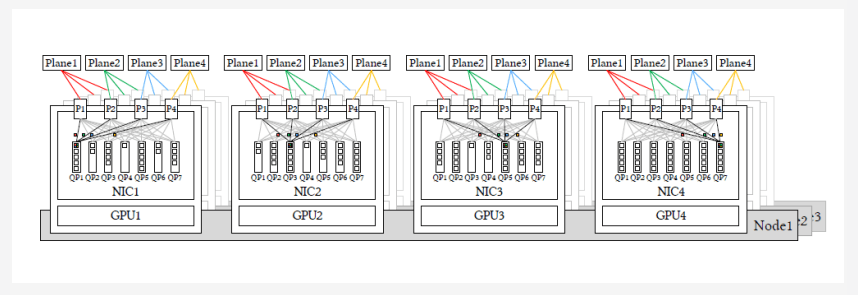
This 4-port NIC fits perfectly with 2-layer 100,000 cards: 100T switch splits to 512x200G ports, 800G AI-NIC to 4x200G for full bandwidth. 4 ports to 4 independent CLOS planes, each plane 100,000 ports (200GE/port).
Assumption: Future Scale-Out based on packet spray, not flow hash static routing. AI-NIC sprays packets round-robin to 4 planes. Receiver supports out-of-order, uses DDP for memory writes. Source/destination completion ordering with bitmap to confirm all data received.
Note: With Radix=512, DeepSeek’s multi-rail unnecessary.
Multi-rail expands capacity but unfriendly to MoE all2all. DeepSeek notes PXN from IB to NVLink consumes 20 SMs for data movement. DeepEP EP144 inference doesn’t use multi-rail.
Huawei UB-Mesh Proposes Scale-Up and Scale-Out Fusion, One-Layer 100,000 Cards
Huawei UB-Mesh fuses Scale-Out and Scale-Up, reducing one network. Not just talk—developed components like HRS 50T chip (512x112G), world’s first tri-network fusion for SU/SO, released National Day 2024, mass-produced 2025.
Assuming 1,024P super-node, add Scale-Out layer (e.g., UBoE RoCE switch): Expands to 1,024×128=120,000; 1,024×256=250,000; 1,024×512=500,000 cards.
Scale-Out 100T radix: 128, 256, 512 respectively. Note: Super-node 1,024 cards to 900 for 9:1 uplink, minor detail.
Insights into Scale-Up Network Architectures for 2028
Advantages and Disadvantages of Frame-Based Super-Node Scale-Up Switching
Advantages:
- High reliability: First hop cable backplane, 100x more reliable than optical modules—crucial for Scale-Up (say it three times!).
- Data locality convergence: Intra-frame electrical interconnect high-bandwidth; inter-frame optical with 2:1 or 4:1 convergence.
- Easy scaling: 8 frames=512 cards, 16=1,024. UB-Mesh supports 128 frames=8,000 cards, linear.
Disadvantages:
- Many cable trays, yield and processing challenges.
- Liquid-cooled cabinets require specific data centers.
- Intra/inter-frame two-level switching: 3 hops, high latency/cost.
Scale-Up frame networking starts with NVL72 frame, open-sourced to OCP. Domestic OTTs (Tencent ETH-X, Alibaba ALS, ByteDance Dayu) similar: a) 8-12 net boards; b) ~16 compute boards; c) Cable-tray backplane for 1-level CLOS intra-frame; d) Net board expansion ports for inter-frame (back-to-back or L2 switch).
- Tencent ETH-X: 8 Frames=512 Cards
Compute frame one-CLOS: Net board 50T chip, internal 64x400G to 64 XPUs; external 64x400GE (32 OSFP 800G modules) to L2 switch. Good scalability, but needs 2-level CLOS.
- ByteDance Dayu Cabinet: Single Frame 128 Cards, Back-to-Back Dual 256 Cards, L2 Expansion Potential
4-8 net boards, each 50T chip. Internal 128x200GE or 64x400GE; external 64x400GE (32x800G optical). Back-to-back DAC cables. Max 128 AI chips/frame, dual 256. Easy to add L2 like ETH-X for 512/1,024 cards.
- Alibaba ALS Cabinet
From “Partnering with UALink, Alibaba Cloud Panjiu AI Infra 2.0 Server Debuts at 2024 OCP Global Summit” [8]: Similar to NVL72/ETH-X, 64-80 AI chips thanks to UALink 288L/320L chips.
- Huawei UB-Mesh: 512-8,000 Cards
Per UB-Mesh paper, each frame 64 AI chips. Each chip UBx72 interface: 56L for X/Y Mesh, 16L out-frame for nD-Mesh or CLOS to external UB switch.
Capacity by frame count, max 8,000; also 256/512/1,024, linear cost. Only difference: Fiber length affects latency (100m=1us RTT).
One-Level CLOS Box-Based Super-Node: 512-1,024 Cards
Frame disadvantages? Solution: Box networking. AI systems spiral: From 8-card boxes to 64-card frames; now back to boxes.
Router folks know: Turn 16 line cards into 16 boxes, fiber to net board—long discussed, unrealized in routers but feasible in AI.
Switching benefits: 3-layer to 1-layer, lower interconnect cost/power than back-to-back dual cabinets.
Back-to-back: Each GPU 2 switch ports + expensive cable backplane. One-level box: 1 port. “3 Lows”: Low latency, cost, power.
Capacity by central switch radix: 100T=512x224GE=512 cards; 200T=1,024x224G=1,024 cards.
Why not 100T to 1,024x112G for 1,024 cards? Unsuitable for many reasons.
Disadvantage: Optical module reliability!
First hop optical: High flap rate. In frames, first hop cable; switch handles flaps. Huawei 50T SU/SO fusion switch excels at 0-packet-loss.
In box, XPU handles optical flaps directly—harder:
- Not all XPUs experienced in optical flaps.
- Switch 64 optical ports: Lose 1, 1/64 bandwidth loss. XPU 1 port loss: Major impact.
- Backup switching varies; limited backups, big performance hit.
Meta paper: AI-NIC to TOR with cable boosts reliability 100x over optical. Meta’s latest rack: SU/SO first hop cable backplane.
Future Networks: High-Reliability Optical Interconnect Tech and Trends
Status 1: Optical Flaps/Failures 100x Cable Fault Rate; Industry Uses Cables Where Possible
Super-node optical interconnects must solve reliability: Optical packet loss (incl. flaps) 100x+ cable backplane. OCP data [11]:

Optical faults: 1) Module failure (90% laser); 2) Link flaps (dirt from construction, bending).
Data:
- Link failure: HPN7.0: 0.057% NIC-ToR monthly.
- Flaps: OCP 50-100x higher; take 50x=2.9% monthly.
Consistent with experience.
NVIDIA GH200 256-card NVLink optical—unused; AWS used 32-card cable. Likely optical reliability issue.
512-card super-node: Each card 32L fiber=8x400G DR4.
LD/ST sensitive to loss; checkpoint rollback 20min unacceptable.
UALink: Max 4-frame cable, no optical yet.
Scale-Out: RDMA end-side retransmit (20s) covers 1-4s flaps via go-back-N.
Status 2: Huawei CloudMatrix384 and UB-Mesh Tackle Optical, Leading Reliability
NVIDIA NVL72/NVL576 cable. Optical in Scale-Up: Face 100x worse reliability.
SU LD/ST no full transport layer; flaps major. Huawei systematized solutions: Reduce faults 100x+, match/exceed cable.
CloudMatrix384: 6,912 modules (5,376 super-node). 2.9% flaps: 155/month=5.2/day.
Solutions: High-avail Nebula AI modules, switch Flex Packet-Routing 0-loss, NPU software.
Flex Packet Routing (in 50T UB-Mesh chip: 512x112G, tri-fusion, released 2024, mass 2025): Private handshake L1/L2 for flaps/faults=0 loss.
Load sharing: 64 fibers lose 1, packet spray to 63 via all L1s—1/64 loss, NPU unaware.
NPU first hop cable to L1: Feels no optical, high reliability.
Box systems: NPU direct optical=becomes L1; Flex in IO-die—higher complexity.
Why Fuse Scale-Up and Scale-Out? Main Benefit: 10x+ Reliability
Huawei first tri-fusion: UB-Mesh SO/SU fusion, 50T HRS mass-produced. UALink/SUE not yet; NVLink older, no fusion.
Benefits:
- SU/SO bandwidth unification: DeepSeek papers unify to avoid 20 SM data moves.
- Merge networks: Lower cost, maintenance.
- Boost SO reliability 10x+: Reuse SU’s cable+L1/L2 high-rel.
Examples:
- ETH-X first hop cable: 100x optical.
- Independent SO 2-layer 100k: NIC uplink optical—10x failure (laser), 100x flaps.
- ETH-X net board 64 optical: Lose 1=1.6% bandwidth.
- Independent SO: 800G NIC 4x200G=3+1 backup, lose 1=25%; dual-port=50%.
UB-Mesh supports fusion or separate; even VPC+SO merge. Customer choice.
LPO/NPO Best for Scale-Up
Post-CloudMatrix384 analyses: High module power. Quant: Domestic GPU 32x112G=4x800G end+4 switch.
DPO 800G=15W, 8x=120W. LPO=6W, 8x=48W.
Vs. 1,200W XPU: 4-10%—high? Depends.
LPO drops to 4%, meaningful.
2028: GPU interconnect doubles; LPO/NPO crucial for power reduction.
View: LPO/NPO optimal for 2028 Scale-Up by “3H3L”:
- Low cost: Remove oDSP saves ~$100/white-label (3nm oDSP pricey).
- Low power: oDSP 10%; LPO 4%.
- Low latency: No oDSP saves 60ns/direction; RTT 4 links=240ns.
- Reliability: 10°C lower temp doubles reliability. 800G LPO 6W vs. oDSP 15W; 1.6T LPO ~10W vs. 25W.
LPO/NPO drawbacks overcome in SU:
- Poor interoperability: Intra-super-node closed-loop, single vendor.
- BER 1-2 orders worse: SU link-level retransmit; post-correction 1E-10 sufficient.
DSP Pluggable Modules Remain Scale-Out Mainstream
DSP modules (800G/1.6T) mainstream for SO. LPO/NPO drawbacks hard in SO: Large scale (100k cards), multi-vendor; long distances no link-level retransmit (big buffers), higher BER needs.
LRO saves 50% DSP power, better interop/BER than LPO—suits 2028 SO.
Huawei collaborates for high-rel, low-power, low-latency optical.
224G Rate Superior to 112G by 2028
100T Ethernet chips: 1,024L112G or 512L224G. 2028: Which cost-effective?
1.6T=8x224G; 800G=8x112G.
Today: 1.6T >2x800G price. 112G reasonable now.
2028-30 forecasts: 1.6T=1.2-1.4x 800G (LPO/DSP). Clear advantage. 1.6T saves 1,000RMB vs. 2x800G; 100T system: 1,000×64=64,000RMB.
Plus double fibers for 112G. 224G wins. 2028: 1,024x224G=200T chips likely, not 112G.
Domestic GPUs 2024 112G? No issue: 910B/C 56G but 50T switch 512x112G. DSP retimer 8:4 converts 8x112G to 4x224G.
Box and Frame Super-Nodes Coexist
| Parameter | Modular Interface Card (64-Card Chassis Network) | Distributed Super Node (8-Card Quantum Networking) |
| Switching Levels | 2-Level CLOS | 1-Level CLOS |
| Switch Port Count | 1:3 | 1:1 |
| Optical Module Quantity | 1.2 | 1.2 |
| Interconnect Cost Comparison | 20% | 10% |
| Latency | Low (1-Hop Switch) | High (3-Hop Switch) |
| Reliability | High. GPU uses 1/2 network segment power Cable; When the switch fails, the GPU’s IO requires reconnection to handle the disconnection of optical ports. However, there is an issue with switch replacement. | Weak. The GPU’s IO requires reconnection to handle the disconnection of optical ports. |
| Load | High load, up to 8,000 cards | Low cost Supports air cooling |
| Node | High cost, requires liquid cooling machine room | Small scale, up to 512 cards |
Box: Low latency/cost/power. 32L/GPU: Frame 20% system cost; box 10%.
Frame: Larger scale, better reliability.
2028: Both coexist. Many prefer frame for intra-cable reliability.
Expert debates: If solve optical flap LD/ST reliability, go box; else frame.
UB supports both, excels in box with end-net synergy for 0-loss flaps. Box halves cost (20% to 10%)—attractive.
In conclusion, the scale up vs scale out debate in AI networks for 2028 revolves around balancing reliability, performance, and cost. Scale-up focuses on dense, reliable intra-super-node connects, while scale-out enables massive horizontal expansion. Fusion offers the best of both. At FiberMall, we’re at the forefront of these trends with our optical solutions tailored for AI. Visit our site for details on 224G LPO/NPO modules and more.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4A00 (980-9IAH1-00XM00) Compatible 1.6T OSFP DR8D PAM4 1311nm 500m IHS/Finned Top Dual MPO-12 SMF Optical Transceiver Module
$2600.00
-
NVIDIA Compatible 1.6T 2xFR4/FR8 OSFP224 PAM4 1310nm 2km IHS/Finned Top Dual Duplex LC SMF Optical Transceiver Module
$3100.00
-
NVIDIA MMS4A00 (980-9IAH0-00XM00) Compatible 1.6T 2xDR4/DR8 OSFP224 PAM4 1311nm 500m RHS/Flat Top Dual MPO-12/APC InfiniBand XDR SMF Optical Transceiver Module
$3600.00











