

800G SR8 and 400G SR4 Optical Transceiver Modules Compatibility and Interconnection Test Report
Version Change Log Writer V0 Sample Test Cassie Test Purpose Test Objects:800G OSFP SR8/400G OSFP SR4/400G Q112 SR4. By conducting corresponding tests, the test parameters meet the relevant industry standards, and the test modules can be normally used for Nvidia (Mellanox) MQM9790 switch, Nvidia (Mellanox) ConnectX-7 network card and Nvidia (Mellanox) BlueField-3, laying a foundation for

In-Depth Analysis Report on 800G Switches: Architectural Evolution, Market Landscape, and Future Outlook
Introduction: Reconstructing Network Infrastructure in the AI Era Paradigm Shift from Cloud Computing to AI Factories Global data center networks are undergoing the most profound transformation in the past decade. Previously, network architectures were primarily designed around cloud computing and internet application traffic patterns, dominated by “north-south” client-server models. However,

Why Is It Necessary to Remove the DSP Chip in LPO Optical Module Links?
If you follow the optical module industry, you will often hear the phrase “LPO needs to remove the DSP chip.” Why is this? To answer this question, we first need to clarify two core concepts: what LPO is and the role of DSP in optical modules. This will explain why

Global 400G Ethernet Switch Market and Technical Architecture In-depth Research Report: AI-Driven Network Restructuring and Ecosystem Evolution
Executive Summary Driven by the explosive growth of the digital economy and Artificial Intelligence (AI) technologies, global data center network infrastructure is at a critical historical node of migration from 100G to 400G/800G. As Large Language Model (LLM) parameters break through the trillion level and demands for High-Performance Computing (HPC)

Key Design Constraints for Stack-OSFP Optical Transceiver Cold Plate Liquid Cooling
Foreword The data center industry has already adopted 800G/1.6T optical modules on a large scale, and the demand for cold plate liquid cooling of optical modules has increased significantly. To meet this industry demand, OSFP-MSA V5.22 version has added solutions applicable to cold plate liquid cooling. At present, there are

NVIDIA DGX Spark Quick Start Guide: Your Personal AI Supercomputer on the Desk
NVIDIA DGX Spark — the world’s smallest AI supercomputer powered by the NVIDIA GB10 Grace Blackwell Superchip — brings data-center-class AI performance to your desktop. With up to 1 PFLOP of FP4 AI compute and 128 GB of unified memory, it enables local inference on models up to 200 billion parameters and fine-tuning of models
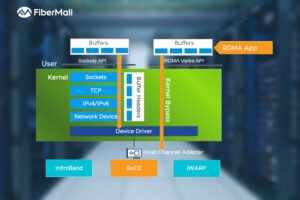
RoCEv2 Explained: The Ultimate Guide to Low-Latency, High-Throughput Networking in AI Data Centers
In the fast-evolving world of AI training, high-performance computing (HPC), and cloud infrastructure, network performance is no longer just a supporting role—it’s the bottleneck breaker. RoCEv2 (RDMA over Converged Ethernet version 2) has emerged as the go-to protocol for building lossless Ethernet networks that deliver ultra-low latency, massive throughput, and minimal CPU