
Network Requirements for Large Model Training
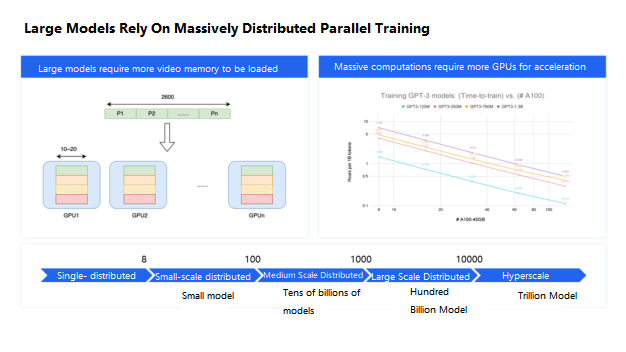
In the past half year, large models have continued to be a hot topic. Although there is still much debate about the development and application of large models, the capabilities of large models have certainly become the foundation for the future development of artificial intelligence. Compared to previous small models, large models have a stronger demand for large-scale distributed parallel training.
This is due to two main reasons: The models themselves are very large. Due to the current limitations of GPU memory, we have to divide a model into many GPUs for storage. For example, FiberMall’s large model has 260 billion parameters, but in reality, a single A800 GPU with 80GB of memory can only store about 1-2 billion parameters, including the computational states during training. Storing a 260 billion parameter model alone would require hundreds of GPUs, which is already a relatively large scale.
Training more parameters requires more computational power, so we must introduce larger-scale GPUs for acceleration, which means the number of GPUs required will also increase by an order of magnitude.
At FiberMall, we name the training scale based on the number of GPUs used for a task. For example, we call it small-scale if it’s less than 100 cards, medium-scale if it’s between 100 and 1,000 cards, large-scale if it’s over 1,000 cards, and super-large-scale if it’s over 10,000 cards. According to this naming convention, we can say that large-scale parallel training of over 1,000 cards is the foundation for the success of large models.
There are several common strategies for distributed parallel training of machine learning models. We will outline three of the most widely used approaches.
The most widely adopted strategy is data parallelism. In data parallelism, each GPU maintains an identical copy of the model, and the dataset is partitioned and distributed across the GPUs for training. After each training iteration, the gradients computed on each GPU are synchronized globally, and the model parameters for the next iteration are then updated accordingly across all GPUs. In data parallelism, an Allreduce operation is required to aggregate the gradients across the GPUs, and the communication volume scales with the size of the model parameters, which can be substantial for large-scale models with billions of parameters.
The second parallel strategy is pipeline parallelism. Neural network models are typically composed of multiple layers of neurons, including the deep Transformer models. In pipeline parallelism, the model is partitioned by layer, with different layers assigned to different GPUs. This approach requires point-to-point data transfers between the GPUs for passing activations during the forward pass and gradients during the backward pass. While the communication occurs multiple times per iteration, the volume of data transferred is generally not large, and the network performance requirements are relatively modest.
The third parallel strategy is tensor parallelism, which involves jointly utilizing multiple GPUs to perform a single tensor computation, such as matrix multiplication. This approach requires an Allreduce operation to synchronize the partial tensor computation results across the GPUs. The size of the tensors being computed depends on both the model architecture and the batch size used for training, and these tensor computations occur frequently during each training iteration. As a result, tensor parallelism places the highest demand.
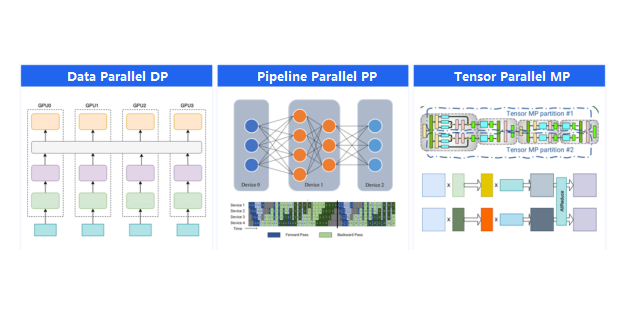
Considering the characteristics of the three parallel strategies, a hybrid approach is commonly adopted when training large-scale models.
Within a single machine with multiple GPUs, tensor parallelism is employed to fully leverage the high-bandwidth NVLink connections between the GPUs.
Since a single machine with 8 GPUs may not be sufficient to accommodate the entire large model, pipeline parallelism is used across multiple machines to construct a minimum training unit with parallel pipelines.
To further accelerate the model training, data parallelism is then applied, where each data parallel (DP) group consists of a combination of tensor parallelism and pipeline parallelism.
The Allreduce operations in data parallelism occur within each DP group, where the gradients are synchronized across the GPUs of the same DP group. For example, the diagram shows a configuration with 8 GPUs in tensor parallelism, 4 GPUs in pipeline parallelism, and 3 DP groups. In this case, there are 32 Allreduce groups, each with 3 GPUs performing gradient synchronization.
The primary network requirement for training large models is the Allreduce operation in the data parallelism stage, where each GPU needs to participate in Allreduce on data volumes in the 10GB range.

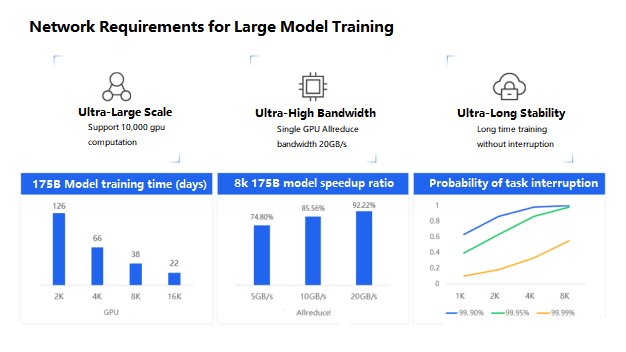
The need for large-scale model training has led us to propose three key objectives for high-performance AI networks: ultra-large-scale, ultra-high bandwidth, and ultra-long stability.
Ultra-Large Scale
The size of the model directly determines the speed of model training. As shown in the figure, for a 175 billion parameter model, it would take over 100 days to train using 2,000 GPUs. However, by using 8,000 GPUs, the training time can be compressed to around 30 days. This is crucial for the rapid iteration of large-scale models today.
Ultra-High Bandwidth
The AllReduce bandwidth directly determines the overall efficiency of large-scale distributed training. As the figure shows, when the average single-GPU AllReduce bandwidth is 5GB/s, the overall acceleration ratio in large-scale distributed training is only 70%. To achieve a 90% acceleration ratio, the single-GPU AllReduce bandwidth needs to reach 20GB/s, equivalent to a single GPU fully utilizing a 400G network card.
Ultra-Long Stability
Given that model training can last for several weeks, long-term stability is of utmost importance. Using GPU availability as an example, if the monthly availability of a single GPU is 99.9%, the probability of encountering a failure and interruption during one month of training with 1,000 GPUs is 60%. Even if the GPU availability is improved to 99.99%, the interruption probability with 8,000 GPUs is still around 50%. To minimize training interruptions and reduce the need for frequent checkpointing, the network must ensure even higher availability.
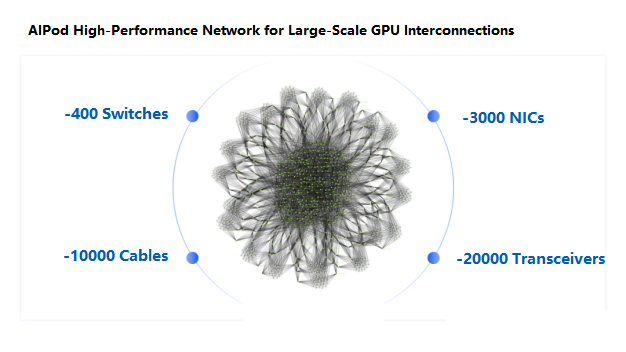
AIPod High-Performance Network Design
To address these objectives, we have designed the AIPod high-performance network for AI infrastructure.
As shown in the diagram, the AIPod network is a fully connected topology with approximately 400 switches, 3,000 network cards, 10,000 cables, and 20,000 optical modules. The total cable length is equivalent to the distance from Beijing to Qingdao.
Rational Design of the AIPod Network
After the previous discussion on the conceptual understanding, let’s now delve into the rational design of the AIPod network.
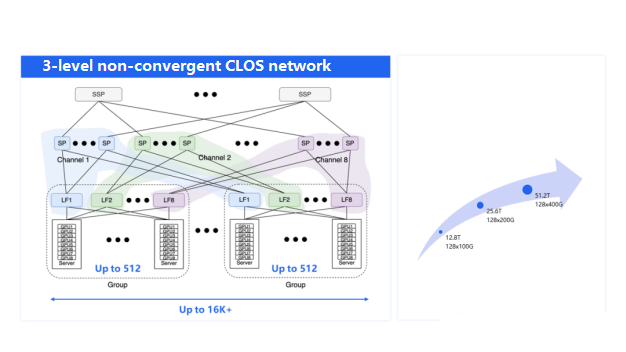
To support the massive scale of the AIPod network, a 3-tier non-blocking CLOS network architecture was chosen. The CLOS network topology is similar to the diagram shown earlier, where:
Servers are connected to the Leaf (LF) layer switches.
Leaf switches interconnect with the Spine (SP) switches.
Spine switches are further connected to the SuperSpine (SSP) layer.
As mentioned earlier, during large model training, the primary communication occurs between GPUs of the same server, i.e., GPU 1 to GPU 1, GPU 2 to GPU 2, and so on. Cross-GPU communication is less frequent.
To accommodate this communication pattern, the AIPod network adopts an 8-channel architecture. Each server has 8 network ports, each connected to a different Leaf switch. These 8 Leaf switches form an aggregation group, supporting up to 512 GPUs.
Further, the 8 Leaf switches are connected to different channels, and within each channel, the Leaf and Spine switches are in a full-mesh topology. This design allows the cluster to scale to support over 16K GPUs.
Although the majority of the communication happens within the same channel, there is still a need for cross-channel communication. To address this, the AIPod network uses the SuperSpine layer to interconnect the Spine switches of different channels, providing a seamless communication path across the entire network.
The AIPod network employs a non-blocking or 1:1 oversubscription ratio design, where the uplink and downlink bandwidth of the switches are equal, ensuring sufficient intra-cluster bandwidth.
To support the largest possible scale, the AIPod network utilizes the latest high-capacity switch chips, such as the 51.2T switch, which have evolved from the previous 12.8T and 25.6T generations.
This rational design of the AIPod network, with its multi-tier CLOS architecture, channel-based communication, and high-capacity switching components, enables the support of massive-scale AI training workloads.
In the previous discussion, we covered the construction of large-scale AIPod networks. Now, let’s turn our attention to the challenges related to network bandwidth.
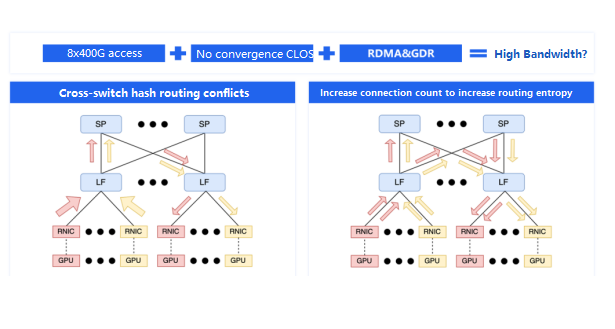
FiberMall’s intelligent cloud infrastructure has chosen a maximum server access specification of 8x400G, and the network utilizes a non-blocking CLOS architecture, supporting RDMA and GDR. Theoretically, this should provide very high bandwidth capabilities. However, as the scale of the network increases, various problems can arise, one of the most significant being path selection conflicts across switches.
Technically, almost all network transmissions have an inherent issue: to avoid packet reordering within a connection, which can trigger retransmission and performance degradation at the receiving end, switches need to forward packets of the same connection along a single path. The selection of this path depends on the hash algorithm used.
Hash algorithms are known to have collisions, as illustrated in the diagram. If two cross-switch connections simultaneously choose the same left-side link, it will become congested, while the right-side link remains underutilized, effectively halving the bandwidth of both connections. This problem is quite common in large-scale training environments.
To mitigate the impact of this issue, we typically configure the NCCL communication library to use multiple connections between GPUs, as shown in the diagram on the right. The more connections, the lower the probability of severe imbalance. This approach increases the routing entropy in the network and reduces the impact of hash-based path selection conflicts, but it does not completely solve the problem.
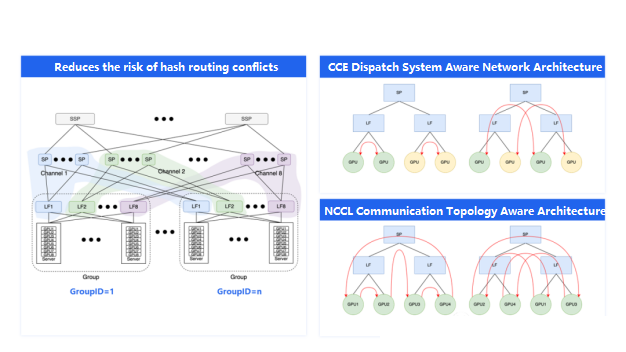
We can observe that these issues only occur in cross-switch communication scenarios. Therefore, to further reduce the impact, we should strive to keep communication within a single switch whenever possible. Intra-aggregation group communication between GPUs of the same number does not cross switches and thus avoids the hash-based path selection conflict. This is why we aim to maximize the size of each aggregation group.
To reduce cross-switch communication, the AIPod network provides a network architecture-aware approach. This allows the upper-level systems to be aware of the current GPU’s position in the network architecture, its aggregation group, and its GroupID.
The AIPod can expose this information to the task scheduling system, enabling it to schedule tasks within the same aggregation group as much as possible, ensuring that communication remains within a single aggregation group.
However, large model tasks are often too large to be confined within a single aggregation group. In such cases, we need to leverage the aggregation group information to perform orderly processing of the global GPU resources, allowing the communication library to construct more efficient Allreduce topologies that minimize cross-switch traffic. The diagram in the bottom right illustrates this concept, where two different ring construction orders for a 4-GPU Allreduce operation can result in significantly different cross-switch bandwidth utilization. The left-side approach is more efficient, while the right-side is less efficient. This is the benefit of the network architecture-aware capabilities in the AIPod.
The network architecture-aware approach can significantly reduce the amount of cross-switch communication, mitigating the impact of hash-based path selection conflicts. However, the problem is not completely solved, as conflicts can still occur.
To fully address this issue, we need to leverage the network’s multi-path forwarding capabilities, which allow for out-of-order packet reception, breaking the assumption that packets of a single connection can only be forwarded along a single path. Infiniband networks have introduced this adaptive routing capability, and in the AIPod, we have implemented a similar functionality using dynamic load balancing (DLB) technology on top of FiberMall’s custom-built switches.
In this approach, as illustrated in the diagram, the network interface card first marks the packets to allow for out-of-order processing. The switches then calculate the optimal path for each packet based on factors such as queue depth and link utilization. This introduces the challenge of packet reordering, which is addressed by the receiver through packet reordering processing.
This combination of mechanisms can effectively solve the hash-based path selection conflict problem in cross-switch communication. We believe that enhancing these underlying technical capabilities is the ultimate solution for large-scale training.
Ensuring Stability in AIPod Networks
Maintaining long-running tasks without interruption is crucial for large model training, but hardware failures are inevitable. For a cluster that can accommodate 16,000 GPUs, there may be nearly 100,000 optical modules. Assuming a mean time between failures (MTBF) of 10 million hours per module, with such a large base, a failure can occur approximately every 4 days on average, as low-probability events become high-probability events at scale.
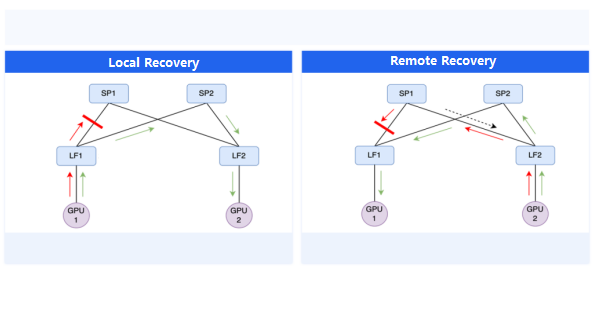
To address this, the AIPod network is designed to enable rapid recovery from hardware failures. For example, suppose a link in the network experiences a failure, causing packet loss. In that case, the AIPod must ensure that the duration of this packet loss is less than the typical timeout set by the communication library, preventing task interruption.
For uplink packet loss, the AIPod’s dynamic load balancing technology can provide millisecond-scale recovery by selecting an alternative available link. For downlink packet loss, the AIPod triggers network routing updates and convergence, optimizing the routing update strategy and distribution efficiency to keep the downlink packet loss duration within the second-level.
Additionally, the AIPod network includes a black-box detection mechanism to proactively identify hidden issues, such as bit-flip problems caused by switch chip defects, which can lead to packet corruption and loss without explicit failure detection. This mechanism ensures that every link is continuously monitored, and any connectivity issues trigger automatic localization and isolation, as well as alerts for rapid intervention by the operations team.
Beyond connectivity-related failures, the AIPod’s lossless network design, enabled by PFC technology, can also experience anomalies, such as PFC deadlocks or persistent PFC storms due to chip failures. The AIPod addresses these challenges through a performance telemetry platform, built on FiberMall’s custom switches, which provides visibility into any packet loss, PFC, or buffer anomalies, allowing for rapid detection and resolution before impacting the stability of large model training.
Achieving Ultra-Low Latency in AIPod Networks
While low latency is not a core consideration for large model training, where bandwidth is the primary concern, the AIPod network is also designed to support latency-sensitive AI workloads.
The key factors that can be optimized for low latency are fiber delay and switch queuing delay. The AIPod network optimizes the physical layout of the cluster to minimize the distance between servers, switches, and switches, allowing the use of shorter fiber connections to reduce the fiber propagation delay.
Additionally, the AIPod network optimizes the congestion control parameters to minimize the switch buffer occupancy, which directly impacts the queuing delay. With these optimizations, the AIPod can achieve microsecond-level network latency, which is negligible in the context of end-to-end large model training performance.
Leveraging High-Performance Storage in AIPod
In addition to the high-performance training network, the AIPod also leverages FiberMall’s high-performance storage capabilities, such as the elastic RDMA-based parallel file system (PFS) that can deliver up to 200Gbps per client, and the high-performance hardware load balancing instances for accessing cloud file storage (CFS) or object storage (BOS), providing over 10Gbps of stable bandwidth per client.
These high-performance storage technologies contribute significantly to the overall computational efficiency of large model training.
AIPod Large Model Training in Practice
FiberMall has demonstrated the practical application of the AIPod network in large-scale model training, showcasing stable operation with per-GPU communication bandwidth exceeding 100Gbps on both RoCE and Infiniband clusters.
To support these large-scale training efforts, FiberMall has developed specialized tools, including a high-precision task visualization tool that can aggregate and analyze the network traffic data of thousands of parallel instances, as well as a fault diagnosis tool that can quickly identify the root cause of various anomalies, such as GPU failures or slow nodes, which can otherwise hinder the overall training performance.
The AIPod high-performance network, supporting tools, and storage capabilities enable FiberMall’s customers to train large models efficiently and cost-effectively, maintaining a leading position in the era of large-scale AI models.
Related Products:
-
 NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$850.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00







