
Improving AI Performance and Efficiency
AI workload demands are growing at an unprecedented rate, and the adoption of generative AI is skyrocketing. Every year, new AI factories are springing up. These facilities, dedicated to the development and operation of artificial intelligence technologies, are increasingly expanding into the domains of Cloud Service Providers (CSPs) and enterprise data centers.

An AI factory capable of training trillion-parameter foundation models requires three types of specialized and highly optimized networks:
- North-South Network: A dedicated network for user access and storage access.
- Scale-Up Network: Connects multiple GPUs using NVIDIA NVLink as a memory-coherent interconnect to form a unified, powerful computing domain.
- East-West Scale-Out Network: Connects thousands of GPUs, enabling high-performance AI workloads to achieve scale-out expansion.
When deploying in CSP or enterprise data centers, the design of an AI factory must ensure seamless integration into existing Ethernet service networks and management frameworks to support a broader user base and operational needs:
- SaaS Migration to AI & AI-as-a-Service: SaaS products are increasingly integrating AI capabilities and offering AI-as-a-Service, which requires multi-tenant security and multi-task performance isolation.
- Cloud-Scale Software-Defined Networking (SDN): This configuration model utilizes Ethernet-based protocols and container orchestration technologies (such as Kubernetes). SDN supports scalable resource provisioning from small to large clusters and allows compute and network resources to be reconfigured into multiple smaller clusters.
- Integration and Compatibility: CSP AI services should be deeply integrated with other cloud services, utilizing Ethernet technology to manage complete data pipelines in the cloud.
- Security and Compliance: CSPs implement robust security measures, including packet brokers and Ethernet-based intrusion detection/prevention appliances, to protect customer data and comply with regional regulations.
- Open Source Support: Compatible with open network operating systems, such as SONiC.
Existing Ethernet optimized for shared computing infrastructure is not suitable for AI factories.
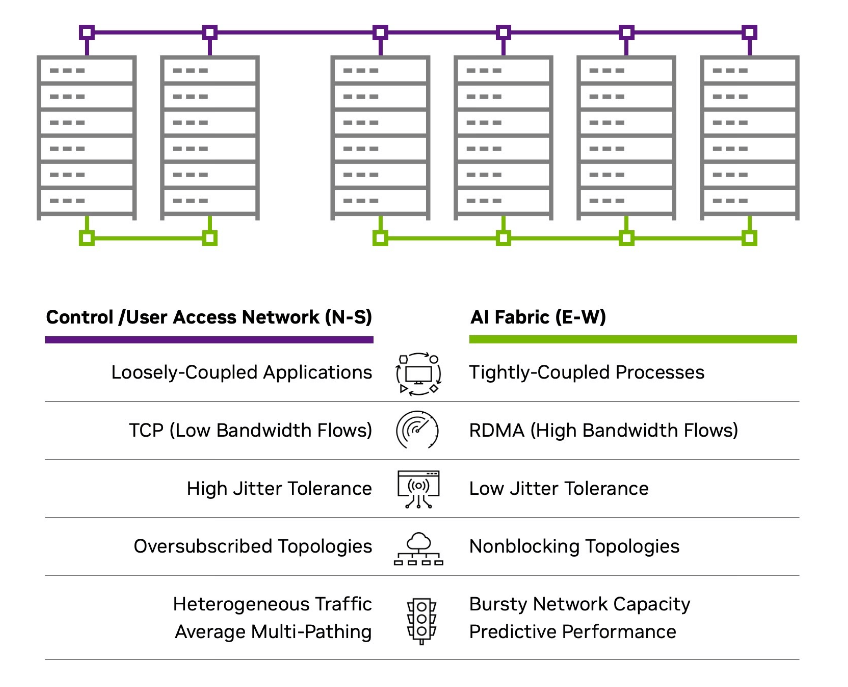
- Control/User Access Network (N-S): Loosely-Coupled Applications, TCP (Low Bandwidth Flows), High Jitter Tolerance, Oversubscribed Topologies, Heterogeneous Traffic / Average Multi-Pathing.
- AI Fabric (E-W): Tightly-Coupled Processes, RDMA (High Bandwidth Flows), Low Jitter Tolerance, Nonblocking Topologies, Bursty Network Capacity / Predictive Performance.
When an AI factory adopts general-purpose off-the-shelf (OTS) Ethernet as the AI compute network, the MLPerf performance level it can achieve is only a fraction of what an optimized network can deliver. In a multi-tenant environment where multiple AI jobs run simultaneously, general-purpose Ethernet struggles to provide effective performance isolation, risking interference between jobs from different tenants. For users choosing Ethernet to deploy AI factories, NVIDIA developed the Spectrum-X Ethernet network platform, which enhances the predictability and energy efficiency of Ethernet-based AI factories while improving performance.
Overview of NVIDIA Spectrum-X Ethernet Network Platform
The NVIDIA® Spectrum™-X Ethernet network platform is the first Ethernet platform designed specifically to improve the performance and efficiency of Ethernet-based AI factories. This groundbreaking technology is based on open standards and can provide network performance significantly superior to general-purpose off-the-shelf (OTS) Ethernet solutions for large-scale AI workloads (such as Large Language Models and inference tasks). The platform also improves energy efficiency and ensures stable, predictable performance in multi-tenant environments. Spectrum-X Ethernet achieves network innovation by tightly coupling the Spectrum-X Ethernet switch with the NVIDIA SuperNIC (e.g., NVIDIA BlueField®-3 SuperNIC or NVIDIA ConnectX-8 SuperNIC). This integration helps provide end-to-end network capabilities built specifically for AI workloads, reducing the runtime of large-scale Transformer-based generative AI models. This enables network engineers, data scientists, and CSPs to obtain results faster and make informed decisions.
In-Depth Analysis of NVIDIA Spectrum-X Ethernet Network Platform
The core of an efficient AI compute network lies in its ability to support and accelerate AI workloads. From the SuperNIC to the switch, cables/transceivers, network architecture, and acceleration software, every link in the network is crucial and must be optimized. To meet these demands, NVIDIA has introduced several innovative technologies aimed at providing maximum effective bandwidth under load and at scale:
- NVIDIA RoCE (RDMA over Converged Ethernet) Adaptive Routing on Spectrum-X switches
- NVIDIA DDP (Direct Data Placement) technology on Spectrum-X Ethernet SuperNICs
- NVIDIA RoCE Congestion Control on Spectrum-X Ethernet switches and SuperNICs
- NVIDIA AI Acceleration Software
- End-to-end AI network visibility
These innovative technologies collectively form a full-stack solution comprehensively tested, optimized, and benchmark-validated by NVIDIA to ensure the highest level of performance. Integrating them into the Spectrum-X Ethernet network platform brings numerous significant advantages.
2.1.1. Core Advantages of Spectrum-X Ethernet
- Enhanced AI Factory Performance: Spectrum-X Ethernet significantly enhances network performance for multi-tenant AI factories.
- Standard Ethernet Connectivity: Spectrum-X provides fully standards-based Ethernet connectivity and is fully interoperable with Ethernet-based hardware and software stacks.
- Improved Energy Efficiency: By boosting performance, Spectrum-X Ethernet helps create a more energy-efficient AI environment.
- Enhanced Multi-Tenant Protection: Performance isolation in multi-tenant environments ensures that every tenant’s workload receives optimal and consistent performance, thereby increasing customer satisfaction and service quality.
- Better AI Network Visibility: Visibility into AI factory data flows helps identify performance bottlenecks, which is key for modern automated network verification solutions.
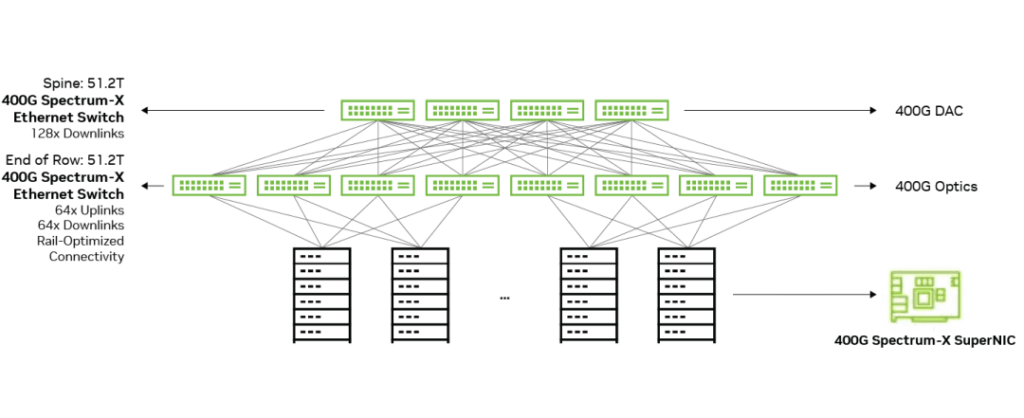
- Higher AI Scalability: Spectrum-X Ethernet scales to 128 400G Ethernet ports (single hop) or 8K ports in a two-tier leaf-spine topology, maintaining high performance levels while supporting AI factory expansion.
- Faster Network Provisioning: Advanced network features comprehensively tuned for AI workloads enable automated end-to-end configuration.
- Comprehensive AI Network Security: Spectrum-X Ethernet provides end-to-end protection for AI data centers.
- Optimized Cross-Geo Networking: Spectrum-XGS Ethernet enables geographically dispersed data centers to operate as a single, unified AI factory.
The Spectrum-X Ethernet network platform is a full-stack solution built on the following key components.
2.1.2. NVIDIA Spectrum-X Ethernet Switch
Built on a 51.2Tbps ASIC, the Spectrum-X Ethernet switch supports up to 64 800GbE ports or 128 400GbE ports in a single 2U switch. As the first switch series designed from the ground up for AI workloads, they set a new industry standard. These switches combine a proprietary high-performance, low-latency architecture with standard Ethernet connectivity, providing unmatched efficiency and reliability to ensure seamless operation and optimal performance in demanding AI scenarios.
Spectrum-X Ethernet switches offer RoCE extensions optimized for AI and feature unique enhancements:
- RoCE Adaptive Routing
- RoCE Performance Isolation
- Highest effective bandwidth on large-scale standard Ethernet
- Low latency, low jitter, and short tail latency

NVIDIA Spectrum-X Ethernet SuperNIC
The NVIDIA® Spectrum-X Ethernet SuperNIC is a third-generation data center infrastructure-on-a-chip that enables enterprises to build software-defined, hardware-accelerated IT infrastructure from the cloud to the core data center and edge. BlueField®-3 SuperNIC provides up to 400Gb/s RoCE network connectivity between GPU servers, optimizing peak efficiency for AI workloads and providing deterministic and isolated performance between different jobs and tenants.

BlueField-3 is designed for AI acceleration, integrating AI-oriented full interconnect engines, NVIDIA GPUDirect®, and NVIDIA® Magnum IO GPUDirect® Storage (GDS) acceleration technologies. Additionally, the BlueField-3 SuperNIC runs natively in Network Interface Card (NIC) mode, utilizing local memory to accelerate operations for large AI factories. At scale, these AI factories require massive numbers of locally addressable Queue Pairs, rather than relying on system memory. Finally, it includes NVIDIA Direct Data Placement (DDP) technology, which further enhances RoCE Adaptive Routing capabilities.
NVIDIA ConnectX-8 SuperNIC provides up to 800Gb/s RoCE network connectivity between GPU servers, optimizing peak efficiency for AI workloads and providing deterministic and isolated performance between different jobs and tenants. ConnectX-8 is built for AI acceleration, integrating AI-oriented full interconnect engines, NVIDIA GPUDirect, and NVIDIA Magnum IO GPUDirect Storage (GDS) acceleration technologies. Finally, it includes the same NVIDIA Direct Data Placement (DDP) technology and programmable congestion control functions as the BlueField-3 SuperNIC.

NVIDIA End-to-End Physical Layer
Spectrum-X Ethernet is the only network platform capable of providing seamless connectivity from the switch to the SuperNIC and then to the GPU. This end-to-end integration ensures superior signal integrity and the lowest Bit Error Rate (BER), significantly reducing power consumption in AI factories. By adopting the same advanced SerDes technology found in NVIDIA GPUs, Spectrum-X Ethernet switches and SuperNICs make no compromises in ensuring optimal energy efficiency and performance.
SerDes Technology (Serializer/Deserializer) is a critical integrated circuit technology used in high-speed communications to convert data between parallel signals and serial signals. Its core function is to enable efficient, long-distance data transmission with a limited number of pins or channels.
2.3.1. NVIDIA Acceleration Software
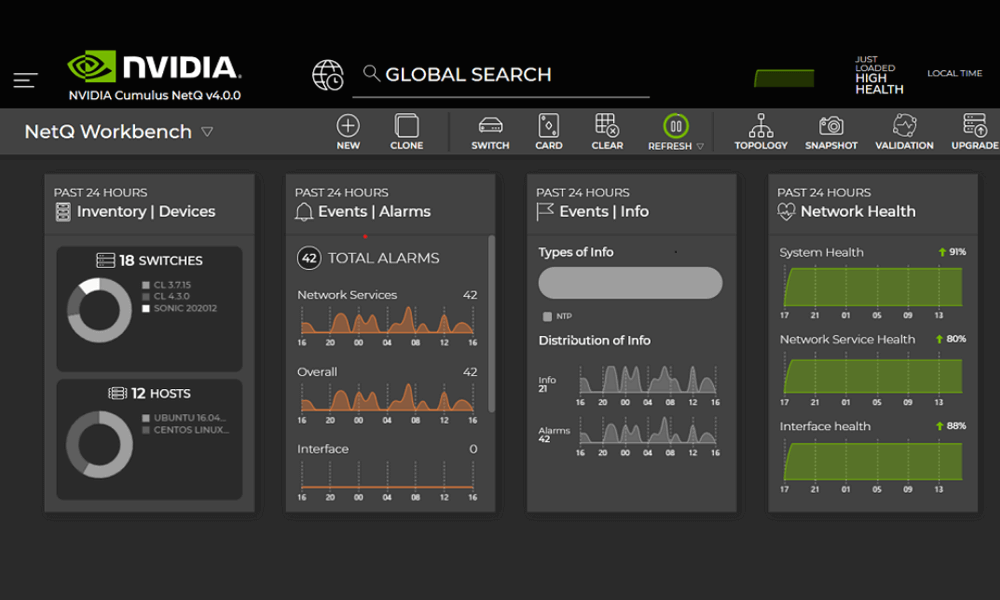
2.3.1.1. NetQ
NVIDIA NetQ™ is a highly scalable network operations toolset designed for real-time AI network visualization, troubleshooting, and verification. Leveraging “NVIDIA What Just Happened” switch telemetry data and NVIDIA® DOCA™ telemetry technology, NetQ provides actionable insights into the health of Spectrum-X Ethernet switches and SuperNICs, integrating the network into the enterprise MLOps ecosystem.
Additionally, NetQ flow telemetry maps flow paths and behaviors across switch ports and RoCE queues for analyzing specific application data flows. NetQ samples and analyzes packets, reporting latency (max, min, and average) and buffer occupancy for every switch along the flow path. The NetQ GUI displays all possible paths, details for each path, and flow behavior. Combining NVIDIA What Just Happened® technology with flow telemetry helps network operators proactively identify the root causes of server and application issues.
2.3.1.2. Spectrum Software Development Kit (SDK)
The NVIDIA Ethernet Switch SDK offers the flexibility to implement any switching and routing function, with sophisticated programmability that does not compromise performance in terms of packet rate, bandwidth, or latency. With this SDK, server and network equipment OEMs, as well as Network Operating System (NOS) vendors, can fully leverage the advanced network features of this Ethernet switch IC family to build flexible, innovative, and cost-optimized switching solutions.
2.3.1.3. NVIDIA DOCA
The NVIDIA® DOCA™ software framework is the key to unlocking the potential of the NVIDIA BlueField® networking platform. With DOCA, developers can build future data center infrastructure by creating software-defined, cloud-native, BlueField-accelerated, and Zero Trust-protected services, meeting the growing performance and security demands of modern data centers.
2.3.2. Comprehensive AI Network Fabric Security
In modern data centers supporting complex AI workloads, AI network fabric security is a critical issue for ensuring business continuity, regulatory compliance, and organizational trust in digital infrastructure. As a vital component of the NVIDIA Spectrum-X Ethernet AI platform, Spectrum-X Ethernet security encompasses protection measures across hardware, firmware, and software layers to effectively secure these environments.
2.3.2.1. Network Platform Component Security
Spectrum-X components—including Spectrum-X Ethernet switches, BlueField-3 SuperNICs, ConnectX-8 SuperNICs, and LinkX cables—are designed with security as a foundation. BlueField-3 and ConnectX-8 devices feature secure boot processes, a hardware root of trust, secure firmware updates, flash encryption, and device authentication to prevent firmware-level attacks and unauthorized changes. They also integrate dedicated hardware protection mechanisms to defend against physical attacks such as fault injection. These devices support software-defined networking and programmable pipelines, enabling granular policy enforcement and accelerating security functions. Key security protocols (such as PSP and IPsec) are offloaded and accelerated to encrypt AI fabric data in transit.
Spectrum-X Ethernet switches implement a comprehensive security framework covering hardware, firmware, and software layers. All layers are authenticated through a built-in root of trust that spans from ASIC firmware and BIOS to the network operating system. Physical protection countermeasures are also applied. At the network security level, Spectrum-X Ethernet supports VXLAN to secure overlay networks and combines it with L3EVPN to achieve advanced network virtualization, providing secure, scalable network segmentation and tenant isolation.
2.3.2.2. AI Network Fabric Isolation
In multi-tenant environments, network isolation is crucial for ensuring complete separation of tenant traffic. It prevents unauthorized access, protects privacy, supports compliance requirements, and prevents cross-tenant performance or security impacts. Spectrum-X Ethernet supports L3EVPN based on the VXLAN BGP EVPN architecture, providing logically isolated Routing Domains (VRFs) for each tenant. Each VRF operates as an independent virtual network with a dedicated Virtual Network Identifier (VNI), isolating routing tables, policies, and traffic between tenants. Furthermore, NVIDIA uses a patented implementation of IEEE 802.1X for tenant provisioning, offering a distributed and resilient system that enables seamless and secure network access without requiring incremental changes for each tenant.
2.3.2.3. Data Encryption in Transit within AI
Fabric Encrypting data in transit within the AI fabric is essential for maintaining confidentiality, integrity, and compliance in both single-tenant and multi-tenant settings. BlueField-3 and ConnectX-8 SuperNICs support offloading security protocols such as IPsec and PSP, which reduces host CPU load and ensures transparent, line-rate encryption of network traffic before it leaves the node. This capability enables comprehensive end-to-end encryption between GPUs within the AI fabric.
Challenges of Deploying AI on Ethernet
The Necessity of RDMA and Lossless Networks
AI requires exceptional GPU performance. To get multiple GPUs working efficiently together, they need Remote Direct Memory Access (RDMA)—a networking technology that allows direct access from the memory of one computer to the memory of another without passing through the CPU of either.
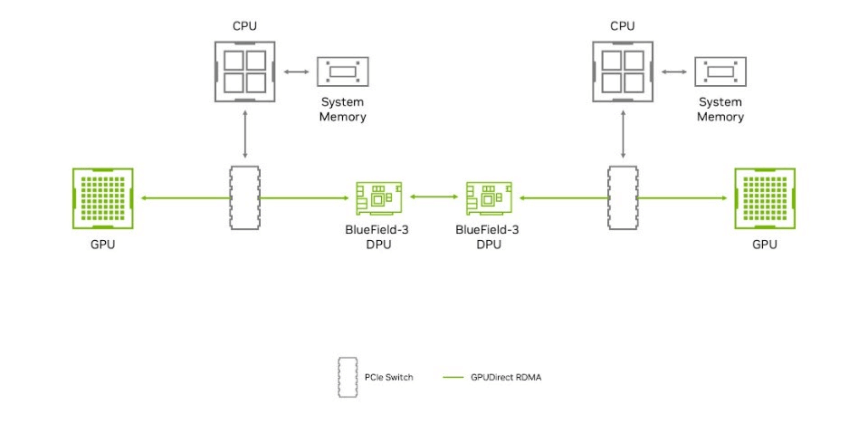
RDMA allows peripheral PCIe devices (such as NVIDIA BlueField) to access GPU memory directly. GPUDirect RDMA, designed specifically for GPU acceleration, enables direct communication between NVIDIA GPUs across remote systems, bypassing the system CPU and eliminating the need for data buffer copies via system memory. When running on RoCE, GPUDirect RDMA achieves optimal performance, but only if deployed on a lossless network, which is critical for its reliable operation.
3.1.1. Need for RoCE Adaptive Routing to Avoid Congestion
A key feature of scalable IP networks is their ability to distribute massive traffic and data flows across multiple layers of switches.
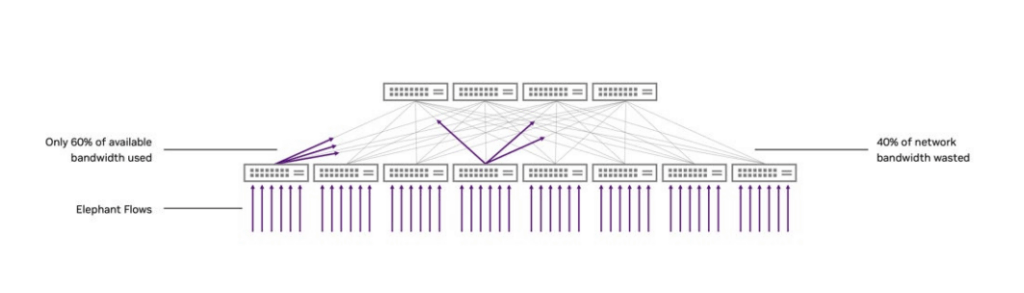
Ideally, data flows are completely uncorrelated, allowing them to be well-distributed and smoothly load-balanced across multiple network links. This approach relies on modern hashing algorithms and multi-pathing algorithms, including Equal-Cost MultiPath (ECMP). Modern data centers built on high-port-density, fixed-form-factor switches extensively use ECMP to build hyperscale networks.
However, in many cases, ECMP flow-hash-based methods are ineffective. This typically involves ubiquitous modern workloads like AI and storage. The problem lies in limited entropy and associated hash collisions, causing excessive “Elephant Flows” (large-scale data flows) to be sent onto the same path. Entropy here refers to the measure of randomness in network packets or network flows, reflecting the amount of information or degree of variability contained in protocol headers.
High Entropy represents high randomness and rich variation in packet header information (e.g., source/destination IP, port) within network traffic. This allows hashing algorithms to evenly scatter a large number of small flows across multiple paths, achieving efficient load balancing and avoiding link congestion. Typical scenarios include traditional cloud services. Low Entropy indicates singular traffic characteristics and high repetition (e.g., a few large-scale data flows). Hashing algorithms tend to map multiple large flows to the same path, leading to link overload, congestion, and performance degradation. This is common in “Elephant Flow” scenarios like AI training and high-performance storage. Entropy directly affects network load balancing effectiveness and is a key indicator for optimizing network performance for intensive workloads like AI.
Traditional cloud services generate thousands of flows randomly connected to customers worldwide, providing high entropy for cloud service networks. However, AI and storage workloads tend to generate very few flows, but each flow is massive in scale. These large AI flows dominate the bandwidth usage of each link, significantly reducing the total number of flows, resulting in very low network entropy. This low-entropy traffic pattern, also known as Elephant Flow Distribution, is a typical characteristic of AI and high-performance storage workloads.
3.1.2. Entropy Matters
In traditional IP routing, to achieve load balancing across all available Equal-Cost MultiPaths (ECMP) and avoid packet reordering, switches use static hashing based on per-flow information (typically 3-tuple or 5-tuple). This requires high entropy to evenly disperse traffic across multiple links without congestion. However, in Elephant Flow scenarios, when entropy is low and flow scale is huge (common in AI networks), multiple flows may be hashed to the same link, causing that link to overload. This overload causes congestion, increased latency, packet loss, retransmission, and ultimately, application performance degradation.
For many applications, performance depends not just on average network bandwidth, but is also affected by the flow completion time distribution. Long tails or outliers in completion time distribution can significantly lower application performance. Below is a common topology in AI networks that is highly likely to suffer performance degradation due to long-tail latency.
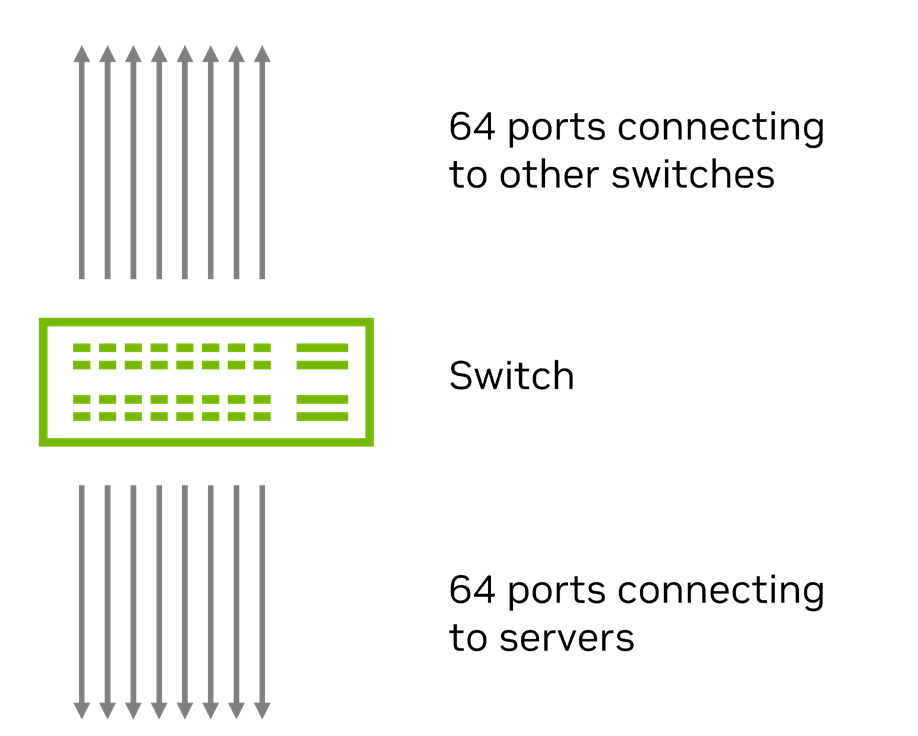
The example in Figure 9 includes a leaf switch with 128 400GbE ports.
- 64 ports are downlinks, connecting to servers at 400GbE.
- 64 ports are uplinks, connecting to spine switches at 400GbE.
- Each downlink port receives traffic from four equal-bandwidth flows: 100G per flow, totaling 256 flows.
- All traffic distribution across uplink ports is handled via ECMP-based flow hashing.
As bandwidth levels rise, the probability of congestion increases, and flow completion times extend accordingly. In the worst case, flow completion time can be 2.5 times longer than the ideal case (see Figure 10).
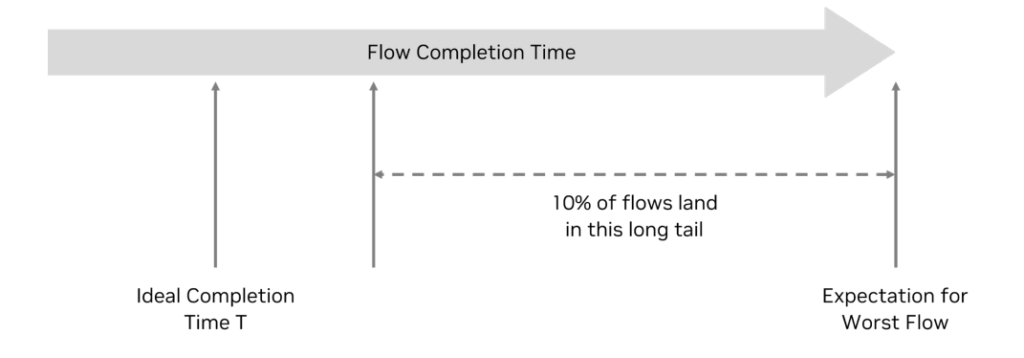
In this scenario, a few ports become congested while others remain unused. The estimated duration of the last completing (worst) flow is 250% of the estimated duration of the first completing (best) flow. That is, there is a long tail in flow completion time exceeding expectations. To avoid congestion with high confidence (98%), bandwidth for all flows must be reduced to below 50%.
Many flows are affected by excessively long completion times because static ECMP hashing lacks bandwidth awareness, causing some switch ports to be highly congested while others are underutilized. As some flows complete and release port bandwidth, lagging flows continue to traverse the same congested ports, triggering more congestion. This is because the forwarding path is statically determined once the packet header is hashed.
3.1.3. NVIDIA RoCE Adaptive Routing Ensures Load Balancing
RoCE Adaptive Routing functionality is available on Spectrum-X Ethernet switches. With adaptive routing, when traffic is forwarded to an ECMP group, the least congested port is selected for transmission. Congestion status is evaluated based on egress queue load, ensuring good balance across the ECMP group regardless of entropy levels. Applications sending multiple requests to multiple servers will receive data with minimal latency variance.
For every packet forwarded to an ECMP group, the switch selects the port with the minimum egress queue load. The queues evaluated are those matching the packet’s traffic class. Since different packets of the same flow may traverse different paths through the network, they may arrive at the destination out of order. At the RoCE transport layer, the Spectrum-X Ethernet SuperNIC handles out-of-order packets and delivers data to the application in order. This makes the “magic” of RoCE Adaptive Routing transparent to the applications benefiting from it.
At the sender side, the SuperNIC can dynamically mark traffic to qualify it for packet reordering, ensuring sequential control between packets is executable when needed. The switch’s adaptive routing classifier classifies only these marked RoCE packets, subjecting them to this unique forwarding mechanism.
3.1.4. Necessity of NVIDIA RoCE Congestion Control
When multiple applications run simultaneously in an AI factory, they may suffer from poor performance and unstable runtimes due to network-level congestion. This congestion can be caused by the application’s own network traffic or by background network traffic from other applications. The primary cause of such congestion is known as Many-to-One congestion, or Incast Congestion, characterized by multiple data senders corresponding to a single data receiver.
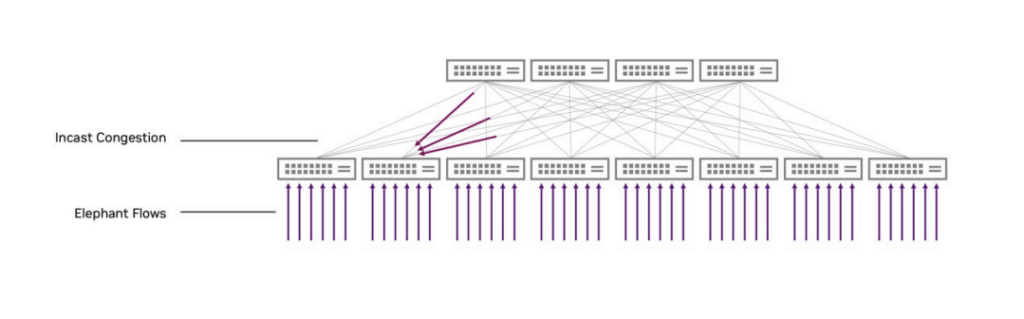
Unfortunately, RoCE Adaptive Routing cannot solve Incast Congestion because no alternative paths exist to bypass the congestion in such scenarios. Spectrum-X Ethernet can resolve Incast Congestion through NVIDIA RoCE Congestion Control.
Key Features of NVIDIA Spectrum-X Ethernet Network Platform
AI workloads are characterized by a small number of elephant flows responsible for massive data transfers between GPUs, where tail latency has a huge impact on overall application performance. Handling such traffic patterns with traditional network routing mechanisms can lead to unstable GPU performance and underutilization for AI workloads. Spectrum-X Ethernet’s RoCE Adaptive Routing is a fine-grained load balancing technology. It dynamically reroutes RDMA data to avoid congestion and provides optimal load balancing, thereby achieving the highest effective data bandwidth.
3.2.1. How NVIDIA RoCE Adaptive Routing Works
RoCE Adaptive Routing is an end-to-end capability implemented jointly by Spectrum-X Ethernet switches and SuperNICs. The Spectrum-X Ethernet switch is responsible for selecting the least congested port for data transmission on a per-packet basis. When different packets of the same data flow travel via different network paths, they may arrive at the destination out of order. The Spectrum-X Ethernet SuperNIC processes any out-of-order data at the RoCE transport layer, transparently delivering ordered data to the application.
The Spectrum-X Ethernet switch evaluates congestion based on egress queue load, ensuring load balancing across all ports. It uses packet spraying technology to select the port with the minimum egress queue load for each network packet. Simultaneously, the switch receives status notifications from adjacent switches, which may influence forwarding decisions. The evaluated queues match the corresponding traffic class. Consequently, Spectrum-X Ethernet enables hyperscale systems to achieve up to 95% effective bandwidth under load and at scale.
3.2.2. NVIDIA RoCE Adaptive Routing Combined with NVIDIA DDP
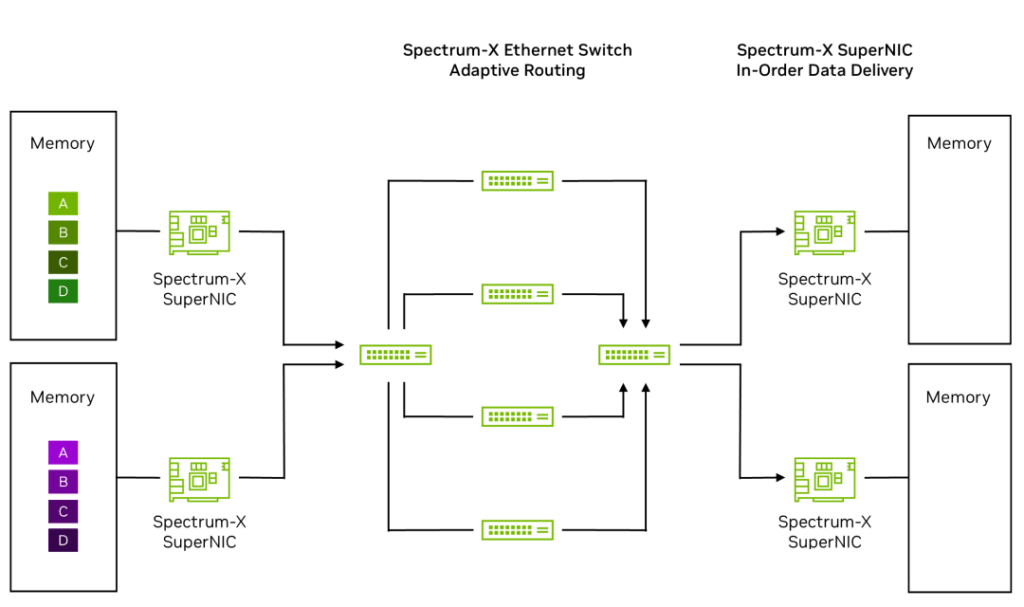
The following packet-level process demonstrates how AI data flows are transmitted between GPUs in a Spectrum-X Ethernet network. It describes how RoCE Adaptive Routing on the Spectrum-X Ethernet switch works in synergy with Direct Data Placement (DDP) technology on the Spectrum-X Ethernet SuperNIC:
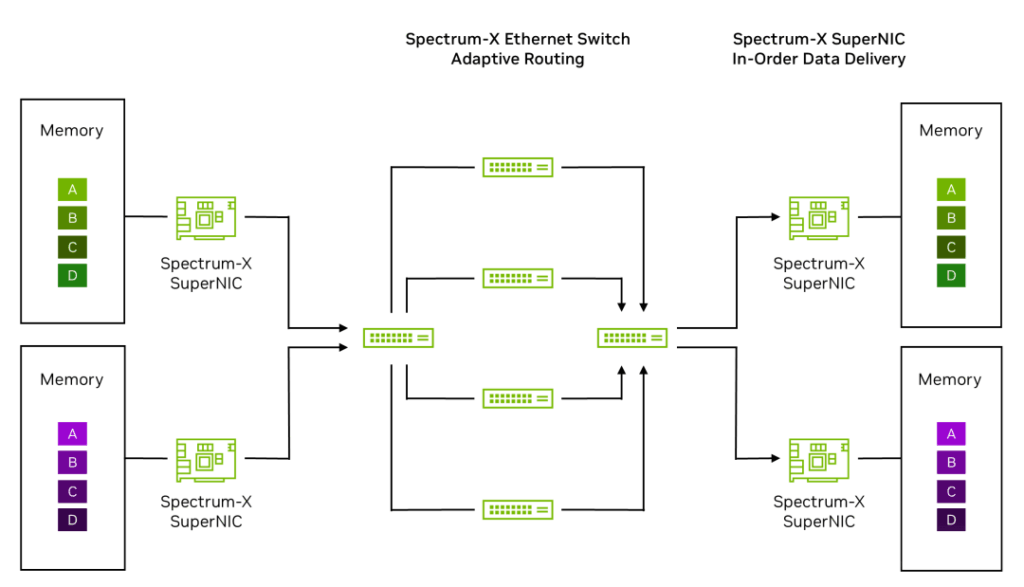
Step 1: Data originates from server or GPU memory on the left side of the diagram, destined for the server on the right.
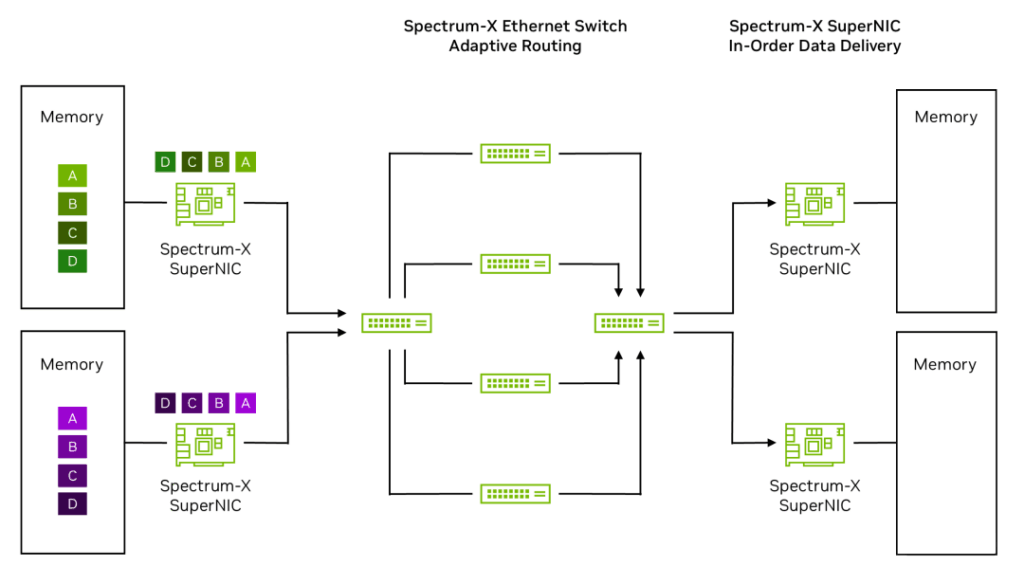
Step 2: The Spectrum-X Ethernet SuperNIC encapsulates data into packets and sends them to the first Spectrum-X Ethernet leaf switch, marking these packets as eligible for RoCE Adaptive Routing.
Step 3: The Spectrum-X Ethernet leaf switch on the left uses RoCE Adaptive Routing to load balance packets from the green and purple data flows across 4 spine switches, sending packets from each flow to multiple spine switches. This boosts effective bandwidth from 60% with general-purpose off-the-shelf (OTS) Ethernet to 95% with Spectrum-X Ethernet.
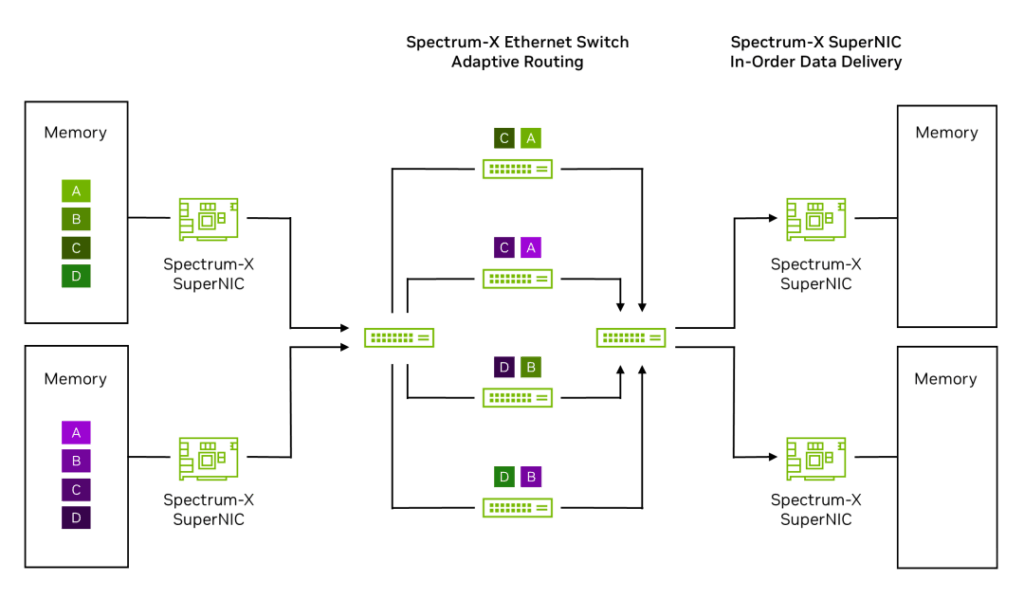
Step 4: Some packets may arrive out of order when reaching the Spectrum-X Ethernet SuperNIC on the right.
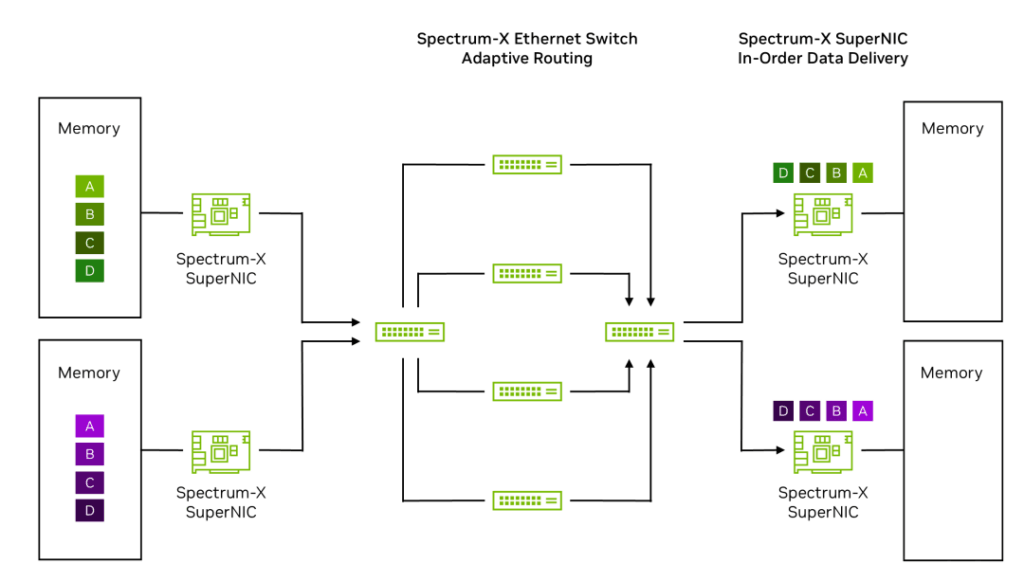
Step 5: The Spectrum-X Ethernet SuperNIC on the right uses NVIDIA Direct Data Placement (DDP) technology to place data into host/GPU memory in the correct order.
3.2.2.1. Effect of RoCE Adaptive Routing
To verify the effect of RoCE Adaptive Routing, we first tested a simple RDMA write test application. In these tests, we divided hosts into pairs, with each pair sending large volumes of RDMA write flows to each other for an extended period.
Figure 12 shows that forwarding based on static hashing caused collisions on uplink ports, leading to increased flow completion times, reduced bandwidth, and decreased fairness between flows. All issues were resolved after switching to Adaptive Routing.
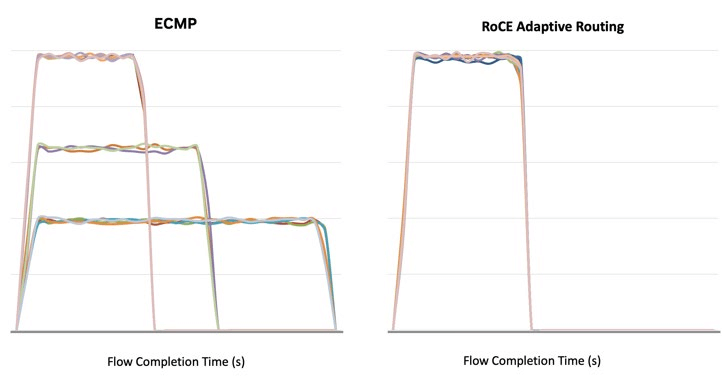
In the ECMP chart section, some flows have the same bandwidth and completion time, while others collide, resulting in longer completion times and lower bandwidth. Specifically, in the ECMP scenario, some flows achieved a best completion time (T) of 13 seconds, while the slowest flow took 31 seconds, approximately 2.5 times longer than the best time. In the RoCE Adaptive Routing chart section, all flows completed at roughly the same time and had similar peak bandwidths.
3.2.2.2. Summary of RoCE Adaptive Routing
In many cases, ECMP-based flow hashing leads to high congestion and unstable flow completion times, thereby degrading application performance. Spectrum-X Ethernet’s RoCE Adaptive Routing solves this problem by increasing the network’s effective throughput and minimizing volatility in flow completion times, thus improving application performance. By combining RoCE Adaptive Routing with NVIDIA Direct Data Placement (DDP) technology on the Spectrum-X Ethernet SuperNIC, this technology remains transparent to applications. This integration ensures that the NVIDIA Spectrum-X Ethernet platform delivers the accelerated Ethernet performance needed to maximize data center operations.
3.2.3. Achieving Performance Isolation with NVIDIA RoCE
Congestion Control Applications running concurrently in an AI factory may experience performance degradation and unpredictable runtimes due to network-level congestion. This can be caused by the application’s own network traffic or background network traffic from other applications. The primary cause of such congestion is Many-to-One congestion, involving multiple data senders and a single data receiver.
Such congestion cannot be solved by RoCE Adaptive Routing but requires flow metering based on each endpoint. Spectrum-X Ethernet RoCE Congestion Control is an end-to-end technology where Spectrum-X Ethernet switches provide network telemetry regarding real-time congestion data. This telemetry is processed by the Spectrum-X Ethernet SuperNIC, which manages and controls the data injection rate of senders to maximize network sharing efficiency. Without this congestion control, many-to-one scenarios would lead to network backpressure, congestion spreading, and even packet loss, significantly reducing network and application performance.
When managing congestion, the Spectrum-X Ethernet SuperNIC executes congestion control algorithms, processing millions of congestion control events per second with microsecond-level response latency and applying fine-grained rate decisions. The in-band telemetry of Spectrum-X Ethernet switches contains both queue information for accurately estimating congestion and port utilization indicators for fast recovery. NVIDIA’s congestion control method allows telemetry data to bypass queuing delays in congested flows while still providing accurate and concurrent telemetry, thereby significantly improving congestion discovery and response speed.
The following example demonstrates how a network encounters Many-to-One congestion and how Spectrum-X Ethernet utilizes flow metering and in-band telemetry to implement RoCE Congestion Control.
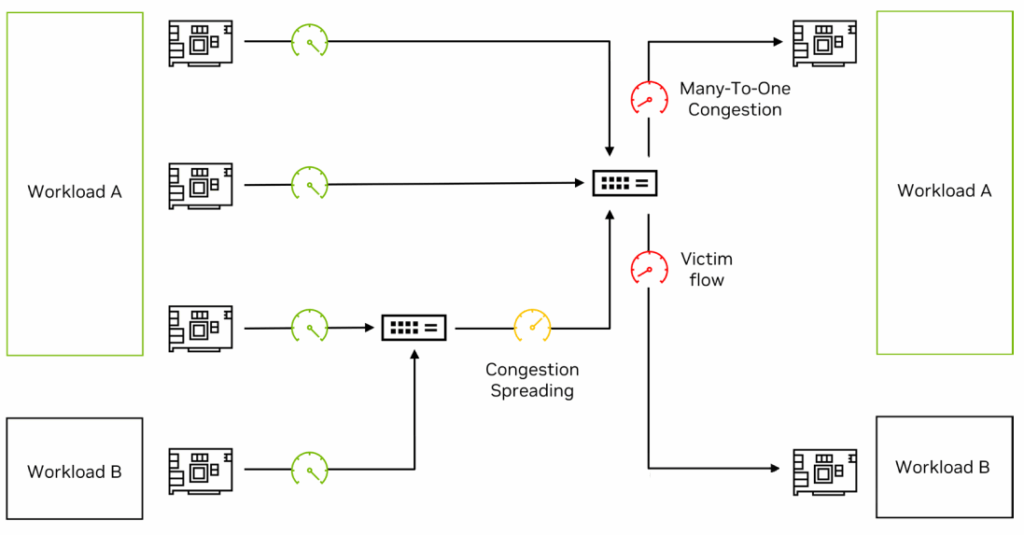
Figure 13 shows how network congestion causes victim flows. Four source SuperNICs transmit data to two destination SuperNICs. Sources 1, 2, and 3 transmit to Destination 1; each source should receive ⅓ of the available link bandwidth. Source 4 transmits to Destination 2 via the same leaf switch as Source 3, so it should receive ⅔ of the available link bandwidth.
Without congestion control, Sources 1, 2, and 3 cause 3-to-1 congestion because they all send data to Destination 1. This congestion creates backpressure that spreads from Destination 1 to the leaf switch connecting Sources 1 and 2. Source 4 becomes a victim flow, with its throughput to Destination 2 dropping to 33% of available bandwidth (only 50% of expected performance). This adversely affects the performance of AI applications that rely on average and worst-case performance.
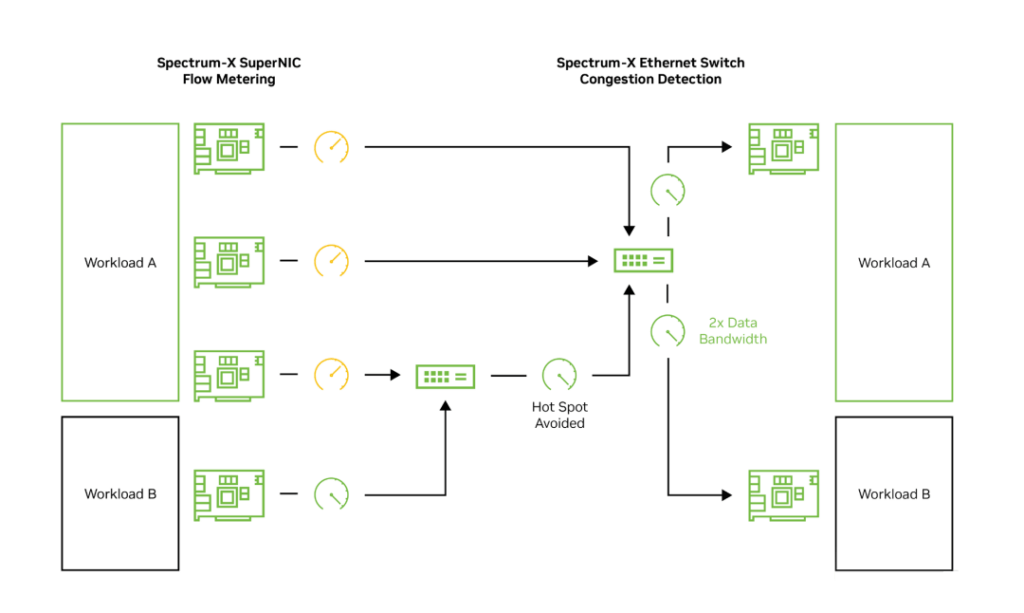
Figure 14 shows how Spectrum-X Ethernet resolves the congestion issue in Figure 13. Using the same setup: four source SuperNICs sending to two destination SuperNICs. In this example, congestion at the leaf switch level is avoided by performing flow metering at Sources 1, 2, and 3. This eliminates the backpressure affecting Source 4. Source 4 receives its full ⅔ effective bandwidth as expected. Additionally, the Spectrum-X Ethernet switch utilizes in-band telemetry generated via What Just Happened to dynamically redistribute flow paths and queue behaviors.
3.2.4. RoCE Performance Isolation
AI factories need to support a large number of users (tenants) and parallel applications or workflows. These users and applications generate traffic that contends for shared infrastructure resources (such as the network), which can impact performance. Furthermore, leveraging the NVIDIA Collective Communication Library (NCCL) to enhance AI network performance requires coordinating and synchronizing all concurrently running workloads in the AI factory. For AI applications, the traditional benefits of cloud computing (such as elasticity and high availability) are relatively limited. Therefore, performance degradation becomes a more significant and global issue.
The Spectrum-X Ethernet platform includes multiple mechanisms that collectively achieve performance isolation, ensuring that one workload does not negatively impact the performance of another. These Quality of Service (QoS) mechanisms prevent any workload from generating network congestion, thereby avoiding obstruction of data transmission for other workloads.
RoCE Adaptive Routing aids this isolation by finely balancing data paths, preventing flow collisions between leaf and spine switches. RoCE Congestion Control further supports isolation via metering and telemetry to prevent the formation of victim flows due to many-to-one host traffic.
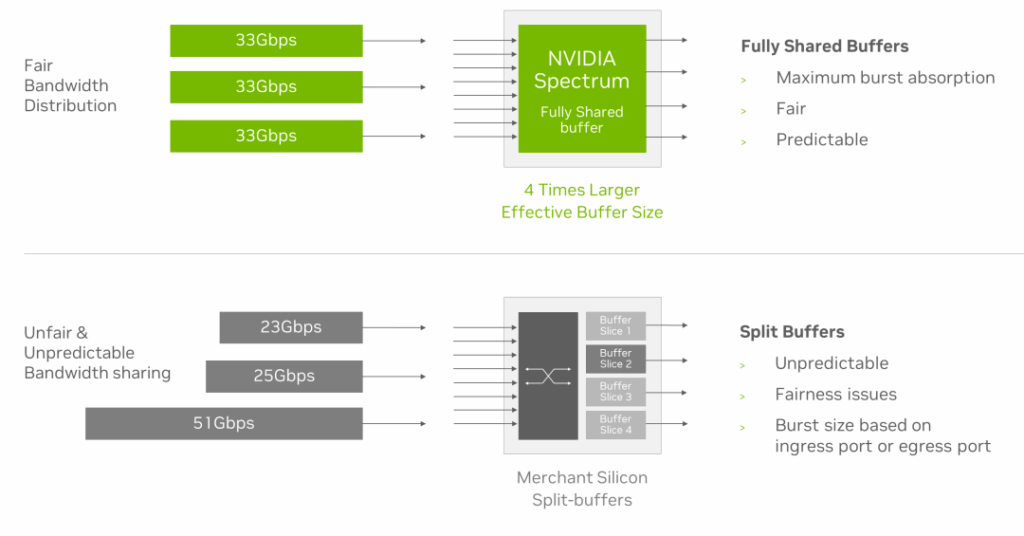
Additionally, the Spectrum-X Ethernet switch further enhances performance isolation through its universal shared buffer design. This design realizes bandwidth fairness between flows of different sizes, protecting workloads from “noisy neighbor” flows, and absorbing larger bursts when multiple flows converge on the same destination port.
NVIDIA Full-Stack Optimization
An AI factory is a precision-engineered machine whose performance can be negatively impacted by seemingly minor network events (such as link or device failures) that might go unnoticed in cloud or enterprise control networks. A single system slowdown can cause a ripple effect, dragging down the operation of the entire AI factory. Moreover, if the network lacks an active monitoring system capable of detecting and mitigating such behaviors, a rogue SuperNIC could interfere with neighboring devices.
NVIDIA employs a multi-stage process to test, certify, and tune Spectrum-X Ethernet components as part of a full-stack AI solution:
- AI Performance Benchmarking: NVIDIA tests the overall AI performance of typical clusters and publishes the results so users understand the expected performance levels of AI clusters built on Spectrum-X Ethernet.
- Component Testing: NVIDIA first tests each component (switch, SuperNIC, GPU, and AI libraries) individually to ensure they function correctly and meet performance benchmarks.
- Integration Testing: After verifying individual component functionality, NVIDIA integrates them to form a unified AI solution. The integrated system undergoes a series of tests to ensure compatibility, interoperability, and seamless communication between components.
- Performance Tuning: Once components are integrated and running as a whole, NVIDIA focuses on optimizing the performance of the full-stack solution. This includes adjusting parameters, identifying bottlenecks, and fine-tuning configurations to maximize the network’s effective bandwidth.
- Overall System Performance: In this phase, NVIDIA specifically tunes buffers and congestion threshold points for AI workloads like GPT, BERT, and RetinaNet to ensure optimal performance for these popular deep learning models.
- Library and Software Optimization: NVIDIA optimizes AI libraries (such as NCCL) to ensure efficient communication between GPUs and other components. This step is crucial for minimizing latency and maximizing throughput in large-scale deep learning applications.
- Certification: After testing and tuning the full-stack AI solution, NVIDIA conducts a series of certifications to ensure the system is reliable and secure. This process includes stress testing, security testing, and verifying compatibility with major AI frameworks and applications.
- Real-World Scenario Testing: Finally, NVIDIA deploys the full-stack AI solution in real-world scenarios to assess its performance under various conditions and workloads. This step helps uncover any unforeseen issues and ensures the solution is ready for widespread customer adoption.
By following this comprehensive process, NVIDIA ensures the robustness, reliability, and high performance of the full-stack AI solution, providing customers with a seamless experience, especially for widely used AI workloads like GPT, Llama, and DeepSeek.
Spectrum-X Ethernet Performance Results from Israel-1 Data Center
NVIDIA’s full-stack optimization delivers significant performance gains for AI workloads. To comprehensively tune and optimize Spectrum-X Ethernet recommended configurations, NVIDIA used Israel-1—a generative AI supercomputer and the largest system in Israel. Israel-1 consists of 4 scalable HGX-H100 system units, each equipped with B3140 SuperNICs and interconnected via three layers of SN5610 Ethernet switches. This system is designed as a blueprint for large AI factories, which NVIDIA customers and partners can replicate to achieve equivalent performance for their own workloads.
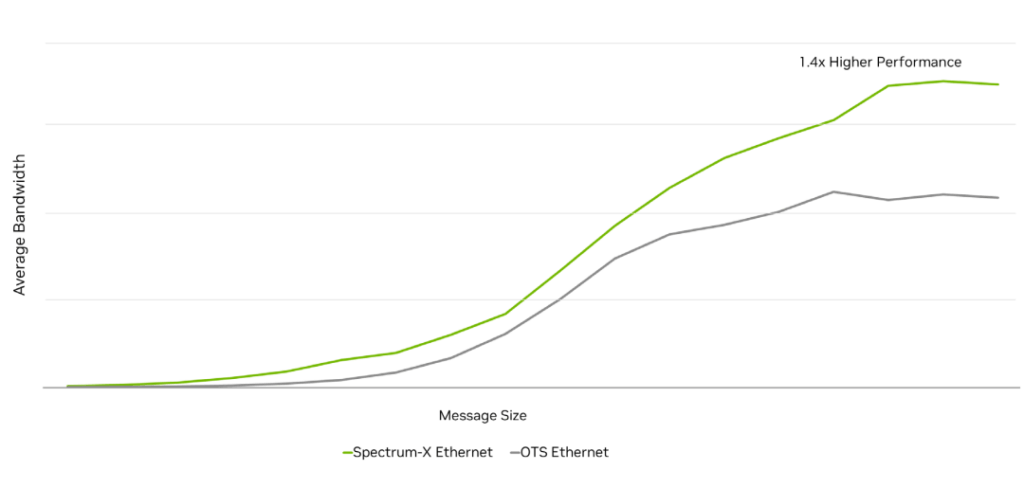
The following benchmarks compare a fully optimized Spectrum-X Ethernet network against a general-purpose off-the-shelf (OTS) Ethernet network optimized for traditional data centers. The OTS Ethernet network utilizes RoCE and standard Ethernet flow control technologies but does not employ the RoCE enhancements and NCCL-aware network optimizations introduced by Spectrum-X Ethernet.
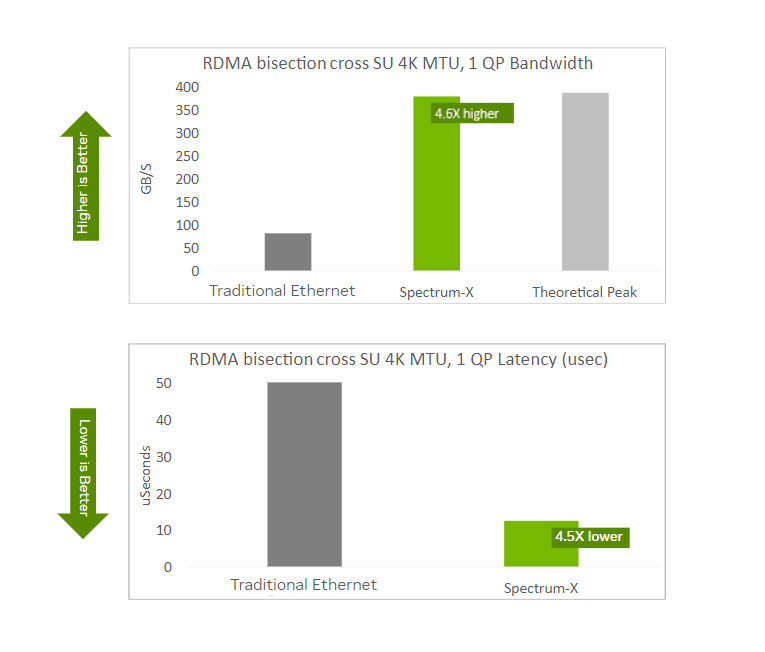
RDMA Network Performance
AI workloads and their network traffic patterns vary significantly by model, but all models require an efficient, reliable, and high-performance RoCE network. The first benchmark result demonstrates effective bandwidth and latency for RDMA bisection. Compared to general-purpose OTS Ethernet, Spectrum-X Ethernet provides significantly better performance (higher effective bandwidth and lower latency).
NCCL Collective Operation Performance
NCCL collective operations (such as all-reduce and all-to-all) are critical to distributed AI performance and are atomic operations for AI training. Spectrum-X Ethernet is designed as an NCCL-aware network, ensuring proper tuning for these operations. The following benchmark results show NCCL operation performance in an AI factory scenario where multiple AI jobs are running simultaneously and generating “noise”. Spectrum-X Ethernet achieves higher NCCL bus bandwidth for both all-reduce and all-to-all operations while providing noise isolation, making its performance nearly as high and consistent as results measured in a “noise-free” scenario (i.e., no other jobs running in the AI factory).

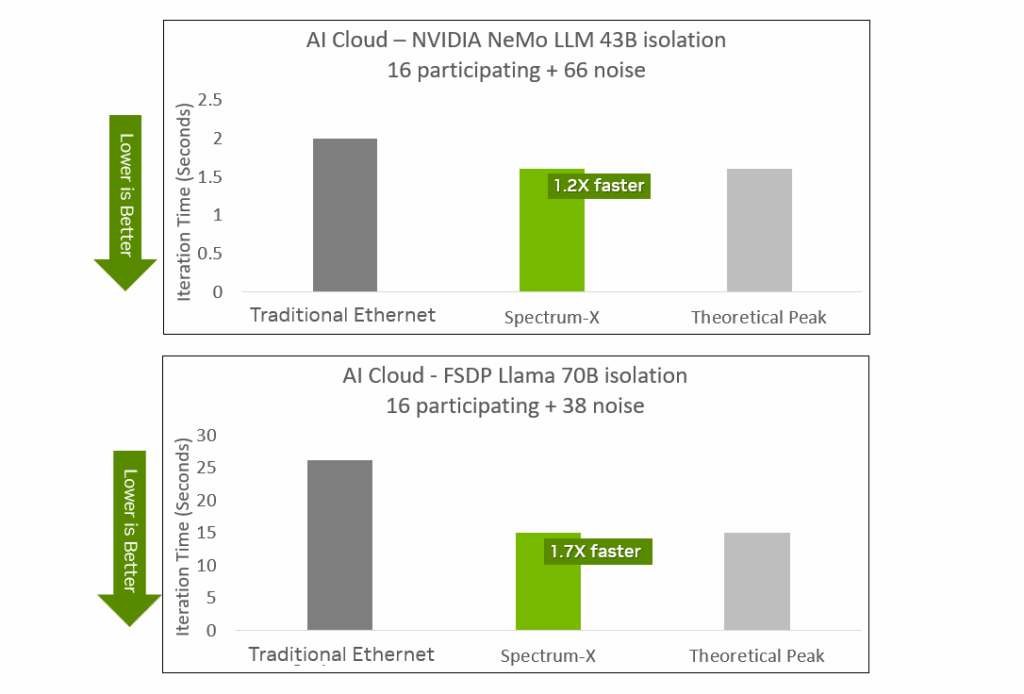
AI Model Performance
The most important goal of network optimization is to achieve the highest application-layer performance. For AI workloads like LLM training, this means reducing iteration step time, thereby shortening job completion time and accelerating time-to-value for AI models. NVIDIA benchmarked training iteration times for several common large language models (including GPT-4, FSDP Llama 70B, and NeMo LLM 43B) in an AI factory. In all test cases, Spectrum-X Ethernet delivered shorter training times and demonstrated stable, predictable performance unaffected by noise.
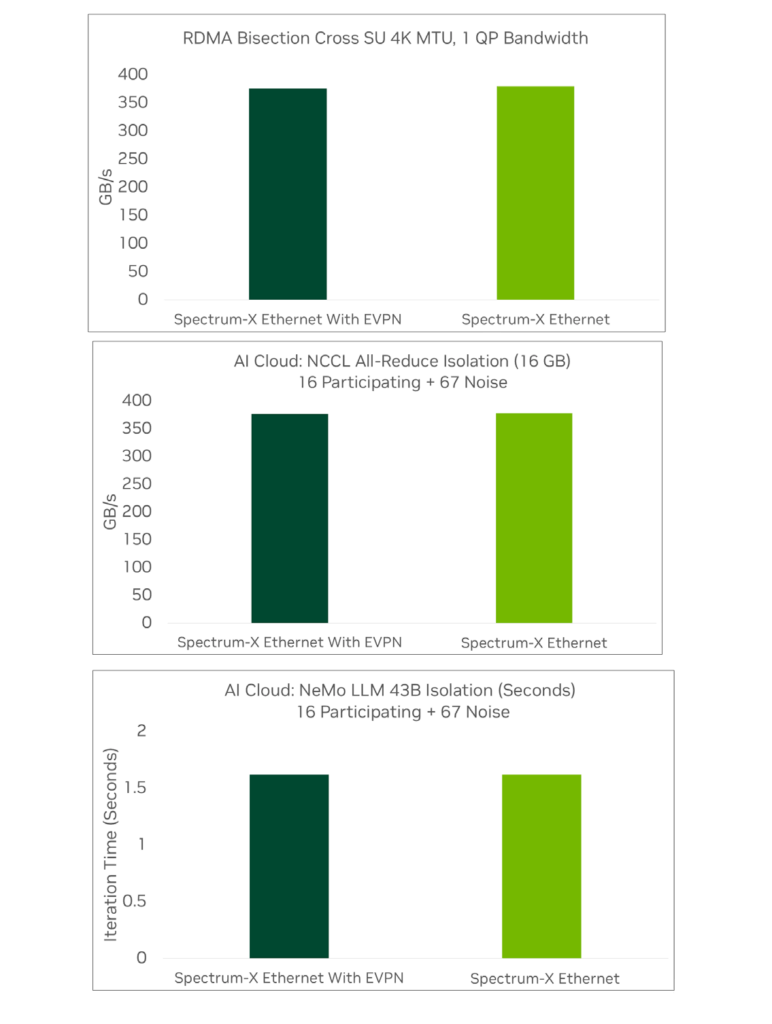
Impact of Virtualization on Performance
As a multi-tenant architecture, AI factories typically require network virtualization via methods like EVPN VXLAN. These virtualization technologies are primarily optimized for scalability and extensibility rather than performance. Without careful implementation, virtualization can lead to significant performance penalties. NVIDIA compared the performance of Spectrum-X Ethernet with and without virtualization via EVPN VXLAN. In all tests, performance in single-tenant and multi-tenant environments was virtually identical, with negligible performance degradation, proving that Spectrum-X Ethernet is the ideal Ethernet architecture for multi-tenant AI factories.
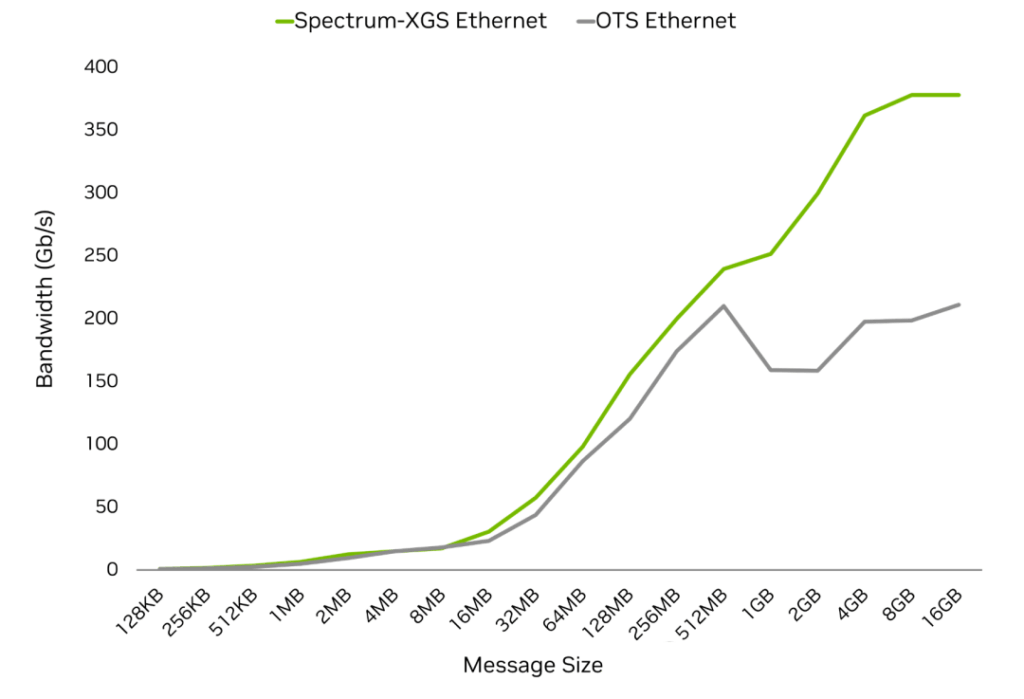
Data Center Cross-Domain Performance
Expanding AI factories within a single building or campus eventually faces hard limits on power supply, cooling capacity, and physical space. To expand capacity, enterprises and CSPs have begun seeking to connect multiple data centers, but this approach has traditionally been constrained by network challenges such as long-tail latency, jitter, and unpredictable performance, which can stall large-scale training.
Cross-Geo Networking overcomes these obstacles by enabling multiple data centers hundreds or even thousands of kilometers apart to operate as a unified computing fabric. Distributed facilities no longer operate as isolated sites but become a massive AI factory where large-scale training and inference can span across locations seamlessly without slowing down due to latency, congestion, or inconsistent performance. Results include faster task completion, higher infrastructure utilization, and the ability to train the largest models by consolidating resources across geographies.
Spectrum-XGS Ethernet is a cross-geo technology seamlessly integrated into the Spectrum-X platform, designed to solve modern data center power constraints. Built on industry-standard Ethernet protocols, it introduces the following features:
- Distance-Aware Congestion Control: Algorithms that account for inter-site distance to optimize flow control and minimize tail latency.
- Topology-Aware Load Balancing: Traffic distribution across multi-site architectures to maximize throughput and eliminate hotspots.
- Deterministic Performance: Precise latency management via real-time telemetry, providing visibility, predictability, and controllability.
Compared to general-purpose off-the-shelf Ethernet, NVIDIA Spectrum-XGS Ethernet boosts the speed of multi-site NCCL collective operations by 1.9x, enabling geographically dispersed data centers to truly operate as a single entity.
Ethernet Built for AI
The Spectrum-X Ethernet network platform is built specifically for demanding AI applications and offers a range of advantages over general-purpose off-the-shelf (OTS) Ethernet. With higher performance, lower power consumption, lower total cost of ownership, seamless full-stack hardware and software integration, and massive scalability, Spectrum-X Ethernet has become the ultimate Ethernet platform for current and future AI workloads.
Related Products:
-
 NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MCP7Y00-N001 Compatible 1m (3ft) 800Gb Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Direct Attach Copper Cable
$160.00
-
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$800.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MCP7Y70-H001 Compatible 1m (3ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$120.00











