
Overview
Artificial Intelligence (AI) has undoubtedly become a central topic within the field of information technology, captivating widespread attention at an unprecedented pace over the past three decades. This assertion is supported by a Futurum Group survey involving over 100 Chief Information Officers (CIOs) from Fortune 500 and Global 2000 companies. According to the results, nearly 80% of respondents are currently running AI pilot programs. Furthermore, the study identified that over 50% of these IT leaders view implementing emerging technologies, such as AI, as their most significant challenge. Additionally, modernization, innovation, and AI adoption consistently rank among the top five factors influencing IT procurement decisions.

This article delves into an in-depth analysis of the Intel® Gaudi® 2 AI accelerator and its potential impact on enterprises. The study contrasts the performance of the Intel® Gaudi® 3 AI accelerator with that of a leading competitor during inference workload tests. These tests focused on two distinct Llama 3.1 large language models (LLMs). To provide IT and business executives with practical and actionable insights, a specialized AI testing platform was developed to run and measure AI workload performance. This research was conducted in collaboration with Kamiwaza (https://www.kamiwaza.ai/), a commercial AI inference platform. Together, we designed an AI testing suite leveraging the Kamiwaza stack, capable of accurately measuring the inference performance of AI LLMs across various hardware and software platforms.
Key Findings:
- In a series of LLM inference tests, Intel Gaudi 3 demonstrated comparable performance to Nvidia H100.
- The performance of Intel Gaudi 3 relative to H100 varied, ranging from 15% lower to 30% higher, depending on the scenario.
- Intel Gaudi 3 outperformed H100 in inference sessions with small inputs and large outputs, whereas Nvidia excelled in sessions involving large inputs and small outputs.
- When factoring in cost, Intel Gaudi 3 achieved a higher workload per dollar compared to Nvidia H100, with an advantage ranging from 10% to 2.5x.
Enterprise AI Landscape
Although AI has become a focal point for many companies over the past year, the majority of enterprises are still in the early stages of AI application. As companies embark on pilot projects, they primarily focus on leveraging enterprise data and other knowledge sources to enhance existing foundational large language models (LLMs) for production environments.
Concerns over data privacy and governance remain significant, which is one reason why many companies, in addition to adopting cloud solutions, are exploring the deployment of AI tools locally. Maintaining control over training data and runtime inference datasets, as well as establishing effective governance frameworks and ethical AI practices, necessitates greater control over data, toolchains, and infrastructure. While single-interaction session inferences can be achieved with minimal hardware, large-scale deployments typically require hardware accelerators, especially when utilizing techniques such as retrieval-augmented generation (RAG). Therefore, enterprises should carefully assess the price and performance of their inference workloads when selecting AI accelerators, as this directly impacts the overall return on investment (ROI) once AI applications reach the production stage.
In the realm of enterprise AI deployments, where scalability and interconnectivity are paramount, the integration of high-speed networking technologies plays a crucial role in optimizing performance for accelerators like Intel Gaudi3 and Nvidia H100. For instance, leveraging 400G and 800G Ethernet solutions, alongside NDR InfiniBand for ultra-low latency data transfer, enables seamless clustering of multiple accelerators, ensuring efficient handling of massive datasets during inference workloads. FiberMall, as a specialist provider of optical-communication products and solutions, excels in delivering cost-effective 400G and 800G transceivers and cables tailored for AI-enabled networks, supporting data centers and cloud environments with unparalleled bandwidth. This not only enhances the overall throughput in distributed AI systems but also addresses bottlenecks in real-time processing, making it an ideal choice for enterprises seeking to maximize ROI on their Gaudi3 or H100 investments.
LLM Inference
The process of generating useful results from training models using LLMs is known as inference. LLM inference typically consists of two stages: prefill and decode. These two stages work in tandem to generate responses to input prompts.
Firstly, the prefill stage converts text into AI representations, known as tokens. This tokenization process usually occurs on the CPU, and the tokens are then sent to the AI accelerator to generate output and perform decoding. The model continues to iteratively execute this process, with each new token influencing the generation of the next token. Ultimately, at the end of this process, the generated sequence is converted back from tokens to readable text. The main tools used for this process are specialized software stacks optimized for inference. Some typical examples include the open-source project vLLM, Hugging Face’s TGI, and specialized versions for specific AI accelerators. Nvidia offers an optimized inference stack called TensorRT-LLM, while Intel provides an optimized software stack known as Optimum Habana.
Mapping Test Cases to Enterprise Applications
Our testing focuses on four distinct combinations or workload patterns characterized by the size of input and output tokens. Generally, these combinations aim to simulate different real-world scenarios that enterprises may encounter during production deployments. In actual usage, the size of input and output tokens may not precisely align with any single combination, as their range is quite broad. However, these four combinations are designed to illustrate potential scenarios.
Typically, small-token input scenarios correspond to brief input commands lacking extensive context, such as interactive chat. Using retrieval-augmented generation (RAG) adds substantial context and tokens to the input, resulting in longer input tokens and shorter output tokens during chat sessions. In iterative optimization for content creation or document/code writing with RAG, workloads are generated with long input and output tokens. Our analysis of common scenarios indicates that the combination of long-context inputs and outputs is the most likely scenario, while chat sessions without RAG are the least likely. The remaining two scenarios represent other possible use cases. The estimated percentages are based on discussions with customers and our own experience with LLMs.
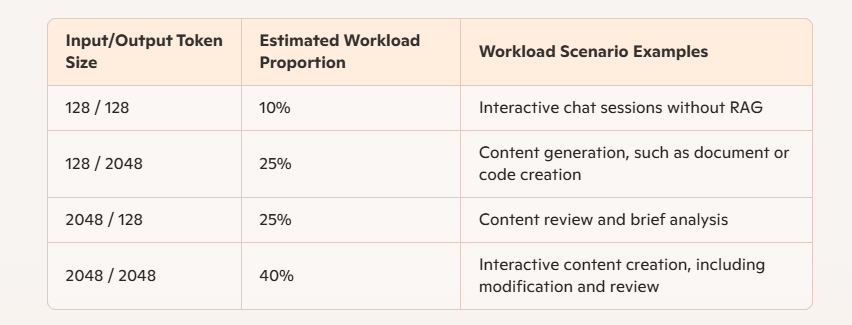
Table 1: Inference workload types and their proportions
As shown in Table 1, the two scenarios with longer output jointly account for 65% of total usage, while the two scenarios with shorter output represent the remaining 35%. This distinction is crucial as Intel Gaudi 3 performs better than Nvidia H100 when handling workloads with larger output tokens. Moreover, for the most common workloads in enterprises, the Gaudi 3 accelerator demonstrates performance advantages over Nvidia H100. Next, we will present the detailed results of these workloads and provide corresponding price/performance comparisons.
AI Inference Test Review
To efficiently process input data and submit it to AI accelerators, inference software converts the input data into tokens and then sends these tokens in batches to improve the overall token processing rate.
As previously mentioned, multiple LLM inference stacks are available. Our surveyed inference frameworks include the following:
- TGI: Suitable for H100 and Gaudi 3
- vLLM: Suitable for H100 and Gaudi 3
- Nvidia H100: Nvidia’s TensorRT-LLM inference stack
- Intel Gaudi 3: Optimum Habana inference stack
Note: We selected the optimal solution for each accelerator. For the Nvidia H100 tests, we used TensorRT-LLM, and for the Intel Gaudi 3 tests, we used Optimum Habana.
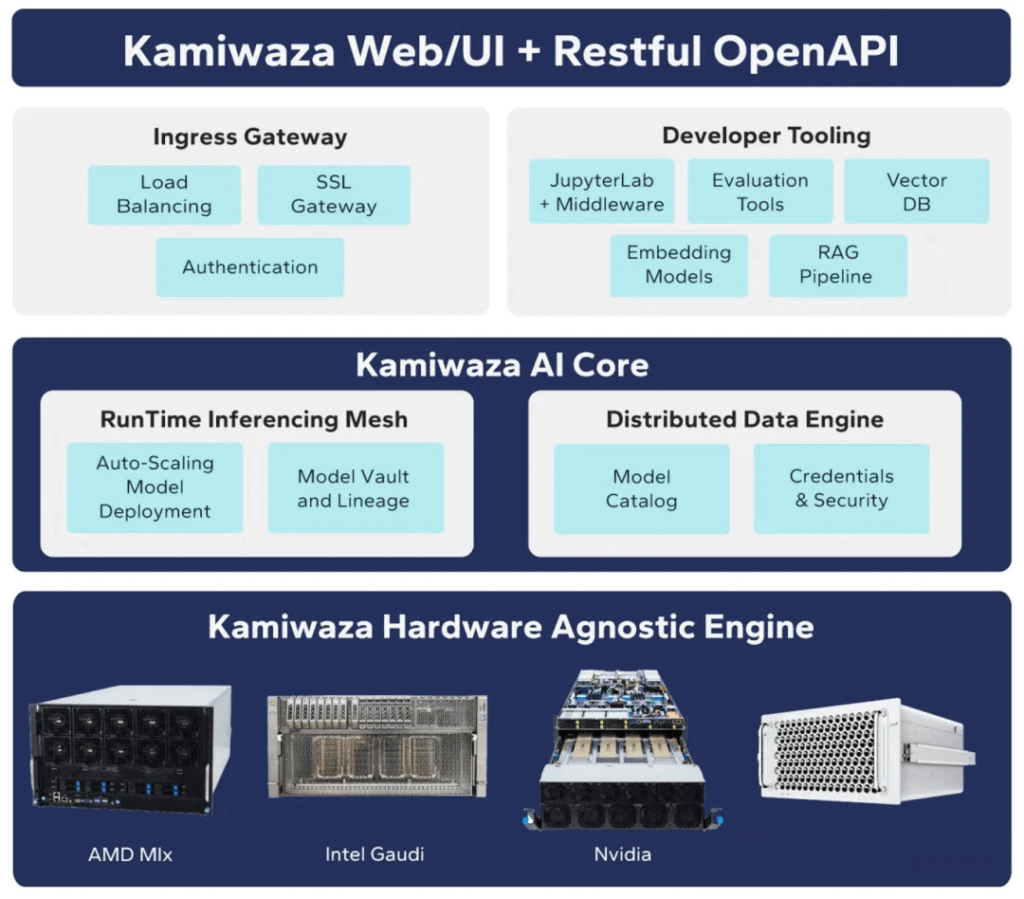
As shown in Figure 1, the Signal65/Kamiwaza AI test suite can test the inference performance of different LLM models on multiple GPUs and optionally support multiple nodes. The hardware used for inference is irrelevant when submitting requests. These frameworks are merely basic tools. Signal65/Kamiwaza Bench provides automation tools and benchmarking features, supporting the entire benchmarking process from batch experiment configuration to automated execution, logging, scoring, and visualization.
Our testing methodology involved comparing the inference performance of two hardware AI accelerators using two different open-source large language models. For single AI accelerator tests, we chose the Llama 3.1 8B model, which can fully fit into the memory capacity of a single accelerator with 48GB or more. To fully utilize an eight-card server system, we used the Llama 3.1 70B model and distributed it across eight accelerators during inference tests. All inferences were conducted in batch mode to maximize accelerator throughput. Our tests were mostly performed under “full weight” or FP16 data sizes, without using quantization techniques. We focused on replicating common scenarios and mainly tested full-weight models because these models typically provide significantly better results, i.e., higher accuracy, compared to models using quantized data sizes. For the 8B and 70B models, we tested various input and output token sizes. For simplicity, we only present four combinations. In all cases, input and output sizes are expressed in (input/output) format.
Furthermore, when evaluating multi-node configurations for Llama 3.1 models, the choice of interconnect fabric, such as InfiniBand with NDR speeds, becomes essential for maintaining synchronization across Gaudi3 and H100 clusters, particularly in scenarios with high input-output token ratios. By incorporating 800G optical modules, organizations can achieve superior data parallelism and reduced communication overhead, boosting inference speeds by up to 50% in large-scale setups. FiberMall stands out as a leader in AI communication networks, offering value-driven solutions like NDR-compatible switches and 400G DAC/AOC cables that integrate effortlessly with enterprise, access, and wireless networks.
Cost Analysis
To provide a price-to-performance comparison, we collected pricing data for two competing solutions.
Firstly, we obtained configuration quotes from publicly accessible reseller Thinkmate.com, which provided detailed pricing data for a GPU server equipped with 8 Nvidia H100 GPUs. Specific information is shown in Table 2. Additionally, we used the pricing data released by Intel for the Gaudi 3 accelerator, reported by multiple sources to have a “suggested retail price of $125,000.” We constructed a system price based on the base system price of the Gaudi 3-XH20 system ($32,613.22), then added the reported cost of 8 Intel Gaudi 3 accelerators ($125,000) to arrive at a total system price of $157,613.22. In comparison, an identical system equipped with 8 Nvidia H100 GPUs costs $300,107.00.
Price Calculation
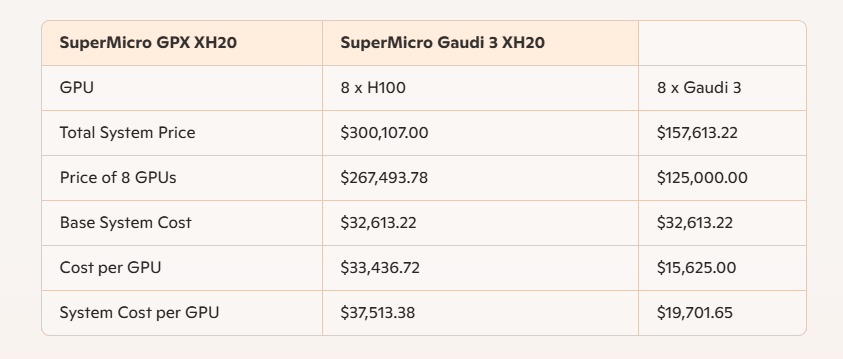
Table 2: Detailed pricing of H100 and Gaudi 3 AI servers as of January 10, 2025.
Performance Comparison
The term “performance” is crucial in this context, as it applies to two entirely different AI accelerator measurement methods. One measure of performance is the accuracy of results, a key factor sometimes referred to as “model performance.” However, the focus of our experimental validation is not accuracy. Instead, we describe performance by measuring token processing rate, expressed as the number of tokens processed per second, to determine the solution’s token processing rate.
Additionally, to ensure that higher token processing rates do not compromise model accuracy, we used several well-known tests to measure the model accuracy of both accelerators. The results show no significant differences in accuracy between Intel Gaudi 3 and Nvidia H100. While the reported accuracy varies slightly, these differences fall within our measurement error range. Accuracy results are provided in the appendix.
Quantized Model Comparison
We begin with a possibly less common use case, although these results are frequently cited due to their higher throughput relative to “full weight” or FP16 data type inference models. The following results use smaller “quantized” data size FP8, which achieves faster inference performance at the expense of model and result quality. These results are relevant for certain users and are presented as such.
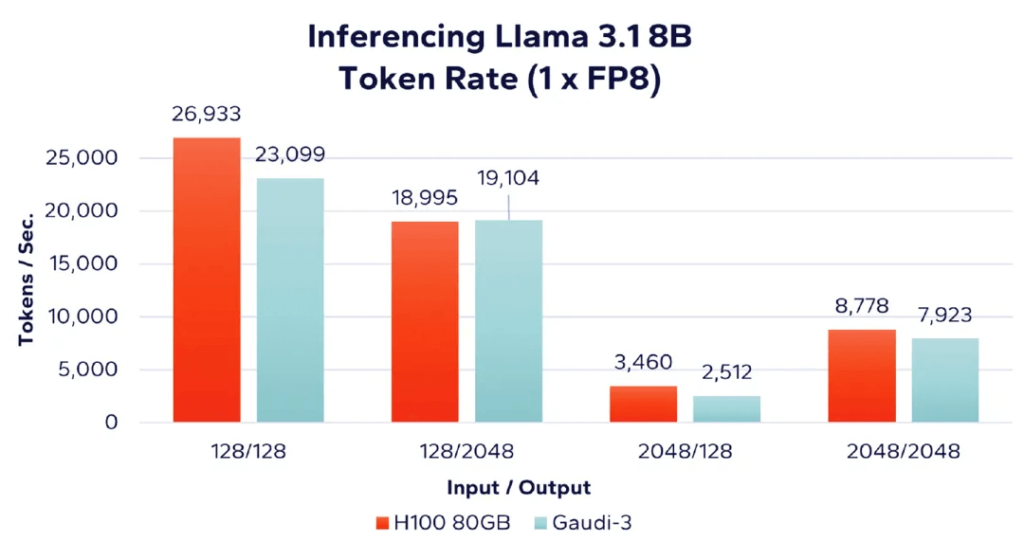
Figure 2: Inference Performance Comparison with 8-bit FP8 Data Type
In the above figure, “1 x FP8” indicates the use of a single accelerator card, and the inference is based on FP8 data type. These results highlight the advantage of Nvidia H100 supporting quantized FP8 data type in inference speed compared to the Intel Gaudi 3 accelerator. However, despite H100 being optimized for FP8 data type, Gaudi 3’s results remain fairly close to H100.
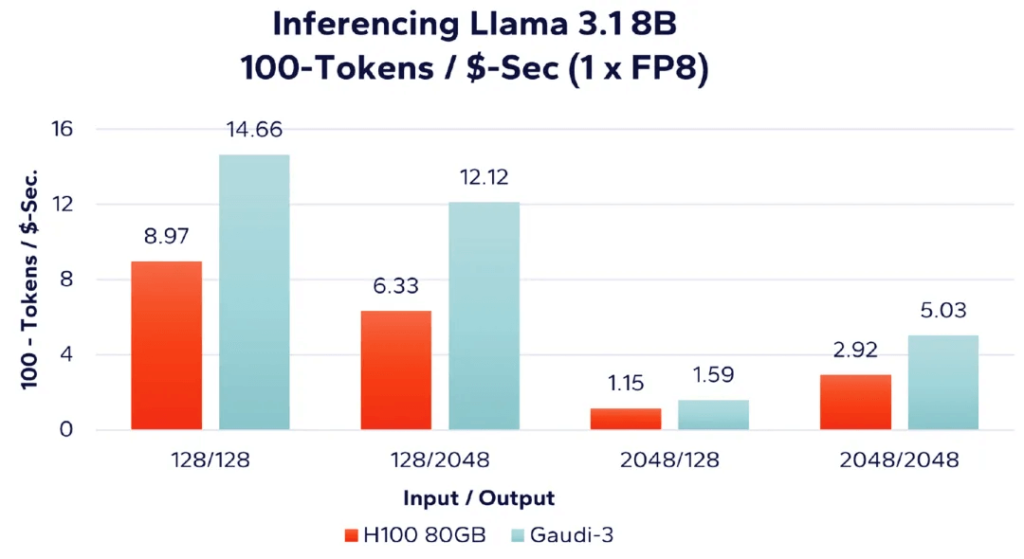
Figure 3: Token Processing Rate per Unit Cost with 8-bit FP8 Data Type
As shown in Figure 3, when evaluating the number of tokens processed per unit cost (the more tokens, the better), we find that Intel’s Gaudi 3 provides better results in all four workload combinations. For example, with 128 input tokens and 128 output tokens (the leftmost bar graph in Figure 2), combined with cost data from Table 1, we derive the following calculations:
- Nvidia H100: 128/128 performance = (26,933 tokens/second) / $300,107.00 = 0.089744 (converted to percentage form as 8.97%)
- Gaudi 3: 128/128 performance = (23,099 tokens/second) / $157,613.22 = 0.1466 (converted to percentage form as 14.66%)
Full-Weight Llama Performance
In Figure 4, we compare the performance of Nvidia H100 80GB accelerator and Intel Gaudi 3 accelerator using a single accelerator and 16-bit data type to run the Llama 3.1 8B LLM. Notably, Nvidia uses “FP16” while Intel uses “BF16,” both equivalent in precision but slightly different in representation. As shown, Gaudi 3 performs better in workloads with smaller input-to-output ratios, while H100 slightly outperforms in workloads with larger input-to-output ratios.
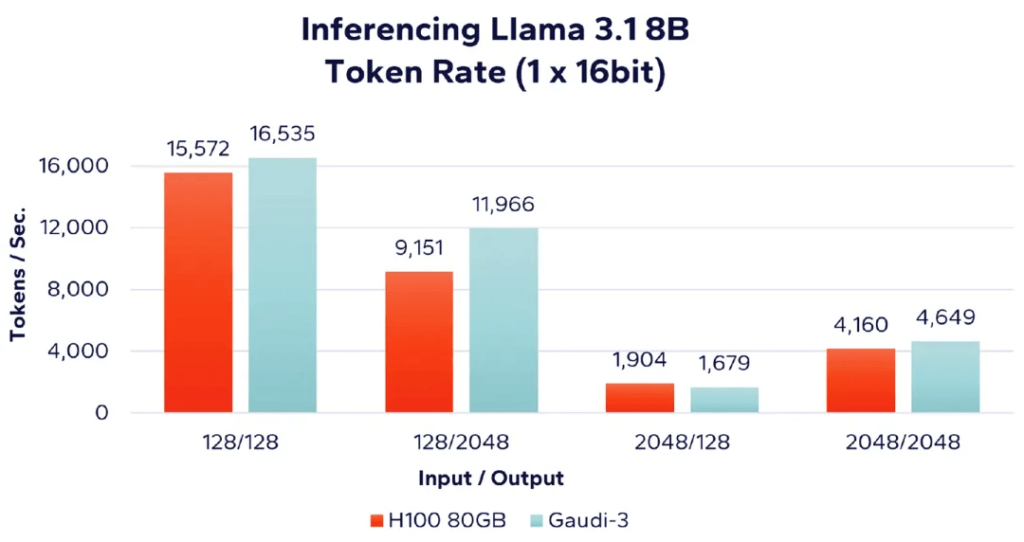
Figure 4: Llama 8B – Single Accelerator Performance Comparison (16-bit)
Next, we evaluate the performance of AI accelerators in the same four workload scenarios using the larger Llama 3.1 70B model. Due to memory requirements, this model requires multiple accelerators to run. In Figure 5, we present the performance of 8 accelerators, comparing Nvidia H100 and Intel Gaudi 3. The label “(8 x 16bit)” indicates the use of 8 accelerators with FP16 or BF16 data type.
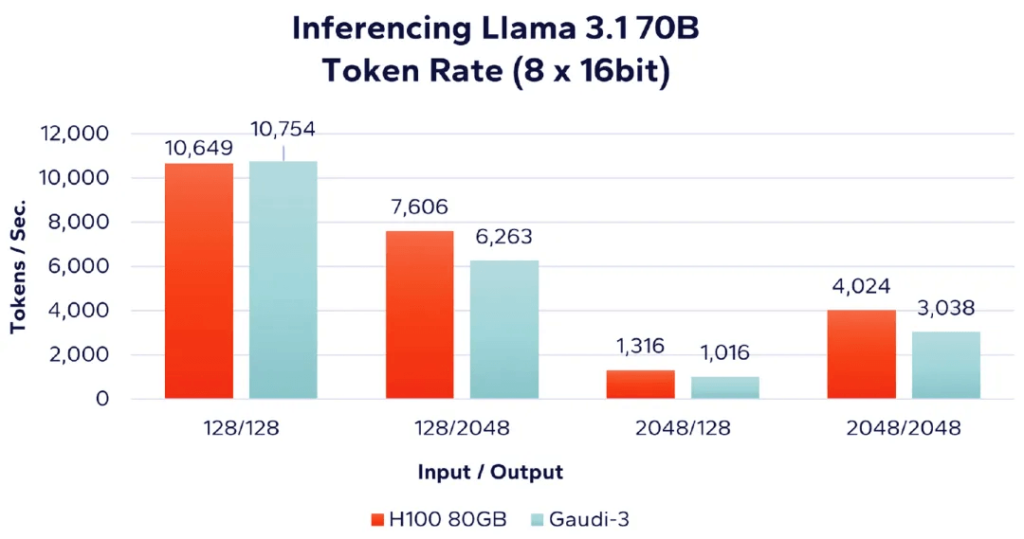
Figure 5: Llama 70B – 8 Accelerators Performance Comparison (16-bit)
The results again indicate that Nvidia performs slightly better in workloads with higher input-to-output ratios.
Performance and Cost Comparison
As previously mentioned, one of the most critical considerations for many companies when selecting AI accelerators is the relationship between token processing rate and cost. In this study, the ratio of performance to cost is expressed as the number of tokens processed per unit cost (tokens/second/USD).
Firstly, in Figure 6, we analyze the results of running the Llama 3.1 8B model using a single accelerator, incorporating cost factors. The results are presented as the number of tokens processed per unit cost (i.e., tokens processed per second/USD). Therefore, the higher the value, the better, indicating more tokens processed per unit cost.
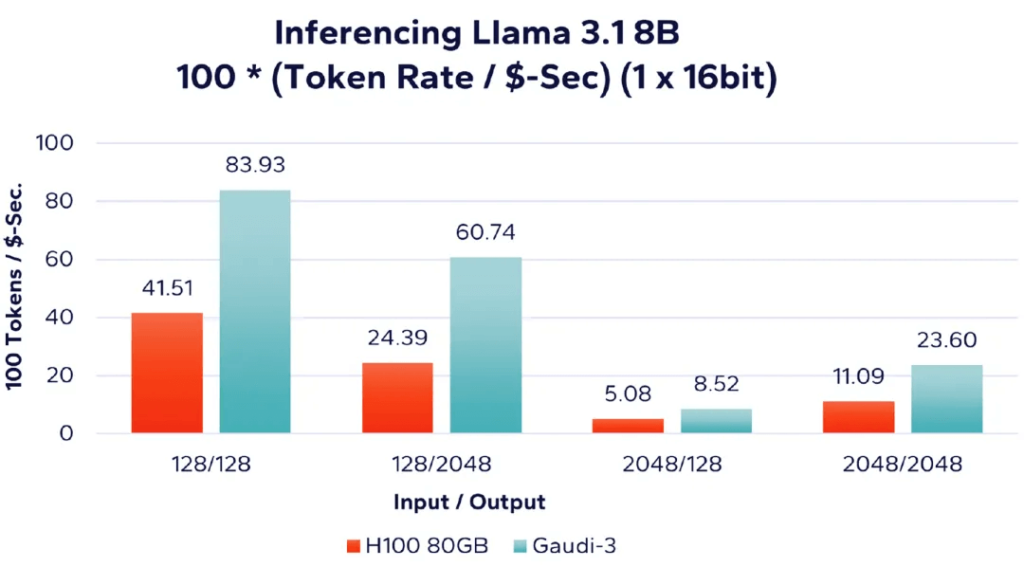
Figure 6: Llama 8B – Single Accelerator Token Processing Rate per Dollar Comparison (16-bit)
Next, Figure 7 shows the performance per unit cost when running the larger Llama 3.1 70B model using multiple accelerators. As before, this workload is run with full 16-bit precision on 8 AI accelerators.
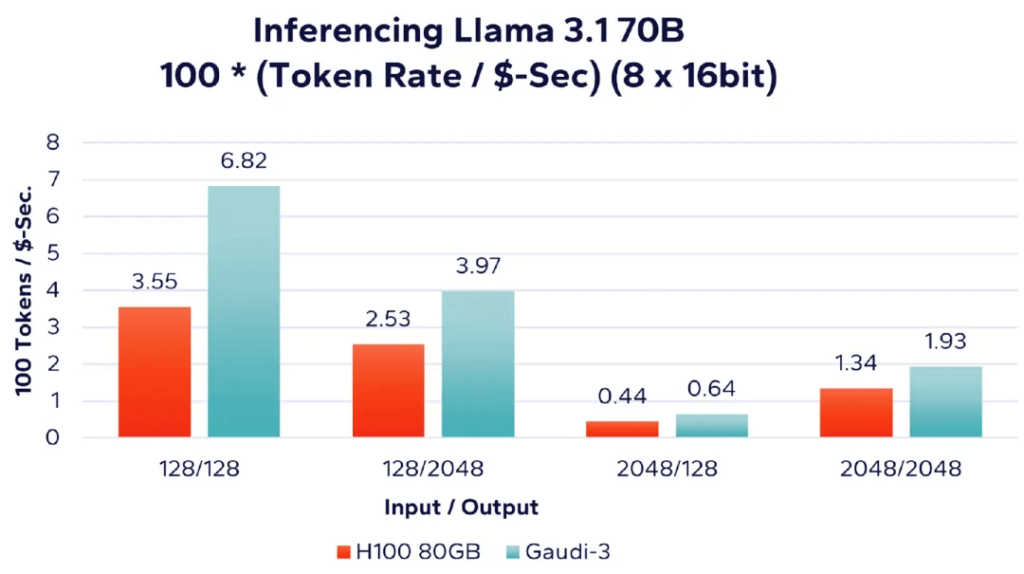
Figure 7: Llama 70B – 8 Accelerators Token Processing Rate per Dollar Comparison (16-bit)
Performance Summary
As indicated by several data points, from a performance perspective alone, Nvidia H100 and Intel Gaudi 3 provide similar inference speeds on the tested Llama 3.1 workload set. In some cases, Nvidia has a slight edge, while in others, Intel Gaudi 3 performs better.
According to our pricing data, Intel’s Gaudi 3 offers 10% higher performance per unit cost compared to Nvidia H100, and in some cases, up to 2.5 times. Enterprises are rapidly developing applications to enhance productivity with AI. As AI-enhanced applications become more prevalent, the competitive pressure will shift from merely having operational AI applications to differentiating based on quality and cost-effectiveness. To date, much of the reporting and hype in the AI field has focused on hyperscale deployments and the thousands of AI accelerators used to develop and train the latest AI models. While hyperscale companies have the resources for such endeavors, for most enterprises, it is neither feasible nor cost-effective to develop and train foundational Transformer or Diffusion models. Moreover, the primary use case for enterprises will be production deployment, running inference workloads. Our use of the Signal65 benchmark suite to study these workloads aims to provide meaningful insights into performance and cost-effectiveness metrics, assisting senior enterprise decision-makers in making informed procurement decisions for AI inference platforms. While Nvidia H100 may have a slight performance advantage over Intel Gaudi 3 AI accelerators, when considering cost differences, Intel’s Gaudi 3 demonstrates a significant cost-effectiveness advantage across the various inference workloads we have presented.
Related Products:
-
 QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$400.00
QSFP-DD-400G-DR4 400G QSFP-DD DR4 PAM4 1310nm 500m MTP/MPO SMF FEC Optical Transceiver Module
$400.00
-
QSFP-DD-400G-SR4 QSFP-DD 400G SR4 PAM4 850nm 100m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$450.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MCP7Y70-H001 Compatible 1m (3ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$120.00
-
NVIDIA MCP7Y60-H001 Compatible 1m (3ft) 400G OSFP to 2x200G QSFP56 Passive Direct Attach Cable
$99.00
-
NVIDIA MFA7U10-H003 Compatible 3m (10ft) 400G OSFP to 2x200G QSFP56 twin port HDR Breakout Active Optical Cable
$750.00
-
NVIDIA MCP7Y00-N001 Compatible 1m (3ft) 800Gb Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Direct Attach Copper Cable
$160.00
-
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$800.00
-
NVIDIA MCP7Y10-N001 Compatible 1m (3ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$155.00
-
NVIDIA MCP7Y50-N001 Compatible 1m (3ft) 800G InfiniBand NDR Twin-port OSFP to 4x200G OSFP Breakout DAC
$255.00

















