
In the era of trillion-parameter AI models, building high-performance AI clusters has become a core competitive advantage for cloud providers and AI enterprises. This article deeply analyzes the unique network requirements of AI workloads, compares architectural differences between AI clusters and traditional data centers, and introduces two mainstream network design paradigms proposed by Arista — Endpoint-Scheduled (NSF) and Switch-Scheduled (DSF) — while providing practical guidance on topology selection and 800G interconnection technology for different scales.
Network Requirements and Traffic Characteristics of AI Clusters
Core Requirements: Extreme Scale, Efficiency, and Flexibility
As AI models rapidly scale to trillions of parameters, training and inference clusters place unprecedented demands on the underlying network:
- Ultra-Large-Scale Expansion: Must support collaborative computing across hundreds of thousands to millions of XPUs (GPUs/NPUs), covering everything from single-rack to multi-data-center scenarios.
- High Efficiency and Ultra-Low Latency: Frequent collective communication operations (e.g., AllReduce, AllGather) between XPUs require microsecond-level latency and ≥90% bandwidth utilization.
- Heterogeneous Adaptation: Must seamlessly support XPUs from different vendors, varying rack power budgets, and mixed workloads (training + inference), avoiding performance degradation due to the “wooden barrel effect” (overall performance limited by the slowest node).
Four Unique Characteristics of AI Traffic
Compared with traditional data center traffic, AI traffic exhibits distinctly different patterns that directly shape network design decisions:
- High Synchronization: Training jobs exchange gradients and parameters in fixed cycles, resulting in “long-burst, highly synchronized” traffic that easily triggers Incast congestion.
- Heavy RDMA Dependence: Requires a Lossless Network**: RDMA over Converged Ethernet (RoCEv2) is the de facto standard; any packet loss triggers retransmission and dramatic latency spikes.
- Stable Flow Characteristics: Individual flows have long lifetimes (from job start to completion), extremely high rates, and low entropy (relatively fixed paths), rendering traditional ECMP load-balancing inefficient.
- Reliability Shifted to the Network: AI applications offload reliability responsibility entirely to the network — even a single packet loss can corrupt an entire training iteration.
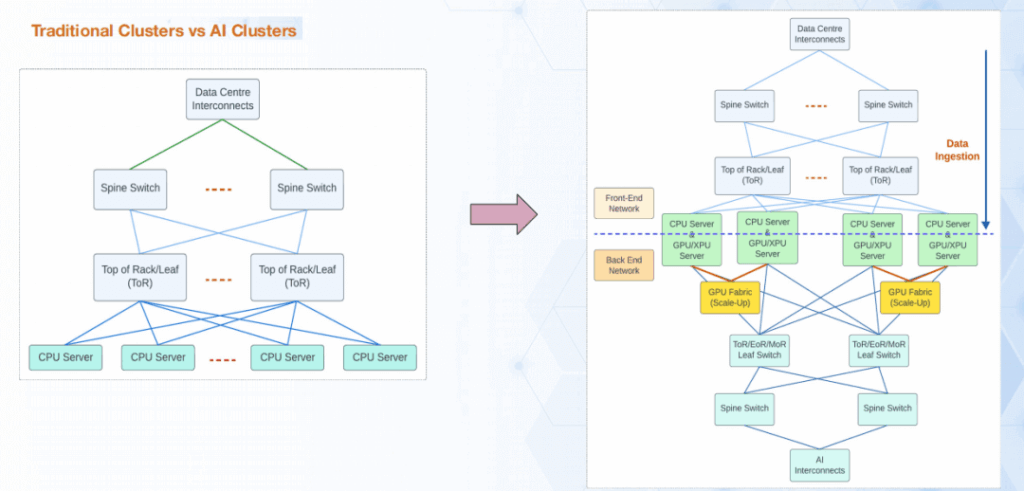
Architectural Differences Between AI Clusters and Traditional Data Center Clusters
Traditional clusters are “CPU-server-centric,” with the network primarily serving horizontal traffic among data ingestion, storage, and compute. In contrast, modern AI clusters are “XPU-centric” and clearly separate:
- Frontend Network – CPU-to-CPU and CPU-to-storage traffic (similar to traditional DC).
- Backend Network (Rail) – High-bandwidth, low-latency XPU-to-XPU interconnect, which becomes the performance bottleneck and primary design focus.
This dual-network architecture significantly increases overall complexity.
Two Core Network Design Paradigms for AI Clusters
Arista classifies current AI cluster backend networks into two mainstream paradigms based on where scheduling responsibility resides:
Endpoint-Scheduled Architecture (NSF – Network Scheduled Fabric)
Core Concept
All scheduling intelligence resides at the endpoints (NIC/DPU/IPU). The network fabric only performs basic packet forwarding — essentially an optimized extension of traditional Ethernet.
Key Technical Characteristics
- Topology: Classic flattened Spine-Leaf or Super-Spine Clos, switches only need high radix and 800G ports.
- Endpoint Requirements: NICs must support Dynamic Load Balancing (DLB), Adaptive Routing, packet spraying, and end-to-end congestion control (ECN/WRED).
- Advantages: Simple architecture, flexible cabling, fully compatible with existing Ethernet ecosystem, ideal for small-to-medium clusters (≤10K XPUs).
- Limitations: Strong vendor lock-in at the NIC layer; scheduling complexity explodes at very large scale, prone to load imbalance and hot spots.
Switch-Scheduled Architecture (DSF – Direct Switch Fabric)
Core Concept
Scheduling responsibility is completely offloaded to the network switches. Endpoints use commodity NICs, while the fabric achieves lossless, high-performance delivery through cell-based switching and credit-based flow control.
Key Technical Characteristics
- Topology: Leaf switches handle cell segmentation, VOQ (Virtual Output Queuing), scheduling, and credit management; Spine/Super-Spine switches are simple low-power forwarders.
- Lossless Mechanism: Credit Request/Grant protocol + PFC + ECN guarantees zero buffer overflow end-to-end.
- Scaling Capability: A single system supports 4.6K × 800G or 9.2K × 400G XPUs; two-tier extension reaches 32K+ GPUs.
- Advantages: NIC vendor agnostic, extremely stable performance at ultra-large scale, precise congestion control.
- Limitations: Higher switch hardware complexity and cost; cabling must align with cell-switching requirements.
Topology and 800G Interconnect Technology Selection
Multi-Plane Topology — The Foundation for Million-Scale XPUs
To achieve linear scaling to hundreds of thousands or millions of XPUs, Arista strongly recommends the Multi-Plane architecture:
- Each plane is an independent Spine-Leaf fabric (typically 4K–10K XPUs).
- Multiple planes operate in parallel and are interconnected via an aggregation layer.
- 10 planes can easily exceed 100K XPUs while maintaining fault isolation and linear bandwidth scaling.
800G Interconnect Technology Selection by Scenario
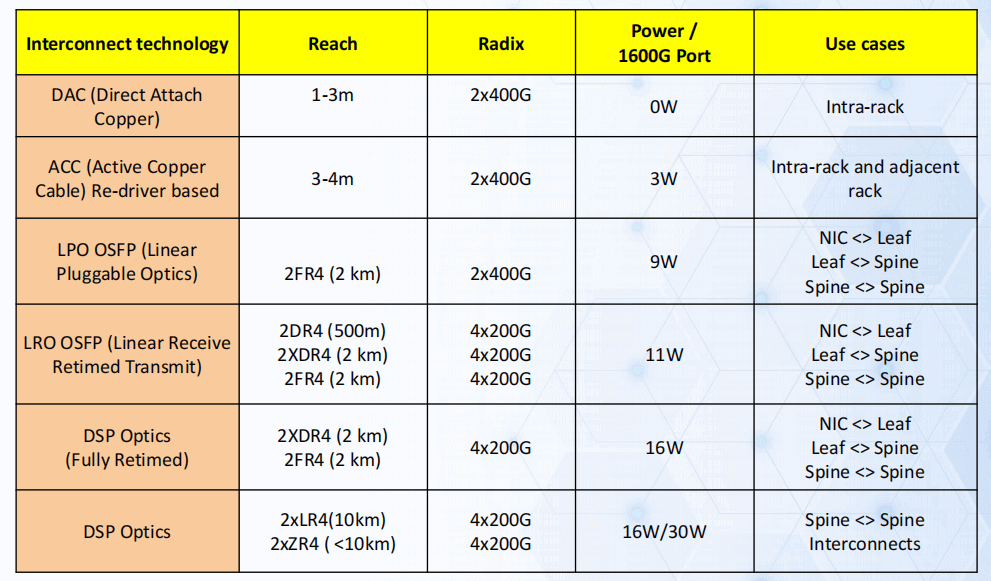
| Scenario | Recommended Technology | Distance | Power Consumption | Cost | Notes |
| Intra-Rack (<2 m) | DAC / ACC | ≤2 m | Extremely low | Lowest | Direct Attach Copper / Active Copper Cable |
| Intra-Row / Short-Reach | LPO / LRO | ≤50 m | Very low | Low | Linear-drive Pluggable Optics — significant power saving vs DSP |
| Medium-Reach (≤500 m) | DSP Coherent | ≤500 m | Moderate | Medium | Traditional DSP optics, mature ecosystem |
| Long-Reach (2–100 km) | DSP + DWDM | ≤100 km+ | Higher | Higher | Required for multi-building or campus-level clusters |
Conclusion and Future Trends
Key Takeaways for Architecture Selection
- ≤10K XPUs → Prefer Endpoint-Scheduled (NSF) for cost and deployment flexibility.
- ≥32K XPUs → Must adopt Switch-Scheduled (DSF) to guarantee stable performance and eliminate endpoint bottlenecks.
- Million-scale → Multi-Plane + DSF is currently the only proven production-grade solution.
Future Trends
- Deeper optimization of collective communication primitives (AllReduce, AllGather, etc.) at the network layer.
- Standardized benchmarking for MPI/NCCL/RCCL over real AI networks.
- Integration of emerging standards such as Ultra Ethernet Consortium (UEC) and UALink to drive the industry from “custom silos” toward open, standardized, ultra-low-latency interconnects.
Building the next-generation AI supercomputer is no longer just about buying more GPUs — the network has become the decisive battleground for performance, scalability, and total cost of ownership.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4A00 (980-9IAH1-00XM00) Compatible 1.6T OSFP DR8D PAM4 1311nm 500m IHS/Finned Top Dual MPO-12 SMF Optical Transceiver Module
$2600.00
-
NVIDIA Compatible 1.6T 2xFR4/FR8 OSFP224 PAM4 1310nm 2km IHS/Finned Top Dual Duplex LC SMF Optical Transceiver Module
$3100.00
-
NVIDIA MMS4A00 (980-9IAH0-00XM00) Compatible 1.6T 2xDR4/DR8 OSFP224 PAM4 1311nm 500m RHS/Flat Top Dual MPO-12/APC InfiniBand XDR SMF Optical Transceiver Module
$3600.00











