
The Core Battle in High-Performance Computing Interconnects
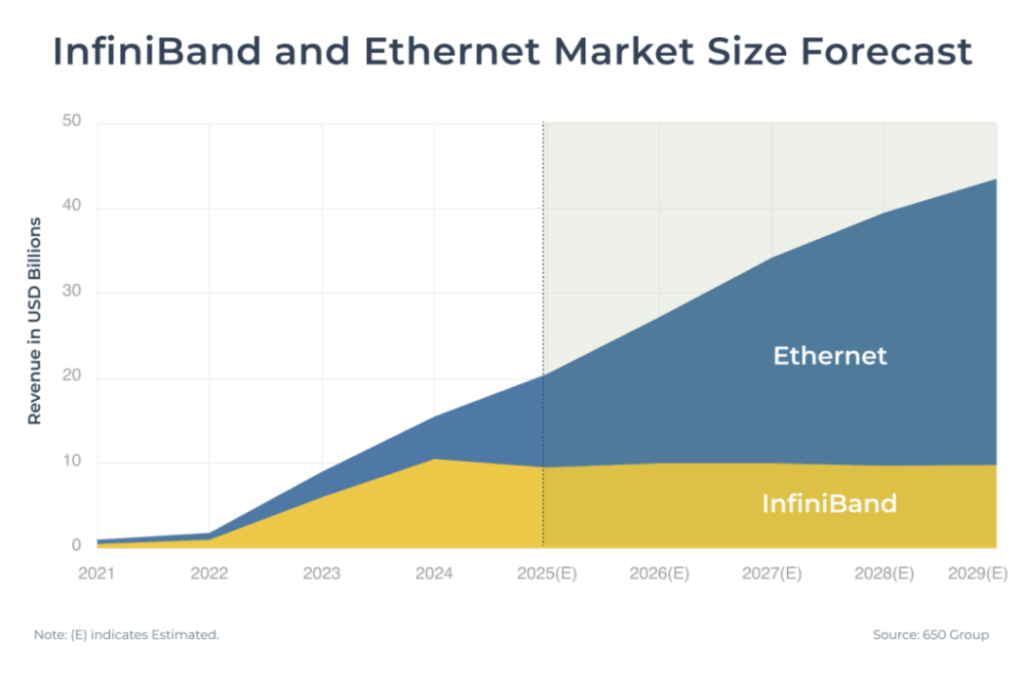
Ethernet is poised to reclaim mainstream status in scale-out data centers, while InfiniBand continues to maintain strong momentum in the high-performance computing (HPC) and AI training sectors. Broadcom and NVIDIA are fiercely competing for market leadership.
As artificial intelligence models grow exponentially in size, data center scaling has shifted from traditional vertical scale-up (single-system) architectures to massive horizontal scale-out architectures involving tens of thousands of interconnected nodes. The scale-out networking market is currently dominated by two competing technologies:
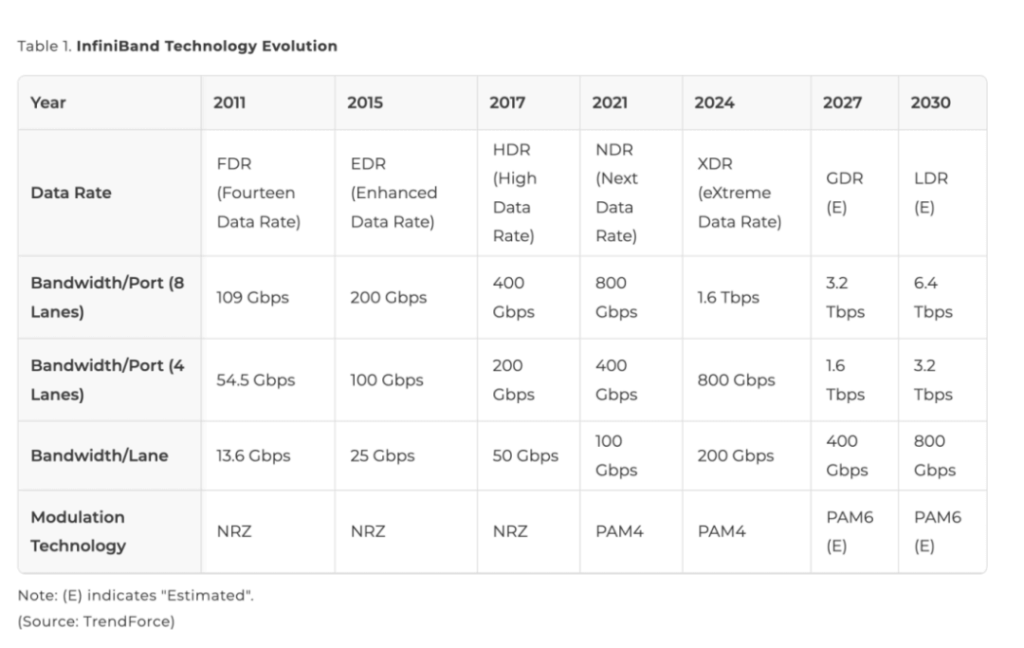
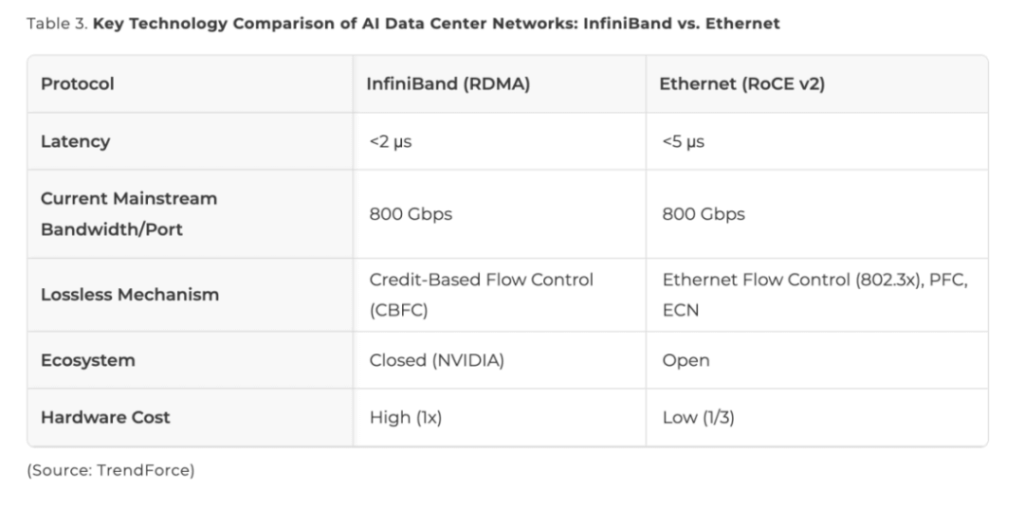
- InfiniBand: The long-standing performance leader, driven by NVIDIA’s subsidiary Mellanox, leverages native RDMA protocol to deliver ultra-low latency (sub-2 microseconds) and zero packet loss.
- Ethernet: Supported aggressively by Broadcom and others, it benefits from an open ecosystem and significantly lower cost.
In June 2025, Ethernet launched a powerful counterattack. The Ultra Ethernet Consortium (UEC) officially released the UEC 1.0 specification, which completely reconstructs the network protocol stack and achieves performance comparable to InfiniBand. With multiple advantages, Ethernet is expected to gradually expand its market share. This technological shift is reshaping the entire competitive landscape of the scale-out market.
Key Battlegrounds in Scale-Out: InfiniBand Advantages vs. Ethernet Counteroffensive
The mainstream scale-out InfiniBand architecture natively supports Remote Direct Memory Access (RDMA). Its working principle is as follows:
- During data transfer, the DMA controller sends data to an RDMA-capable network interface card (RNIC).
- The RNIC encapsulates the data and transmits it directly to the receiving RNIC.
- Because this process completely bypasses the CPU—unlike traditional TCP/IP—InfiniBand achieves extremely low latency (<2 µs).
Furthermore, InfiniBand employs credit-based flow control (CBFC) at the link layer, ensuring data is transmitted only when the receiver has available buffer space, thereby guaranteeing zero packet loss.
Native RDMA requires InfiniBand switches to function properly. For many years, these switches have been dominated by NVIDIA’s Mellanox division, resulting in a relatively closed ecosystem with higher procurement and maintenance costs—hardware costs are approximately three times those of equivalent Ethernet switches.
Thanks to its open ecosystem, numerous suppliers, flexible deployment options, and lower hardware costs, Ethernet has gradually gained widespread adoption.
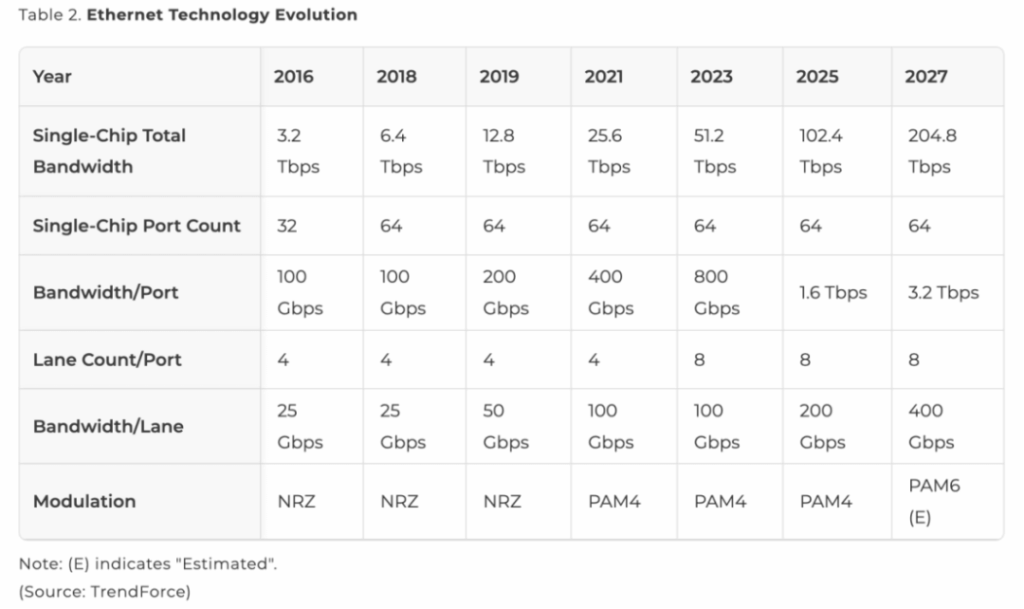
To bring RDMA capabilities to Ethernet, the InfiniBand Trade Association (IBTA) introduced RDMA over Converged Ethernet (RoCE) in 2010:
- RoCE v1: Simply added an Ethernet header at the link layer, restricting communication to the same Layer-2 subnet and preventing transmission across routers or different subnets.
- RoCE v2 (released in 2014): Replaced the InfiniBand Global Routing Header (GRH) in Layer 3 with IP/UDP headers. This change allows standard Ethernet switches and routers to recognize and forward RoCE packets, enabling cross-subnet and cross-router transmission and dramatically improving deployment flexibility.
However, RoCE v2 latency remains slightly higher than native RDMA (~5 µs) and requires additional mechanisms such as Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) to reduce packet loss risk.
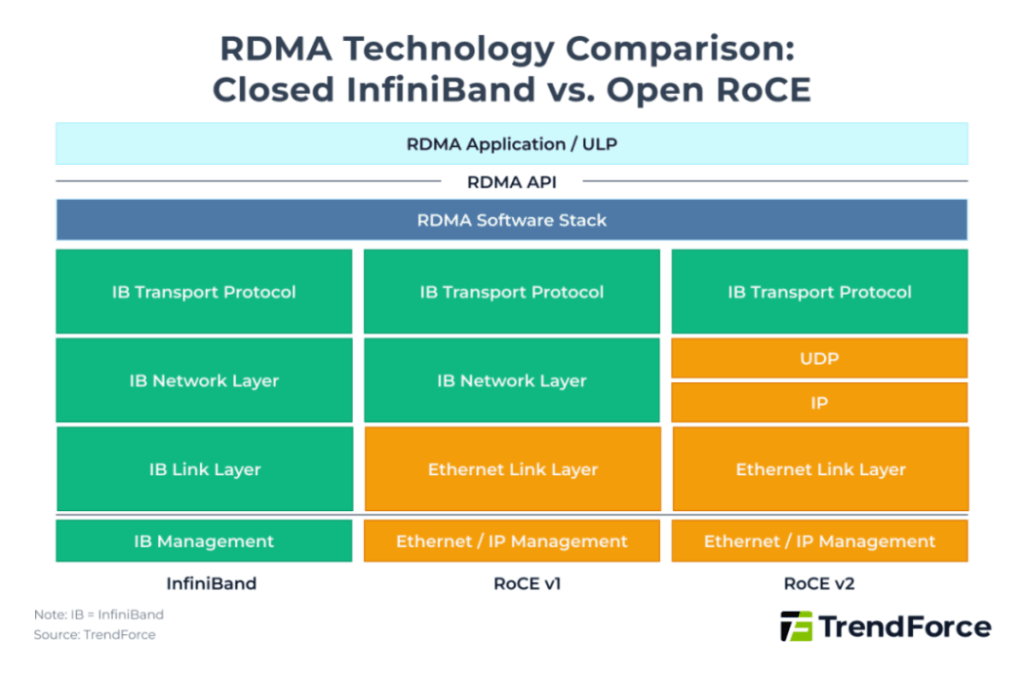
The comparison chart in the original document highlights the key differences between InfiniBand and open RoCE technology:
- InfiniBand uses a completely proprietary closed protocol stack to achieve the lowest possible latency.
- RoCE v1 simulates the InfiniBand architecture over Ethernet but is confined to the same Layer-2 subnet.
- RoCE v2 uses the IP network layer, supports cross-subnet communication, and offers the highest compatibility with existing Ethernet data center infrastructure.
InfiniBand retains inherent advantages in ultra-low latency and zero packet loss, making it the preferred choice in today’s AI data centers. However, its higher hardware and maintenance costs, combined with limited vendor options, are driving a gradual shift toward Ethernet-based architectures.
Driven by explosive AI data center demand and cost/ecosystem considerations, NVIDIA has entered the Ethernet market in force. In addition to its own InfiniBand Quantum series switches, NVIDIA now offers the Spectrum series Ethernet products.
In 2025:
- Quantum-X800: 800 Gbps/port × 144 ports = 115.2 Tbps total
- Spectrum-X800: 800 Gbps/port × 64 ports = 51.2 Tbps total
- CPO (Co-Packaged Optics) versions of Quantum-X800 and Spectrum-X800 are expected in the second half of 2025 and second half of 2026, respectively.
Although Spectrum switches are priced higher than competing Ethernet switches, NVIDIA’s strength lies in deep hardware-software integration (e.g., with BlueField-3 DPUs and the DOCA 2.0 platform) enabling highly efficient adaptive routing.
Switch ASIC Cost and CPO Deployment Race: Ethernet Leads, InfiniBand Follows Closely
In the Ethernet camp, Broadcom has consistently maintained technical leadership in Ethernet switch silicon. Its Tomahawk series follows the principle of “doubling total bandwidth approximately every two years.”
By 2025, Broadcom launched the Tomahawk 6—the world’s highest-bandwidth switch chip at the time—with 102.4 Tbps total capacity, supporting 64 × 1.6 Tbps ports. Tomahawk 6 also natively supports the Ultra Ethernet Consortium (UEC) 1.0 protocol, implementing multi-path packet spraying, Link-Layer Retry (LLR), and Credit-Based Flow Control (CBFC), further reducing latency and packet-loss risk.
Broadcom also leads in Co-Packaged Optics (CPO) technology:
- 2022: Tomahawk 4 Humboldt CPO version
- 2024: Tomahawk 5 Bailly
- 2025: Tomahawk 6 Davisson
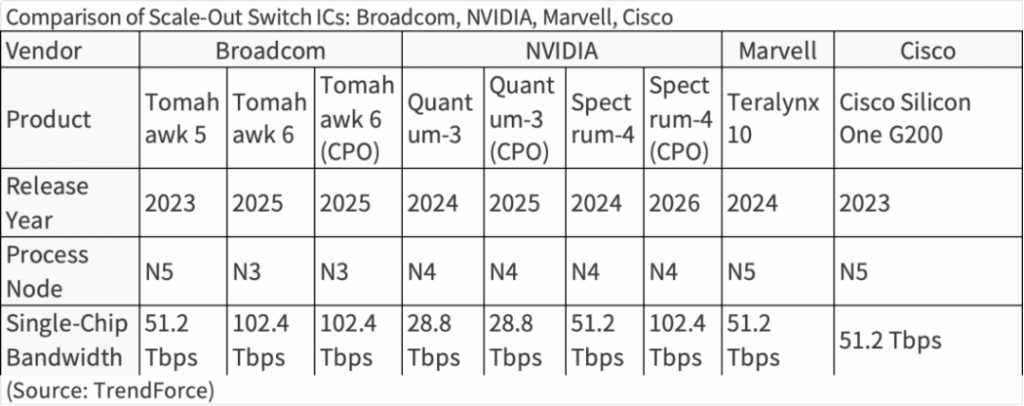
Compared with Broadcom’s 102.4 Tbps Tomahawk 6 launched in 2025, NVIDIA is not expected to release its 102.4 Tbps Spectrum-X1600 until the second half of 2026—roughly one year behind. NVIDIA’s 102.4 Tbps Spectrum-X Photonics CPO version is also scheduled for H2 2026.
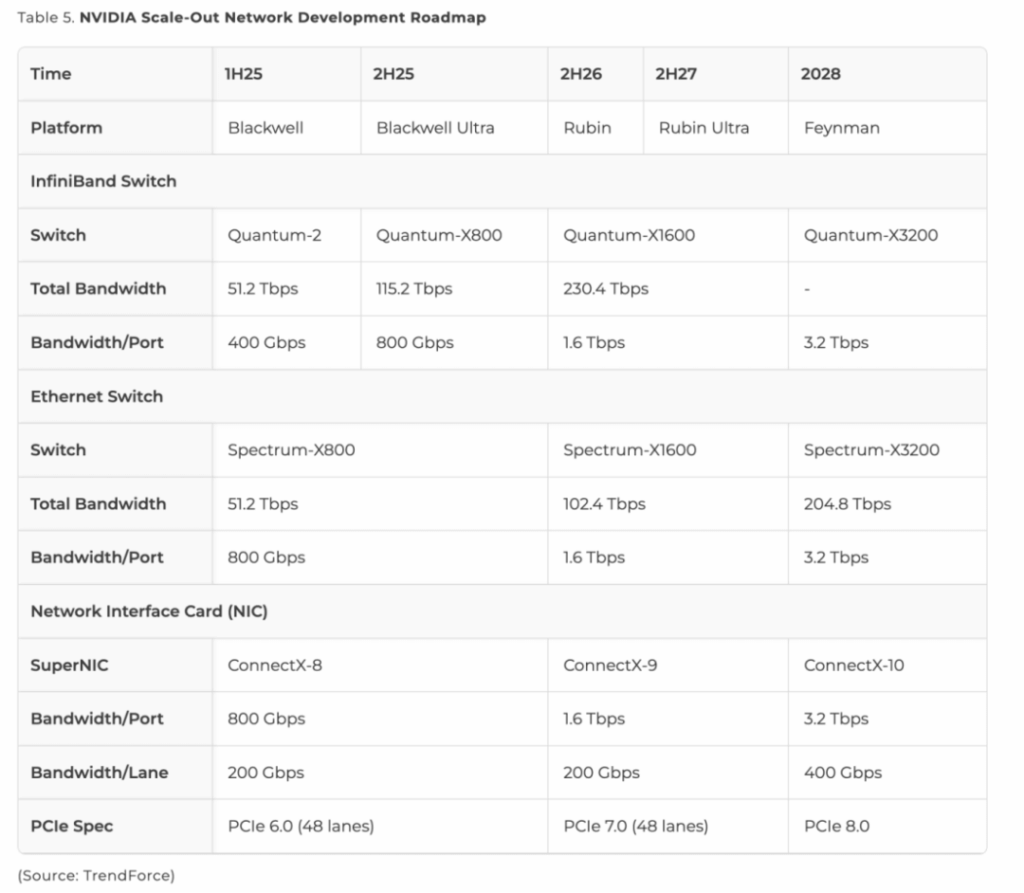
Beyond the Broadcom–NVIDIA duel:
- Marvell launched the 51.2 Tbps Teralynx 10 in 2023
- Cisco released the 51.2 Tbps Silicon One G200 series in 2023 along with CPO prototypes
Electrical Interconnects Reach Their Limit; Optical Integration Becomes the Focus
Traditional copper-based electrical interconnects are hitting physical limits. As transmission distances increase, optical fiber interconnects demonstrate clear advantages in scale-out scenarios: lower loss, higher bandwidth, stronger electromagnetic interference resistance, and longer reach.
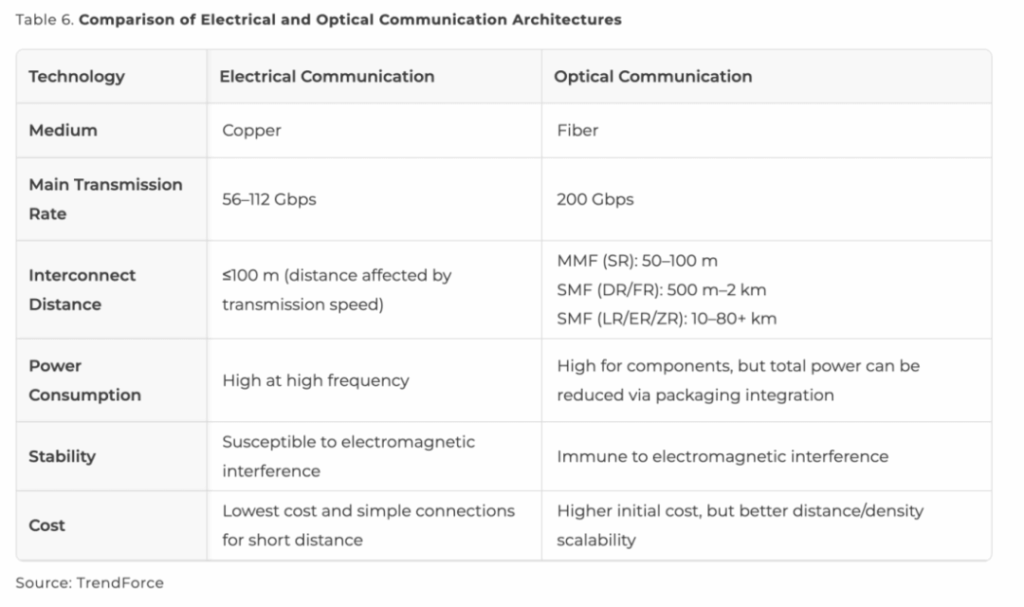
Current optical solutions primarily use pluggable transceivers, achieving single-lane 200 Gbps and aggregate 1.6 Tbps (8×200 Gbps).
As speeds rise, power consumption and signal loss on PCBs become severe. Silicon Photonics (SiPh) was developed to address these issues by integrating tiny transceiver components directly onto silicon, forming Photonic Integrated Circuits (PICs). These are then co-packaged inside the chip, shortening electrical paths and replacing them with optical paths—this is Co-Packaged Optics (CPO).
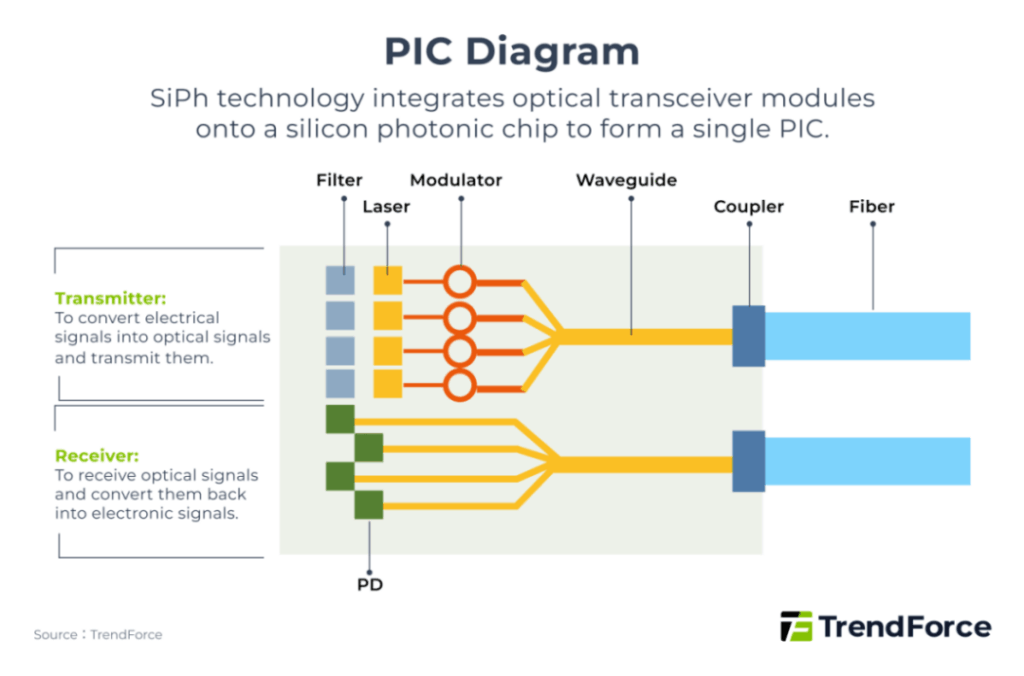
The broader CPO concept encompasses multiple forms: On-Board Optics (OBO), Co-Packaged Optics (CPO), and Optical I/O (OIO).
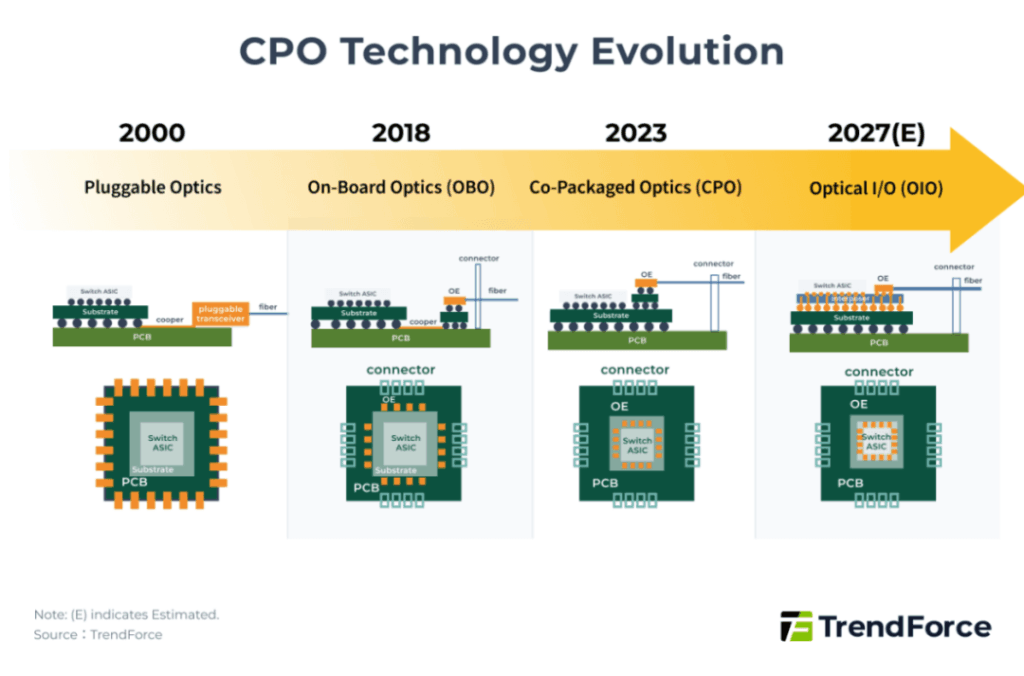
Optical engine (OE) packaging is moving ever closer to the main ASIC:
- OBO: OE on PCB (now rarely used)
- Narrow CPO: OE on substrate (current mainstream) → power <0.5× pluggable (~5 pJ/bit), latency <0.1× (~10 ns)
- OIO: OE on interposer (future direction) → power <0.1× (<1 pJ/bit), latency <0.05× (~5 ns)
CPO still faces challenges in thermal management, bonding, and coupling. As optical communication approaches its limits, breakthroughs in CPO and silicon photonics will determine the next competitive landscape.
The Ethernet Camp Rallies: UEC Promotes UEC 1.0 Standard
As mentioned earlier, InfiniBand captured significant share early in generative AI thanks to its ultra-low latency. However, Ethernet—the mainstream high-performance networking ecosystem—is also committed to achieving similar latency.
The Ultra Ethernet Consortium (UEC) was founded in August 2023 with initial members including AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta, and Microsoft. Unlike the NVIDIA-dominated InfiniBand ecosystem, UEC emphasizes open standards and interoperability to avoid single-vendor lock-in.
In June 2025, UEC released UEC 1.0—not merely an enhancement of RoCE v2, but a complete reconstruction of every layer (software, transport, network, link, and physical).
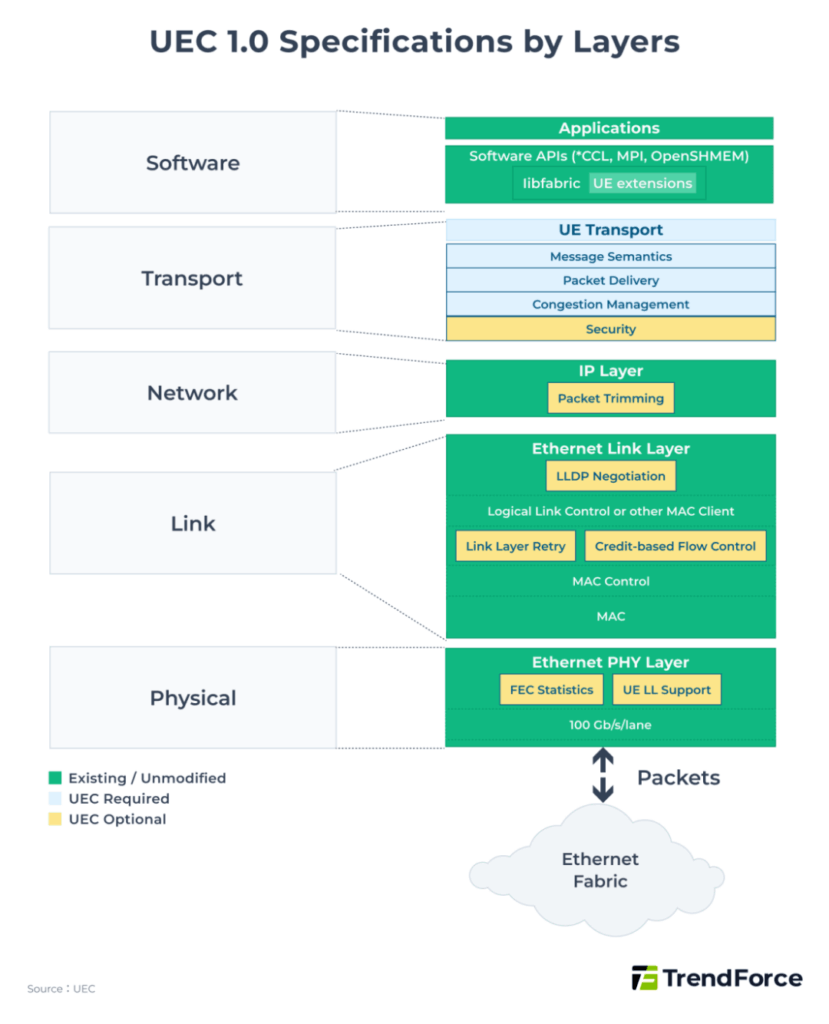
Key latency-reduction improvements include the Packet Delivery Sub-layer (PDS) in the transport layer, featuring:
- Multi-path transmission over multiple equal-cost, equal-speed paths (lanes/tracks)
- NICs use entropy to spray packets across all paths for maximum bandwidth
This multi-tier structure enables ultra-fast network recovery and near-InfiniBand adaptive routing.
To minimize packet loss, UEC 1.0 introduces two major mechanisms:
- Optional Link-Layer Retry (LLR): fast local retransmission request on packet loss, reducing reliance on PFC
- Optional Credit-Based Flow Control (CBFC): sender must obtain credits from receiver before transmitting, achieving true lossless behavior identical to InfiniBand CBFC
China’s Large-Scale Development: Coordinating International Standards with Independent Innovation
China’s AI infrastructure scale-out architecture is evolving along the dual principles of autonomy and international compatibility. While adhering to global Ethernet standards, major domestic enterprises are heavily investing in indigenous architectures, gradually forming distinctly Chinese scale-out systems.
Alibaba, Baidu, Huawei, Tencent, and many others have joined UEC to co-develop the standard. Simultaneously, they are independently developing scale-out fabrics that target low latency and zero packet loss, directly benchmarking InfiniBand.
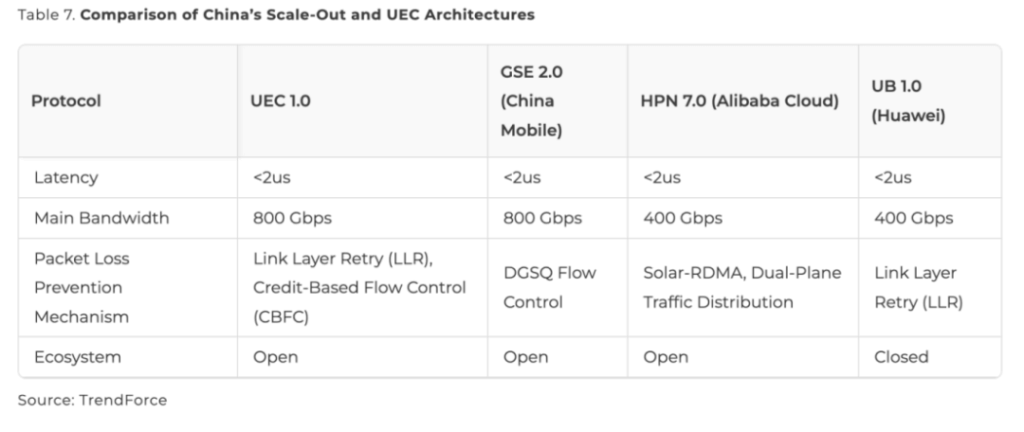
Notable indigenous architectures:
- China Mobile – GSE (General Scheduling Ethernet): Launched before UEC in May 2023. GSE 1.0 optimizes existing RoCE via port-level load balancing and endpoint congestion awareness. GSE 2.0 is a full protocol-stack rebuild with multi-path spraying and DGSQ flow control.
- Alibaba Cloud – High-Performance Network (HPN): HPN 7.0 uses “dual uplink + multi-lane + dual plane” design. Next-gen HPN 8.0 will feature fully in-house 102.4 Tbps 800G switch chips.
- Huawei – UB-Mesh interconnect: Deployed on Ascend NPU platforms using multi-dimensional nD full-mesh topology, supporting both scale-up and true scale-out at 3D+ dimensions.
With participation from ZTE, Accelink, and others, China is rapidly building a complete domestic optical module and silicon-photonics supply chain.
Next-Generation AI Data Centers: Technological Transformation and Opportunities
For many years, NVIDIA’s InfiniBand has dominated AI scale-out markets with sub-2 µs latency and zero packet loss. However, with the June 2025 release of UEC 1.0, Ethernet is rapidly closing the gap in latency and reliability while reclaiming competitiveness. Broadcom continues its two-year bandwidth-doubling cycle, relentlessly advancing Ethernet hardware performance.
As rates reach 1.6 Tbps and beyond, pluggable optics’ power and latency become bottlenecks, making CPO the future mainstream. Broadcom has led CPO deployment since 2022; NVIDIA plans InfiniBand CPO in H2 2025.
As Ethernet and CPO mature, AI data center networks are fully transitioning to high-speed optical interconnects, creating massive opportunities for optical transceivers and upstream supply chains (silicon-photonics chips, lasers, fiber modules).
In the scale-out domain:
- NVIDIA is expected to continue leading the traditional InfiniBand segment.
- Broadcom is poised to maintain dominant share in Ethernet via superior high-bandwidth ASICs, CPO leadership, and UEC implementation.
In August 2025, both NVIDIA and Broadcom unveiled “Scale-Across” concepts to extend connectivity across multiple data centers—the next paradigm in high-performance networking.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4A00 (980-9IAH1-00XM00) Compatible 1.6T OSFP DR8D PAM4 1311nm 500m IHS/Finned Top Dual MPO-12 SMF Optical Transceiver Module
$2600.00
-
NVIDIA Compatible 1.6T 2xFR4/FR8 OSFP224 PAM4 1310nm 2km IHS/Finned Top Dual Duplex LC SMF Optical Transceiver Module
$3100.00
-
NVIDIA MMS4A00 (980-9IAH0-00XM00) Compatible 1.6T 2xDR4/DR8 OSFP224 PAM4 1311nm 500m RHS/Flat Top Dual MPO-12/APC InfiniBand XDR SMF Optical Transceiver Module
$3600.00











