
In the era driven by artificial intelligence (AI) and machine learning, global data traffic is multiplying exponentially. Data center servers and switches are rapidly transitioning from 200G and 400G connections to 800G, 1.6T, and potentially even 3.2T speeds.
Market research firm TrendForce predicts that global shipments of optical transceiver modules exceeding 400G will reach 6.4 million units in 2023, approximately 20.4 million in 2024, and surpass 31.9 million by 2025, reflecting a 56.5% year-over-year growth. AI server demand continues to fuel the expansion of 800G and 1.6T modules, while traditional server upgrades drive 400G optical transceiver requirements.
Further surveys indicate that demand for 1.6T optical modules in 2026 will significantly exceed expectations, with total shipments projected to reach 11 million units. The primary drivers include strong procurement from NVIDIA and Google, supplemented by contributions from Meta, Microsoft, and AWS.
Optical communication, with its high bandwidth, low loss, and long-distance capabilities, is increasingly becoming the primary solution for intra- and inter-rack interconnections, positioning optical transceiver modules as critical components in data center connectivity. TrendForce emphasizes that future AI server data transmission will require vast quantities of high-speed optical transceiver modules. These modules convert electrical signals to optical signals for fiber transmission and reconvert received optical signals back to electrical signals.
01 What Is the Relationship Between Optical Transceiver Modules, Optical Communication, and Silicon Photonics?
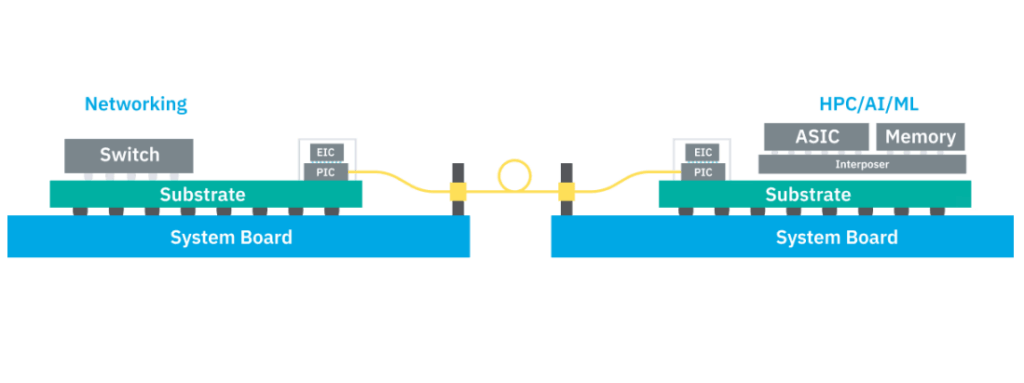
Based on the first two diagrams in the original figure, current pluggable optical transceivers on the market achieve speeds up to 800G. The next phase involves optical engines (Optical Engine, OE) installed around ASIC chip packages, known as On-Board Optics (OBO), supporting transmission up to 1.6T.
The industry aims to advance toward Co-Packaged Optics (CPO), where optical components are co-packaged with ASICs. This technology enables speeds exceeding 3.2T, up to 12.8T. The ultimate goal is “Optical I/O,” achieving full optical network-like capabilities with transmission speeds beyond 12.8T.
Close examination of the figure reveals that the optical communication module (previously pluggable, shown as a yellow block) is positioned increasingly closer to the ASIC. This proximity shortens electrical signal paths to enable higher bandwidth. Silicon photonics process technology integrates optical components directly onto chips.
02 Explosive Growth in Optical Communication Demand: Industry Focuses on Three Server Architecture Extensions
The AI application boom has dramatically increased demand for high-speed optical communication. Servers primarily emphasize Scale-Up (vertical scaling) and Scale-Out (horizontal scaling), each addressing distinct transmission needs and technical challenges. Recently, NVIDIA introduced the “Scale-Across” concept, adding a new dimension to industry considerations.
Scale-Up
Scale-Up focuses on high-speed intra-rack interconnections (yellow section in the figure), with transmission distances typically under 10 meters. Ultra-low latency requirements favor “copper interconnects” to avoid delays and power consumption from optical-electrical conversions. Current solutions include NVIDIA’s NVLink (proprietary architecture) and the open-standard UALink led by AMD and others.
Notably, NVIDIA launched NVLink Fusion this year, opening NVLink technology to external chip vendors for the first time. This extends NVLink from single-server nodes to rack-scale architectures, potentially in response to UALink competition.
Broadcom, traditionally focused on Scale-Out, is entering the Scale-Up market via Ethernet. The company recently introduced multiple chips compliant with Scale-Up Ethernet (SUE) standards. This development sets the stage for future NVIDIA-Broadcom competition, discussed later.
Scale-Out
Scale-Out enables large-scale parallel computing across servers (blue section in the figure), addressing high-throughput data and infinite scalability. Optical communication dominates here, with key interconnect technologies including InfiniBand and Ethernet, driving the optical module market.
InfiniBand and Ethernet form two major camps: the former favored by NVIDIA and Microsoft, the latter by Broadcom, Google, and AWS.
InfiniBand leadership stems from Mellanox, acquired by NVIDIA in 2019 as an end-to-end Ethernet and InfiniBand intelligent interconnect provider. Recently, China ruled that NVIDIA violated antitrust laws in this acquisition. NVIDIA offers numerous InfiniBand products but also Ethernet solutions like NVIDIA Spectrum-X, capturing both markets.
The opposing camp—Intel, AMD, Broadcom, and others—formed the Ultra Ethernet Consortium (UEC) in July 2023 to develop enhanced Ethernet transmission stacks, challenging InfiniBand.
TrendForce analyst Chu Yu-chao states that the optical communication module market driven by Scale-Out represents the core battlefield for future data transmission.
Scale-Across
As an emerging solution, NVIDIA proposed “Scale-Across” for long-distance inter-data center connections exceeding several kilometers. It launched Spectrum-XGS Ethernet, based on Ethernet, to link multiple data centers.
Spectrum-XGS serves as a third pillar beyond Scale-Up and Scale-Out for AI computing. It extends Spectrum-X Ethernet’s performance and scale, interconnecting distributed data centers, streaming large datasets to AI models, and coordinating GPU-to-GPU communication within centers.
This solution blends Scale-Out with cross-domain extension, flexibly adjusting load balancing and algorithms based on distance—aligning with Scale-Across.
NVIDIA founder and CEO Jensen Huang stated, “Building on Scale-Up and Scale-Out capabilities, we add Scale-Across to connect data centers across cities, countries, and continents, creating massive super AI factories.”
Industry trends show Scale-Up and Scale-Out as contested territories, with NVIDIA and Broadcom vying for market share. NVIDIA’s Scale-Across targets multi-kilometer to thousands-of-kilometers cross-data center transmission. Broadcom offers comparable solutions.
03 AI Chip Transmission to CPO Positioning War: What Exactly Are NVIDIA and Broadcom Competing For?

Understanding optical communication and the three data center extension architectures clarifies that the market watches not only AMD but also the rivalry between AI chip leader NVIDIA and communications chip giant Broadcom.
AI industry competition now extends beyond chips to system-level solutions.
Broadcom and NVIDIA’s first intersection is “custom AI chips” (ASICs). With NVIDIA GPUs being expensive, cloud service providers (CSPs) like Google, Meta, Amazon, and Microsoft develop in-house AI chips, partnering primarily with Broadcom for ASIC expertise.
Major CSP Self-Developed Chips
| CSP | AWS | Meta | Microsoft | |
| Product | TPU v6 Trillium | Trainium v2 、 Trainium v3 | MTIA 、 MTIA v2 | Maia 、 Maia v2 |
| Co-Packaged Partner | Broadcom 、 United Developers (TPU v7e) | Marvell (Trainium v2) 、 ChipCore-KY (Trainium v3) | Broadcom | Creative Intent (Maia v2) 、 Marvell (Maia v2 Advanced Edition) |
The second, more critical intersection is “network connectivity technology.”
In Scale-Up, protected by NVLink and CUDA moats, Broadcom launches the Tomahawk Ultra network switch chip this year to enter the market and challenge NVLink dominance.
Tomahawk Ultra is part of Broadcom’s Scale-Up Ethernet (SUE) initiative, positioned as an NVSwitch alternative. It connects four times more chips than NVLink Switch, fabricated on TSMC’s 5nm process.
Broadcom participates in the UALink consortium but promotes SUE based on Ethernet, raising questions about its competition-cooperation dynamics with UALink against NVLink.
To counter Broadcom, NVIDIA introduced NVFusion, opening collaboration with partners like MediaTek, Marvell, and Astera Labs for custom AI chips via the NVLink ecosystem. This semi-open approach strengthens the ecosystem while offering customization.
In Scale-Out, Ethernet veteran Broadcom dominates with products like Tomahawk 6 and Jericho4, targeting Scale-Out and longer distances.
NVIDIA counters with Quantum InfiniBand switches and Spectrum Ethernet platforms for broader Scale-Out coverage. Though InfiniBand is open, its ecosystem is largely controlled by NVIDIA’s Mellanox acquisition, limiting customer flexibility.

According to Broadcom’s image, three products span two server extension architectures.
For longer-distance Scale-Across, leadership is uncertain, but NVIDIA leads with Spectrum-XGS. It uses new network algorithms for efficient long-distance data movement, complementing Scale-Up and Scale-Out.
Broadcom’s Jericho4 aligns with Scale-Across, handling over 100km inter-site connections with lossless RoCE transmission—four times the prior generation’s capacity. Tomahawk series handles intra-data center rack connections under 1km (about 0.6 miles).
| Expansion Architecture | NVIDIA | Broadcom | AMD |
| Scale-Up | Obstacle Solution: NVLink (enclosed architecture) 、 NVFusion (semi-enclosed) | UALink (open architecture) 、 SUE | UALink (open architecture) |
| Solution Scheme: NVLink platform 、 NVSwitch platform 、 NVFusion solution scheme | Tomahawk Ultra 、 Tomahawk 6 (TH6) | Infinity Fabric (already integrated into UALink) | |
| Scale-Out | Obstacle Solution: InfiniBand obstacle 、 Existing Ethernet products | UEC (Ethernet obstacle) | UEC |
| Solution Scheme: Quantum InfiniBand platform 、 Spectrum-X/ Spectrum Z 、 Too-network switching platform | Tomahawk 6 、 Jericho4 | ||
| Scale-Across | Solution Scheme: Spectrum-XGS | Jericho4 |
04 NVIDIA and Broadcom’s CPO Solutions?
As network transmission battles intensify, optical network competition will escalate. NVIDIA and Broadcom seek CPO optical communication innovations, with TSMC and GlobalFoundries developing related processes.
NVIDIA’s strategy views optical interconnects as part of the SoC, not add-on modules. At this year’s GTC, it unveiled Quantum-X Photonics InfiniBand switches (launching year-end) and Spectrum-X Photonics Ethernet switches (2026).
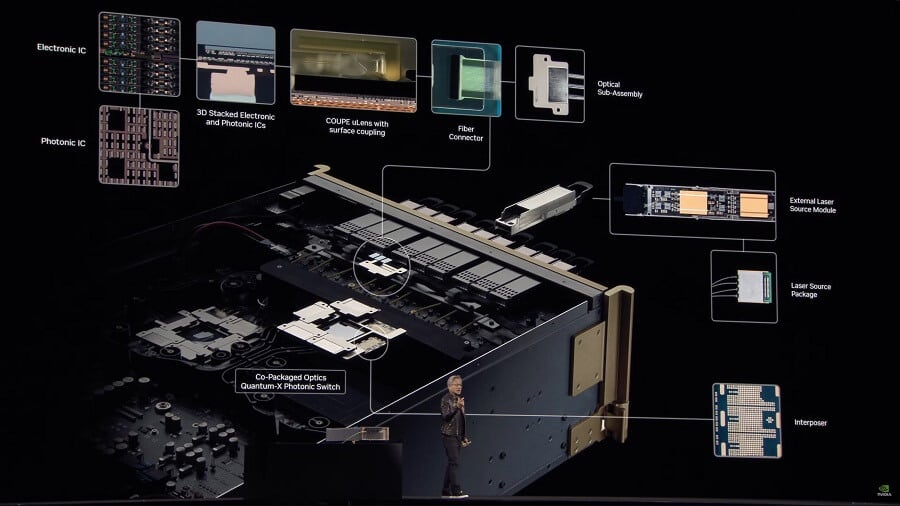
Both platforms use TSMC’s COUPE with SoIC-X packaging, integrating 65nm photonic integrated circuits (PIC) and electronic integrated circuits (EIC). This emphasizes platform integration for efficiency and scalability.
Broadcom focuses on comprehensive, scalable supply chain solutions for third-party clients. Its CPO success stems from deep semiconductor-optical integration expertise.

Broadcom launched third-generation 200G/lane CPO. It employs 3D chip stacking: 65nm PIC and 7nm EIC.
As shown in the figure, optical transceiver modules comprise key components: laser diodes (light sources), modulators (electrical-to-optical conversion), and photo detectors. Modulators determine per-lane speed.
Internal Components of Photonic Engine Modules
| Component Name | Function |
| Photodetector (PD, Photodetector) | Receives optical signals. |
| Waveguide (Waveguide) | Provides pathways for light propagation. |
| Optical Modulator (Optical Modulator) | Under electrical signal input conditions, converts electrical signals into optical signals. |
| Transimpedance Amplifier (TIA, Transimpedance Amplifier) | Amplifies current signals and simultaneously converts current signals into voltage. |
| Driver IC (Driver IC) | Provides electrical signals required by the optical modulator. |
| Switch (Switch) | Handles routing, switching of electrical signals, and allocates from which track to output. |
NVIDIA selects Micro-Ring Modulators (MRM)—compact but sensitive to errors and temperature, posing integration challenges.
Broadcom uses mature Mach-Zehnder Modulators (MZM) while developing MRM, achieving 3nm process trials and leading CPO via chip stacking.

Amid expanding AI inference, focus shifts from “computing power race” to “data transmission speed.” Whether Broadcom’s network/switch emphasis or NVIDIA’s end-to-end solutions prevail in breaking efficiency and latency barriers will determine the next AI competition leader.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4A00 (980-9IAH1-00XM00) Compatible 1.6T OSFP DR8D PAM4 1311nm 500m IHS/Finned Top Dual MPO-12 SMF Optical Transceiver Module
$2600.00
-
NVIDIA Compatible 1.6T 2xFR4/FR8 OSFP224 PAM4 1310nm 2km IHS/Finned Top Dual Duplex LC SMF Optical Transceiver Module
$3100.00
-
NVIDIA MMS4A00 (980-9IAH0-00XM00) Compatible 1.6T 2xDR4/DR8 OSFP224 PAM4 1311nm 500m RHS/Flat Top Dual MPO-12/APC InfiniBand XDR SMF Optical Transceiver Module
$3600.00











