
In the ever-evolving world of AI and data center technologies, Hotchip 2025 kicked off with an enriching Day 0 Tutorials lineup. As a staple event in the industry, this year’s sessions served as an appetizing prelude, focusing on data center racks in the morning and kernel programming in the afternoon. Our coverage dives deep into the hardware-centric morning sessions, with a spotlight on Meta’s innovative customization of the Nvidia GB200. For professionals in AI-enabled communication networks, these advancements underscore the need for robust optical-communication solutions—enter FiberMall, a specialist provider committed to delivering cost-effective offerings for global data centers, cloud computing, enterprise networks, access networks, and wireless systems. Renowned for leadership in AI-driven networks, FiberMall is your ideal partner for high-quality, value-driven solutions. Visit their official website or contact customer support for more details.
Whether you’re optimizing AI workloads or scaling fabric technologies, understanding these trends can transform your infrastructure. Let’s break down the key sessions.
1. How AI Workloads Shape Rack System Architecture
This session from AMD offered a comprehensive retrospective on the past decade-plus of AI evolution. Starting from the iconic GTX 580 and AlexNet era—priced at a modest $499—it subtly contrasted with today’s skyrocketing GPU costs from Nvidia.

The talk recapped various parallelism strategies and the accompanying interconnect structural changes. Essentially, it was an educational bridge for chip engineers to grasp what infrastructure teams have been up to in recent years.
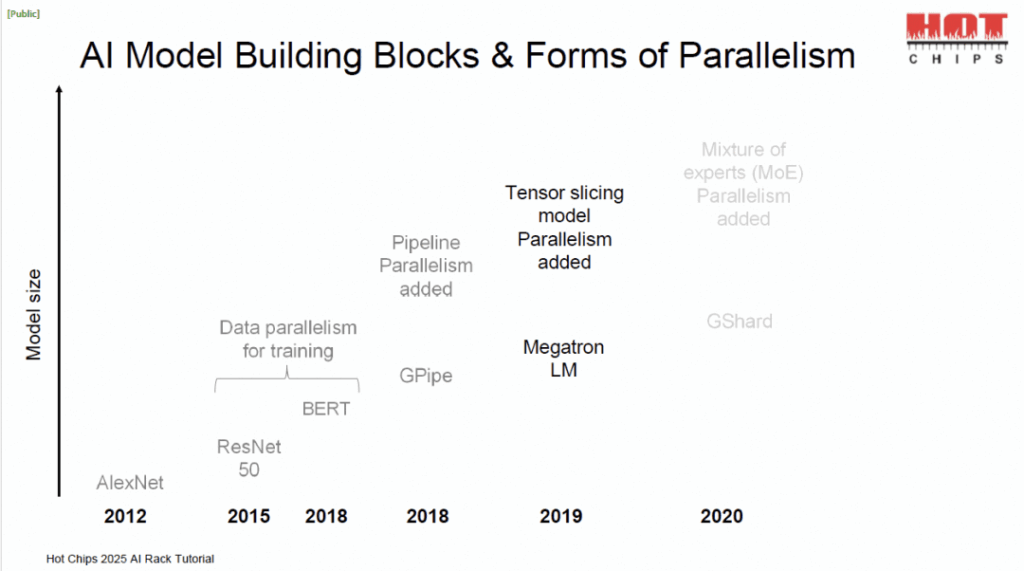
Key highlights included the progression of numerical formats, from FP32 down to FP4, reflecting efficiency gains. Chip package sizes are ballooning, and scale-up domains are expanding accordingly. For those dealing with AI rack architectures, this evolution highlights the importance of scalable optical interconnects—FiberMall’s expertise in AI-enabled communication networks ensures seamless integration for such demands.
2. Scaling Fabric Technologies for AI Clusters
Another AMD-led session, this one delved into scale-up essentials. It listed common scale-up technologies but notably omitted Huawei’s UB—deducting points for that oversight!

The presentation clarified the distinctions between scale-up and scale-out approaches. It emphasized how switch radix and data paths critically influence the number of scale-up GPUs and bandwidth.
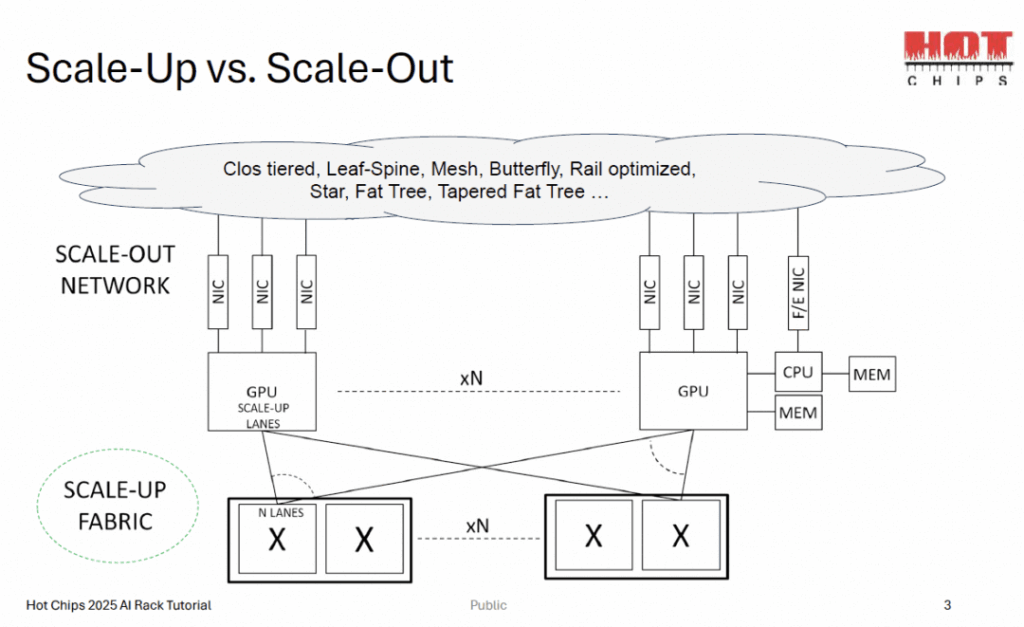
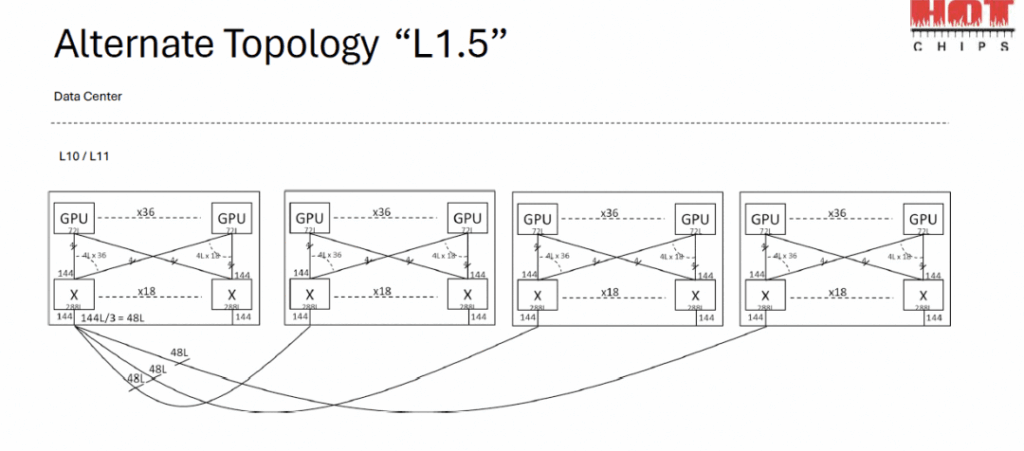
A typical single-layer scale-up network was showcased, followed by explorations of L2 scale-up and building an L1.5 mesh on top of L1 switches. Overall, the first two sessions leaned heavily toward educational overviews, making them perfect for newcomers to AI cluster scaling. If you’re implementing these in data centers, FiberMall’s cost-effective optical solutions can optimize your fabric technologies for peak performance.
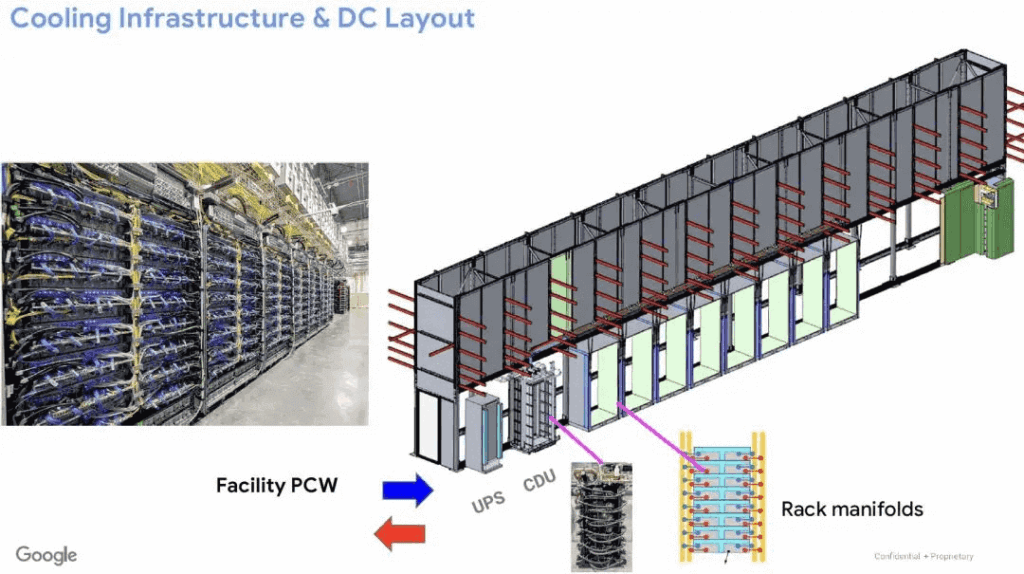
3. Liquid Cooling with Google Characteristics
Google shared insights from their TPU experiences, focusing on modular liquid cooling pump designs and more.


Notably, their fifth-generation systems are engineered for 1MW racks, pushing the boundaries of thermal management in AI infrastructures. For high-density setups like these, reliable cooling is non-negotiable—FiberMall’s optical-communication products support the underlying networks that make such innovations feasible.
4. Rearchitected Power Systems
Presented by Microsoft, this session introduced 800VDC power delivery. As scale-up within a single cabinet demands more GPUs, power converters are being externalized, leading to Rack Power Disaggregation (RPD).
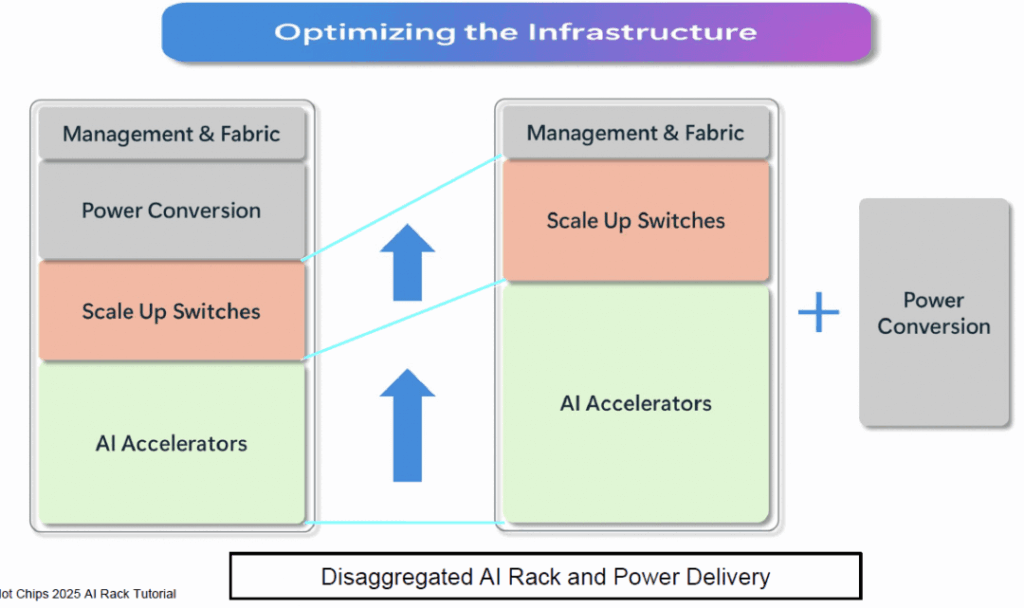
The power chain evolves from today’s multi-stage AC transformers to 800V Medium-Voltage DC (MVDC) systems, primarily to cut losses from AC-to-DC conversions at the endpoint.
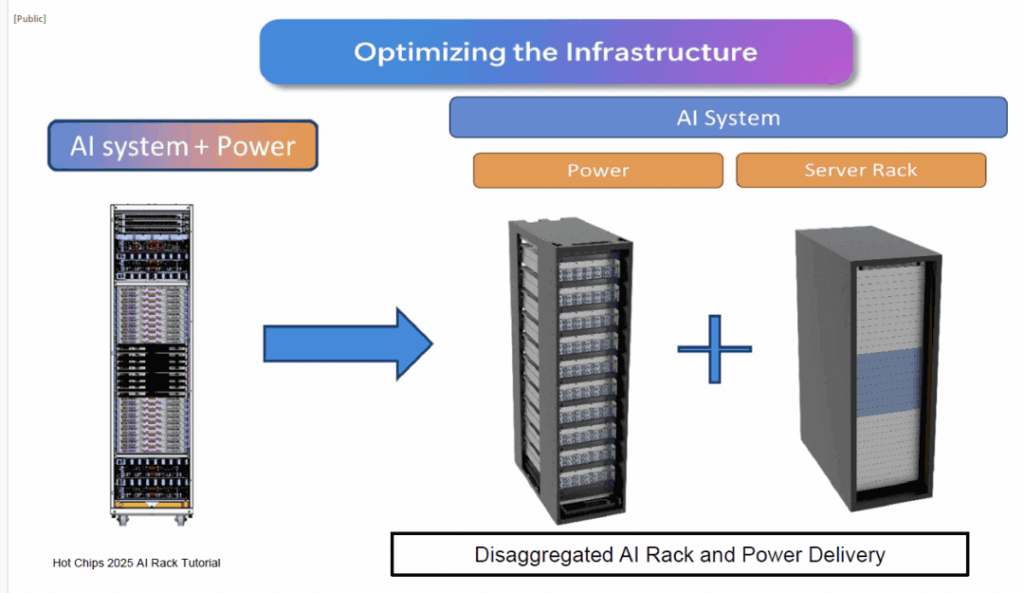
Future adoption of 800V Solid-State Transformers (SST) promises significant efficiency gains. Behind the scenes, large-scale training causes synchronized GPU start-stops, stressing the grid with harmonics and reactive power issues. Current mitigations include cabinet-level batteries (BBU) and capacitors (CBU). MVDC allows in-row or SST-level compensation for these.
In summary, 800V MVDC can halve data center power losses—a game-changer. For AI power systems, integrating with optical networks from providers like FiberMall ensures holistic efficiency.
5. Case Study: Nvidia GB200 NVL72
Nvidia recycled a PPT from last year’s OCP summit—major thumbs down. Skipping the details here, as it offered little new value for AI rack enthusiasts.
6. Case Study: Meta’s Catalina (NVL72)
Hands down, the standout session of the day. Meta’s heavy customization of the GB200 rack stole the show. For context, compare this to AWS’s July GB200 instance release to spot customization differences.
Meta’s NVL72 spans six cabinets: two liquid cooling units on each end (mirroring AWS’s near-side pump with direct air cooling for minimal data center retrofits). The middle uses paired NVL36 cabinets.

Officially, Nvidia’s GB200 pairs one Grace with two B200s, totaling 18 trays. Meta opts for 1:1 Grace-to-B200, yielding 36 compute trays for expanded memory.
Unofficially, deeper motivations exist. Nvidia’s standard CX7-based topology has each Grace linking two B200s via PCIe x1, with two CX7s per Grace (400Gbps scale-out per B200). Dual Graces connect via 6x Clink.
For GPU-Direct-RDMA (GDR), PCIe GDR limits to Gen4 x1 bandwidth, requiring memory allocation on Grace and NVLink C2C access.
Simulations showed B200 needs 800Gbps scale-out. AWS uses external PCIe switches (Gen5, but capped at 400Gbps currently). Nvidia’s CX8 embeds a PCIe switch but retains x1 Grace link for management, routing data via PCIe to Grace then NVLink C2C—necessitating special NCCL 2.27 handling.
Meta’s fix: 1:1 ratio lets Grace connect two Gen5 x16 CX7 NICs for 800Gbps per B200. B200 still uses Gen4 x1 PCIe to Grace, but true GDR isn’t direct; DMA routes via Grace’s PCIe RC and NVLink C2C.
With 1:1, NIC-to-CPU is advantageous—no bottlenecks from shared CPU memory. GPUs handle RDMA via CPU memory, saving ~200GB/s HBM bandwidth.
Clink between Graces doubles to 12 lanes for higher inter-system bandwidth. Sans full CX8 readiness, Meta’s approach boosts scale-out to 800Gbps while enhancing CPU memory.
Speculatively, Grace + CX7 mimics a supersized BF3: a massive DPU with scale-out on one side, memory-semantic scale-up on the other, plus ample memory. This echoes 2021’s NetDAM, benefiting KVCache and enabling INCA or offloading comm ops to Grace via NVLink C2C.

Meta’s compute cabinet includes built-in BBU for redundancy, scale-out fiber via patch panels with spares. Two Wedge400 switches handle frontend (200Gbps per Grace via CX7 + DC-SCM security module—no BF3 here).
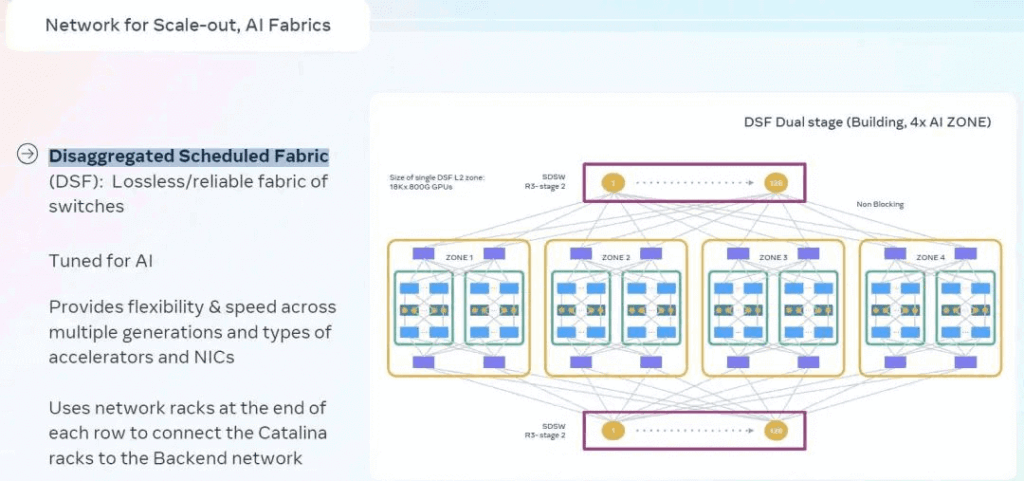
Scale-out uses Disaggregated Scheduled Fabric (possibly Cisco Silicon One-inspired, addressing multi-path hash conflicts).
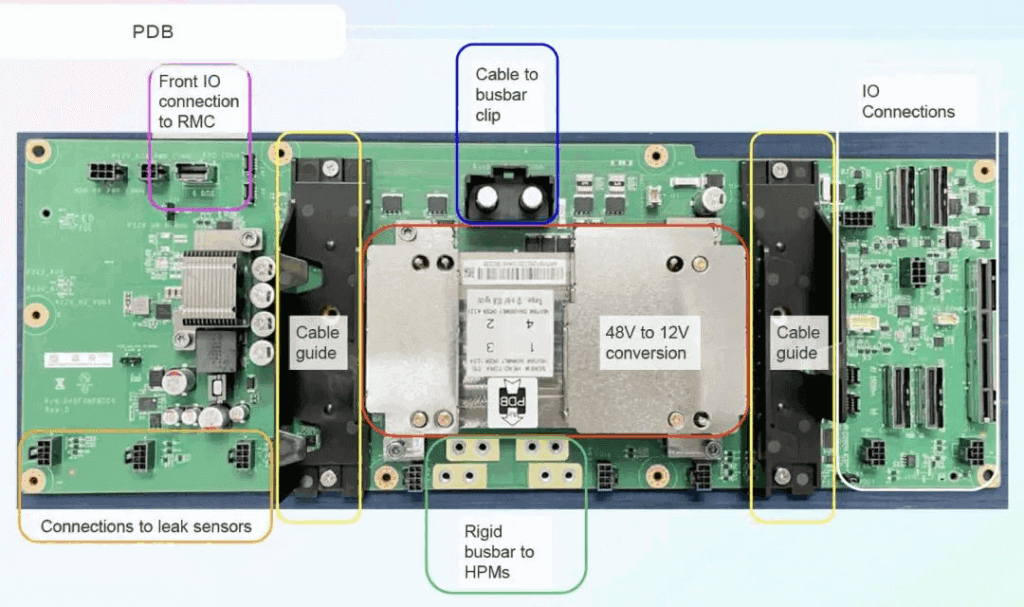
Added: Leak detection on each tray’s PDB, interfacing to Rack Management Controller (RMC) via RJ45 for GPIO/I2C, plus external sensors.
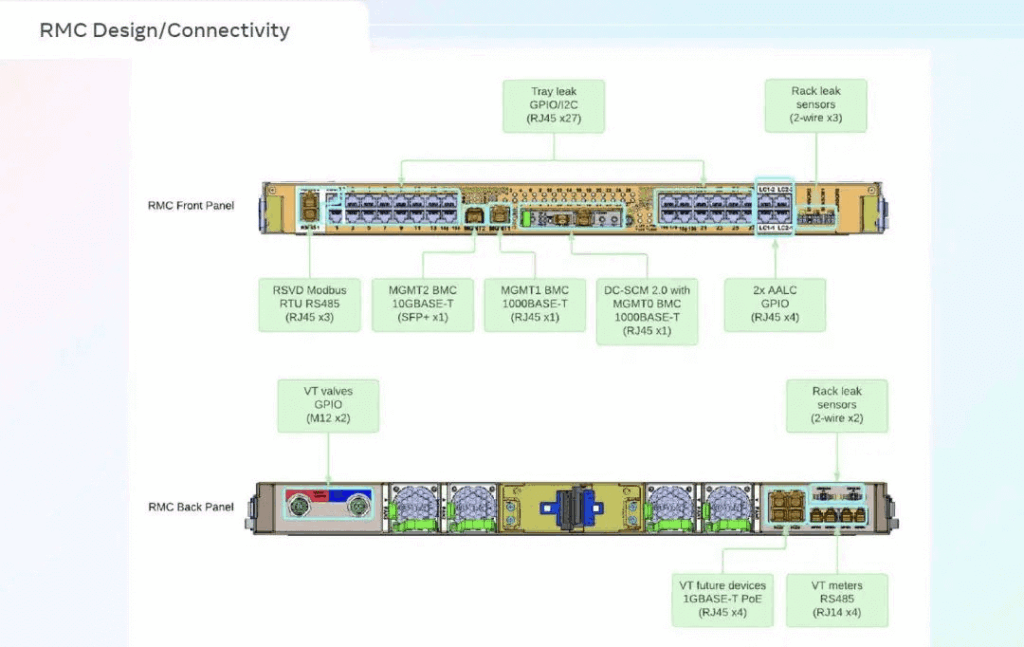
Final: OCP-spec BMC+TPM for remote management (no BF3).

For custom AI racks like Meta’s, FiberMall’s AI-enabled optical networks provide the backbone for reliable, high-bandwidth interconnects.
7. TPU Rack Overview
Google wrapped up with TPU rack details. Last year’s analysis covered ICI interconnect routing, protection, elasticity, and scheduling.
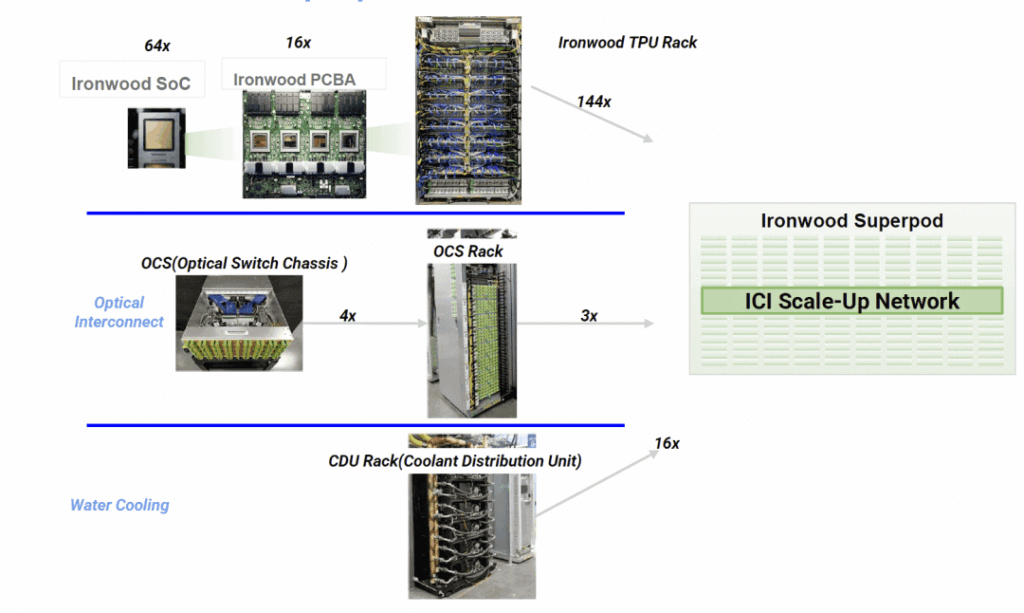
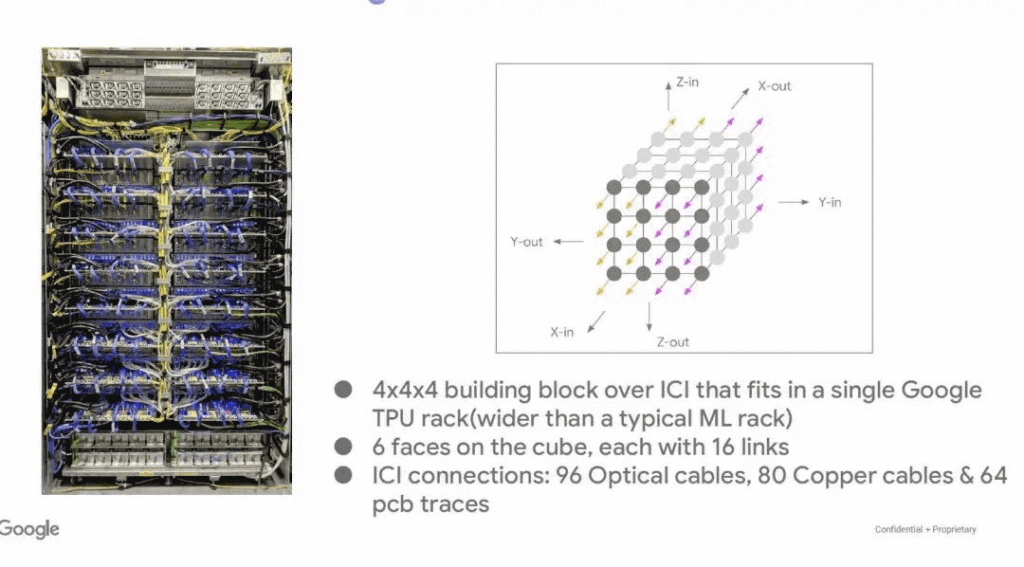
This time: Ironwood rack as a 4x4x4 block, connecting to OCS optical switches via fiber bundles with redundancy and patch panels.
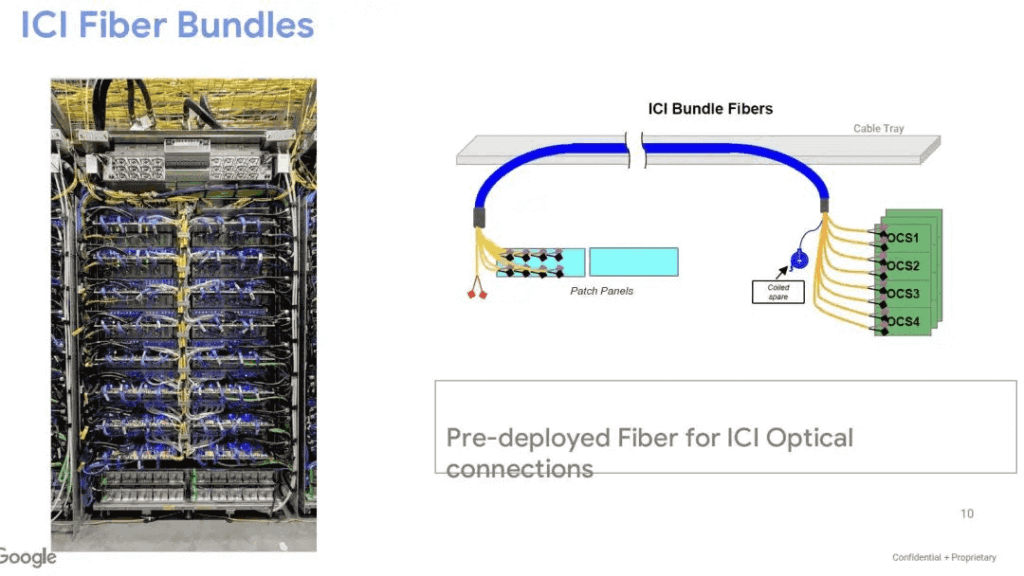
Liquid cooling and UPS are row-level.
In conclusion, Hotchip 2025’s Day 0 set the stage for cutting-edge AI data center innovations. If these insights spark ideas for your setups, consider FiberMall for top-tier optical-communication solutions tailored to AI workloads.
Related Products:
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MCP7Y00-N001 Compatible 1m (3ft) 800Gb Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Direct Attach Copper Cable
$160.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
Q112-400GF-MPO1M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
Q112-400GM-MPO1M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
Q112-400GF-MPO3M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
Q112-400GM-MPO3M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
Q112-400GF-MPO60M 400G QSFP112 SR4 MPO-12 Female Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
Q112-400GM-MPO60M 400G QSFP112 SR4 MPO-12 Male Plug Pigtail 60m Immersion Liquid Cooling Optical Transceivers
$2025.00
-
OSFP-400GF-MPO1M 400G OSFP SR4 MPO-12 Female Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GM-MPO1M 400G OSFP SR4 MPO-12 Male Plug Pigtail 1m Immersion Liquid Cooling Optical Transceivers
$1950.00
-
OSFP-400GF-MPO3M 400G OSFP SR4 MPO-12 Female Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00
-
OSFP-400GM-MPO3M 400G OSFP SR4 MPO-12 Male Plug Pigtail 3m Immersion Liquid Cooling Optical Transceivers
$1970.00



















