
Compute Chips—V100, A100, H100, B200, etc.
These terms are among the most commonly encountered in discussions about artificial intelligence. They refer to AI compute cards, specifically GPU models.

NVIDIA releases a new GPU architecture every few years, each named after a renowned scientist. Cards based on a particular architecture typically start with the first letter of the architecture’s name, except for gaming GPUs. For instance:
- V100 is based on the Volta architecture (named after Alessandro Volta).
- A100 derives from the Ampere architecture (named after André-Marie Ampère).
- H100/H200 originates from Hopper (named after Grace Hopper).
- B100/B200 come from Blackwell (named after David Blackwell).
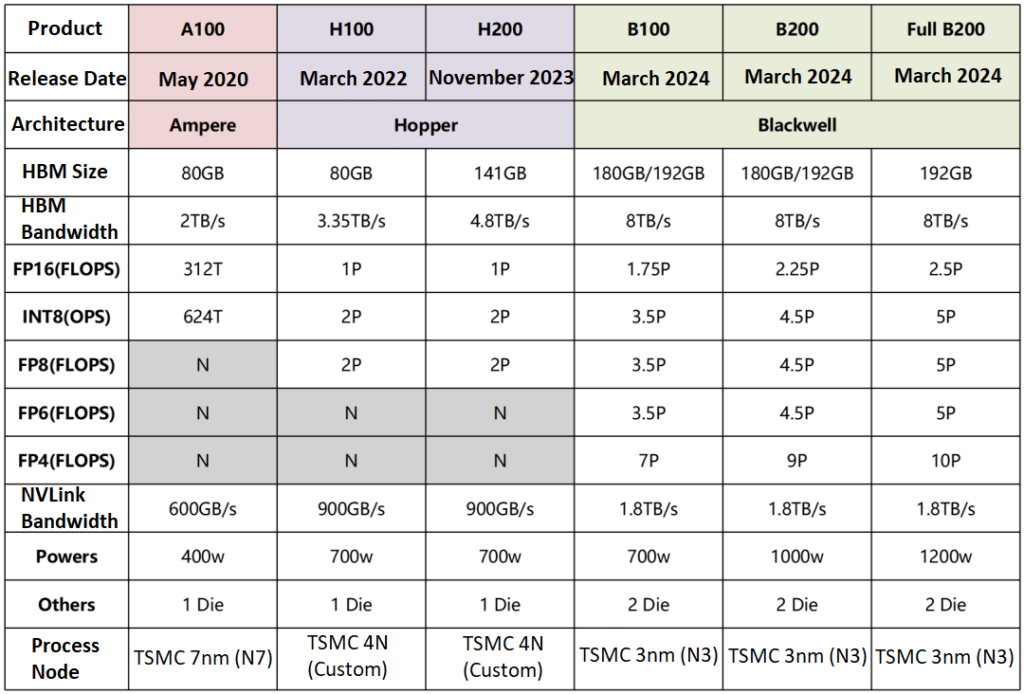
A model ending in “200” is typically an upgraded version of its “100” predecessor. For example, the H200 is an enhanced version of the H100, featuring improvements such as HBM3e memory.
L40 & L40s. These two models are slightly different in naming. They are based on the Ada Lovelace architecture (honoring the first female programmer). The L40s is an upgraded version of the L40. Both are designed for data center markets, focusing on cost efficiency and performance.
H20 & Export Restrictions The H20 is a modified version of NVIDIA’s GPUs created in response to U.S. export restrictions. Similarly, reports suggest that the B200 may have a restricted variant called B20.
Future Architectures NVIDIA’s next-generation AI platform, Rubin, is scheduled for release in 2026. Initially, many expected GPUs to be labeled R100/R200, but NVIDIA’s roadmap instead suggests an X100 series, leaving room for speculation. By 2028, the company plans to launch the subsequent platform, Feynman.
Superchips—GH200, GB200, etc.
While GPUs form the core of NVIDIA’s computing power, the company also develops complementary solutions beyond GPUs.
Early Partnerships & CPU Development Initially, NVIDIA collaborated with IBM’s POWER CPUs. However, due to performance concerns, the company began developing its own CPUs, such as the Grace CPU (ARM-based), with the Vera CPU also in development.
Using NVLink technology, NVIDIA pairs GPUs and CPUs to create Superchip platforms. Examples include:
- GH200 (Grace CPU + Hopper GPU)
- GB200 (Grace CPU + two Blackwell B200 GPUs)
- GB300 (Blackwell Ultra)
The GB200 is particularly powerful, boasting approximately seven times the performance of the H100.

Supercomputer Platforms—DGX, EGX, IGX, etc.
At a higher computing tier, NVIDIA has developed supercomputer platforms based on these chip architectures, including DGX, EGX, IGX, HGX, and MGX.
The DGX series is well known, with Jensen Huang gifting the first-generation DGX-1 to OpenAI.

Today, modern DGX systems typically feature a signature gold design and premium pricing.
For desktop applications, NVIDIA offers DGX Spark and DGX Station, functioning as workstation-class machines.

Intra-Node Connectivity—Scale Up (Supernodes)—DGX GB200 NVL72
At the communication level, NVIDIA has developed NVLink, a technology designed to interconnect GPUs, effectively replacing PCIe. It also connects CPUs and GPUs via NVLink.
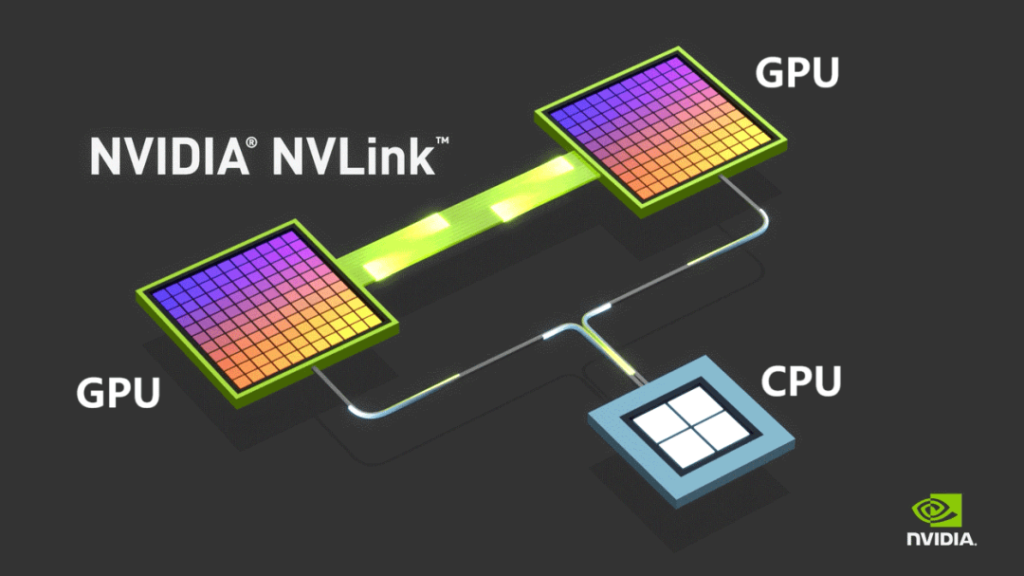
For multi-node setups, direct NVLink connections become impractical, requiring NVLink Switch chips, also known as NVSwitch. Over time, these chips evolved into standalone devices.
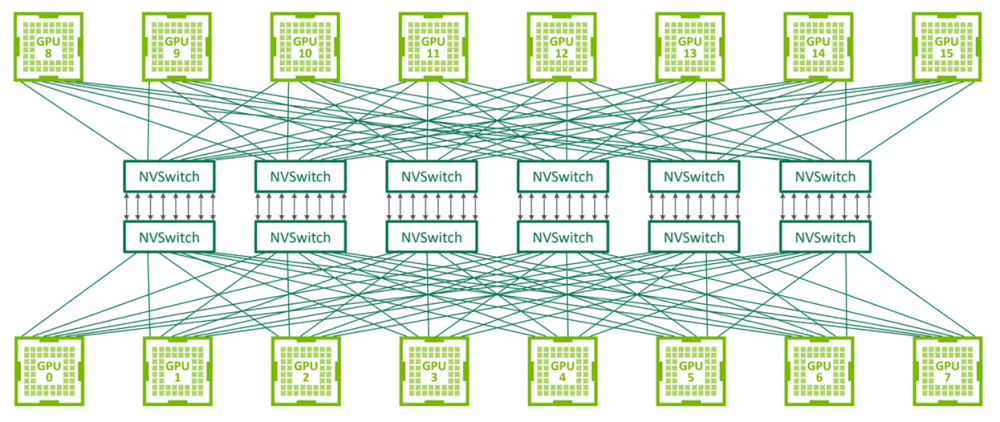
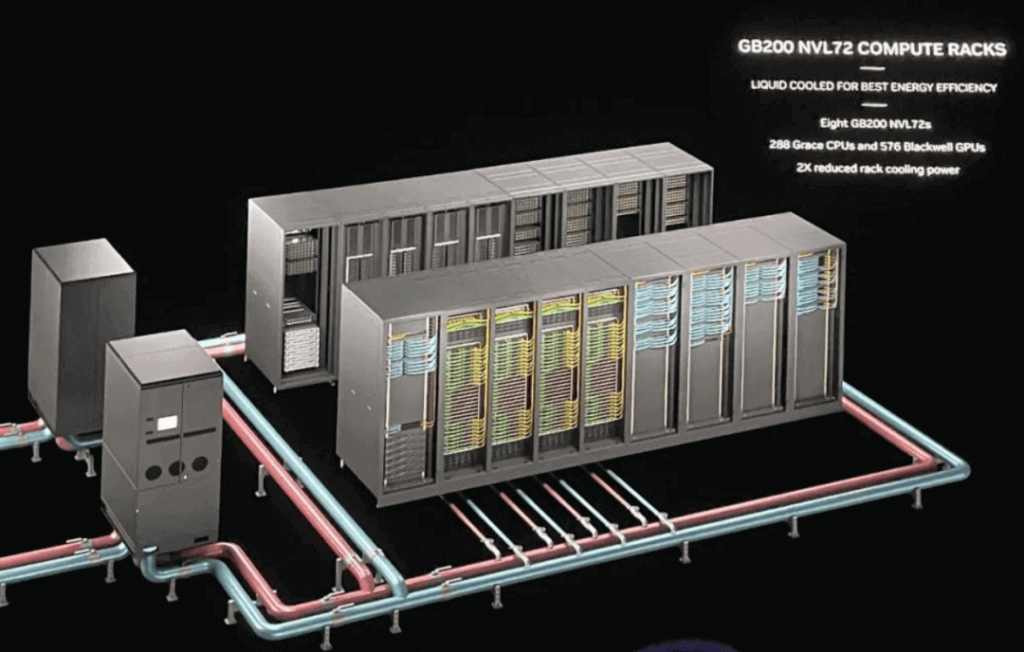
NVLink enables the connection of numerous GPUs into a unified logical node—an ultra-scale computing platform. A frequently mentioned setup is DGX GB200 NVL72, utilizing NVLink5 with:
- 18 Compute Trays (each containing two GB200 Superchips)
- 9 NVLink Network Switch Trays
Each Compute Tray houses: 2 GB200 Superchips (totaling 36 Grace CPUs and 72 B200 GPUs across the full system).

Additionally, eight DGX GB200 NVL72 units can be combined to create a SuperPod node with 576 GPUs.
This structured product ecosystem defines NVIDIA’s positioning in AI and high-performance computing.
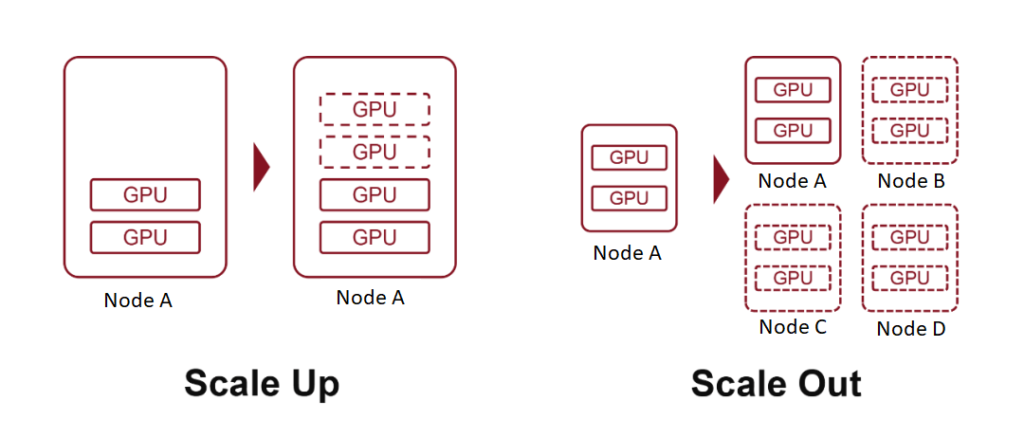
External Node Interconnection: Scale-Out (IB and Ethernet)
Within a single node, continuously adding GPUs is referred to as Scale-Up (vertical expansion). However, once a node reaches a certain size, further expansion becomes challenging. At this point, increasing the number of nodes and interconnecting them becomes necessary—this is known as Scale-Out (horizontal expansion).
NVIDIA provides solutions for Scale-Out, primarily through InfiniBand (IB) technology. Originally developed by Mellanox, InfiniBand became a proprietary NVIDIA technology after NVIDIA acquired Mellanox in 2019. InfiniBand is a technical term rather than a product name; NVIDIA’s product platform based on InfiniBand is NVIDIA Quantum.
For instance, in March 2024, NVIDIA unveiled the Quantum-X800 network switch platform, which achieves an end-to-end throughput of 800 Gbps. This platform includes hardware such as the Quantum Q3400 switch and ConnectX-8 SuperNIC network cards. These components belong to a broader series—Quantum-X800 follows its predecessor Quantum-2, while ConnectX-8 was preceded by ConnectX-6 and ConnectX-7.

The ConnectX high-speed network card also originates from Mellanox. InfiniBand is one of the two primary Scale-Out solutions; the other is Ethernet. NVIDIA has also developed products in this space, notably the Spectrum-X800 platform. The Spectrum-X800 lineup includes Spectrum SN5600 switches and BlueField-3 SuperNIC network cards, with a similarly high 800Gbps throughput.

BlueField has gained significant attention as a Data Processing Unit (DPU). NVIDIA combined Mellanox’s ConnectX network card technology with its own innovations, officially launching the BlueField-2 DPU and BlueField-2X DPU in 2020. Since then, the technology has evolved into BlueField-3.
Furthermore, NVIDIA has recently introduced CPO (Co-Packaged Optics) integrated network switches, including Spectrum-X Photonics and Quantum-X Photonics.

NVIDIA offers additional networking accessories, including various network cards, connectors, and cables, but a detailed discussion of each is beyond the scope here.
Recently, Jensen Huang hinted that the upcoming Rubin platform release would include NVLink 6, ConnectX-9 SuperNIC, and Quantum (Spectrum)-X1600—something worth anticipating.
Development Framework: CUDA
After discussing NVIDIA’s compute hardware platforms and networking solutions, it’s time to explore CUDA, a crucial software component.
While NVIDIA excels in hardware and networking, its CUDA platform is widely regarded as its core competitive advantage. CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model introduced by NVIDIA in 2006. It enables developers to write code directly for GPUs, significantly accelerating computational performance.
Today, CUDA serves as the operating system for intelligent computing, integrating a programming model, compiler, APIs, libraries, and tools, helping users maximize NVIDIA hardware capabilities.
Beyond being a tool, CUDA fosters a powerful AI development ecosystem, functioning as the central nervous system of NVIDIA’s entire business framework. Many AI development projects heavily rely on NVIDIA’s hardware and CUDA, while switching hardware is relatively straightforward, migrating the ecosystem as a whole presents a much greater challenge.
Related Products:
-
 NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA MFP7E10-N010 Compatible 10m (33ft) 8 Fibers Low Insertion Loss Female to Female MPO Trunk Cable Polarity B APC to APC LSZH Multimode OM3 50/125
$47.00
-
NVIDIA MCP7Y00-N003-FLT Compatible 3m (10ft) 800G Twin-port OSFP to 2x400G Flat Top OSFP InfiniBand NDR Breakout DAC
$260.00
-
NVIDIA MCP7Y70-H002 Compatible 2m (7ft) 400G Twin-port 2x200G OSFP to 4x100G QSFP56 Passive Breakout Direct Attach Copper Cable
$155.00
-
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
NVIDIA MCP7Y10-N002 Compatible 2m (7ft) 800G InfiniBand NDR Twin-port OSFP to 2x400G QSFP112 Breakout DAC
$190.00











