
The year 2023 witnessed the full rise of AI artificial intelligence technology, represented by large AIGC models such as ChatGPT, GPT-4, Ernie Bot, etc. They integrated multiple functions such as text writing, code development, poetry creation, etc., and impressively demonstrated their excellent content production capabilities, bringing people a profound shock. As an IT professional, the communication technology behind the AIGC large models should also arouse deep thinking. Without a good network, there is no way to talk about large model training. To build a large-scale training model cluster, not only basic components such as GPU servers, network cards, etc. are needed, but also the problem of network construction is urgently to be solved. What kind of powerful network is supporting the operation of AIGC? How will the full arrival of the AI wave bring revolutionary changes to the traditional network?

The reason why the AIGC large models mentioned earlier are so powerful is not only because they have a huge amount of data feeding behind them, but also because the algorithms are constantly evolving and upgrading. More importantly, the scale of human computing power has developed to a certain extent. The powerful computing power infrastructure can fully support the computing needs of AIGC. In training large models, since the size of the model usually exceeds the memory and computing power of a single GPU, multiple GPUs are needed to share the load. In the process of large model training, there are three ways of GPU load sharing, namely tensor parallelism, pipeline parallelism, and data parallelism.
Data Parallelism:
Data parallelism is a simple and direct parallelization technique, where complete copies of the model are replicated on multiple processors (such as GPUs). Each processor or GPU gets a copy of the entire model and independently performs forward and backward propagation on different subsets of data. After each training step, the model weight updates from all processors need to be merged or synchronized, which is usually done by some form of collective communication operation (such as all-reduce). Data parallelism allows the model to be trained on larger datasets, as the data is split into multiple small batches, each processed on a different processor.
Imagine a large library where you need to categorize all the books. Data parallelism is like hiring multiple librarians, each responsible for categorizing a portion of the books. In the case of model training, each GPU gets a copy of the entire model but only processes a part of the entire dataset. After all GPUs finish their respective tasks, they exchange information to update the model weights synchronously.
Tensor Parallelism:
Tensor parallelism is usually used when the model is too large to fit in the memory of a single processor. In this parallelization strategy, different parts of the model (such as different tensors or parameter groups in neural network layers) are assigned to different processors. This means that each processor is only responsible for computing a part of the model. To complete the forward and backward propagation of the entire model, the processors have to frequently exchange their intermediate results, which may lead to high communication overhead. Tensor parallelism requires high-speed connections between processors, to minimize the latency of these exchanges.
Suppose data parallelism is multiple librarians each handling a part of the books. In that case, tensor parallelism is like each librarian being responsible for a part of the steps of the categorization work. In model training, each GPU is responsible for a part of the computation in the model, for example, one GPU is responsible for computing the first half of the model’s layers, and another GPU is responsible for the second half. In this way, each layer of the model can be computed across multiple GPUs.
Pipeline Parallelism:
Pipeline parallelism is a parallelization strategy that assigns different layers or parts of the model to different processors and performs computation in a pipelined manner. In pipeline parallelism, the input data is split into multiple micro-batches, each of which passes through each layer of the model sequentially. When a micro-batch finishes the computation of the first layer, it is immediately passed to the next layer, while the first layer starts processing the next micro-batch. This way can reduce the idle time of the processors, but requires careful management of the pipeline, to avoid creating too large stalls, where some processors may pause their work because of waiting for dependent computation results.
Pipeline parallelism is like workers on a factory assembly line, each performing a specific task and then passing the semi-finished product to the next worker. In model training, the model is split into several parts, each of which is executed sequentially on different GPUs. When a GPU finishes its part of the computation, it passes the intermediate result to the next GPU to continue the computation.
In practical deployment, the design of the network must take into account the bandwidth and latency requirements of these parallel strategies to ensure the efficiency and effectiveness of model training. Sometimes, these three parallel strategies are combined to further optimize the training process. For example, a large model may use data parallelism on multiple GPUs to process different subsets of data, while using tensor parallelism within each GPU to handle different parts of the model.
Let’s look at the demand for AI computing power from large model training. With the continuous upgrade of large models, the computing power demand for model training also increases, doubling every three months. The GPT-3 model (175 billion parameters, 45TB training corpus, consuming 3640PFlops/s-Days of computing power), ChatGPT3, uses 128 A100 servers, a total of 1024 A100 cards for training, so a single server node requires 4 100G network channels; while ChatGPT4, ChatGPT5, and other large models, the network requirements will be higher.
AIGC has developed to the present, and the model parameters for training have soared from 100 billion to 10 trillion. To complete such a large-scale training, the number of GPUs supporting the underlying layer has also reached the scale of 10,000 cards.
So the question is, what is the biggest factor affecting GPU utilization?
The answer is network.
As a computing cluster with tens of thousands of GPUs, the data interaction with the storage cluster requires a huge bandwidth. In addition, the GPUs are not independent when performing training calculations, but use mixed parallelism. There is a lot of data exchange between GPUs, which also requires a huge bandwidth.
If the network is not powerful, the data transmission is slow, and the GPU has to wait for the data, decreasing utilization. The decrease in utilization will increase the training time, the cost, and the user experience will deteriorate.
The industry has made a model to calculate the relationship between network bandwidth throughput, communication latency, and GPU utilization, as shown in the following figure:
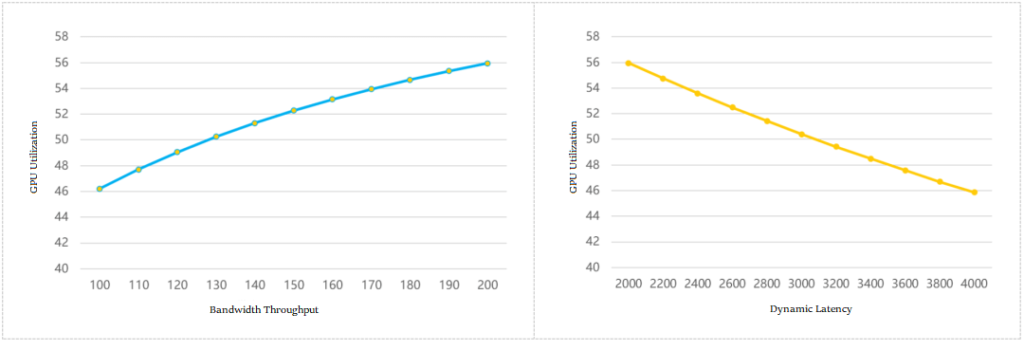
Bandwidth Throughput and GPU Utilization
Dynamic Latency and GPU Utilization
You can see that the stronger the network throughput, the higher the GPU utilization; the greater the communication dynamic latency, the lower the GPU utilization.
What kind of network can support the operation of AIGC?
To cope with the high requirements of AI cluster computing on the network, the industry has proposed various solutions. In traditional strategies, we commonly see three technologies: Infiniband, RDMA, and frame switches.
Infiniband Networking
For professionals who are familiar with data communication, Infiniband networking is not unfamiliar. It is hailed as the best way to build a high-performance network, ensuring extremely high bandwidth, no congestion, and low latency. The network used by ChatGPT and GPT-4 is Infiniband networking. However, the disadvantage of this technology is that it is expensive, and costs several times more than traditional Ethernet networking. In addition, this technology is relatively closed, and there is only one mature supplier in the industry, which limits the user’s choice.
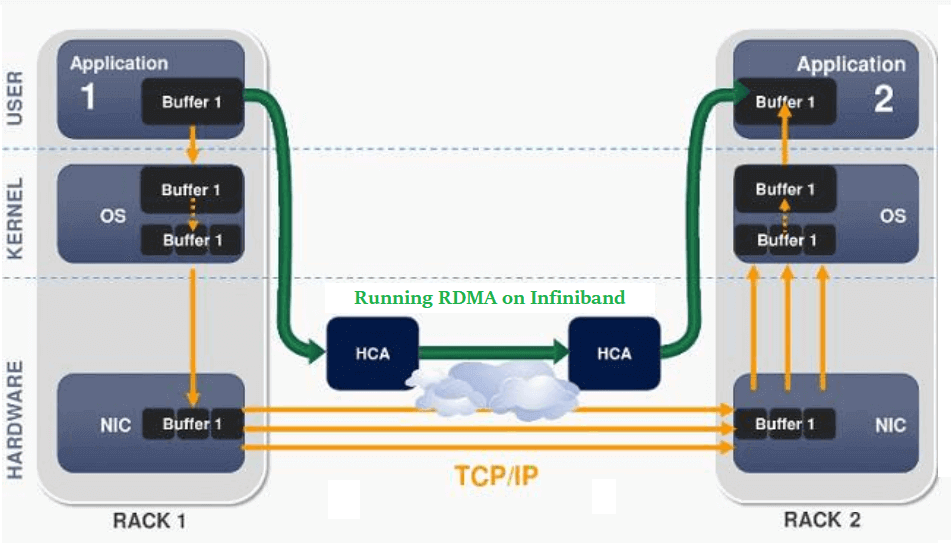
RDMA Networking
RDMA, which stands for Remote Direct Memory Access, is a new type of communication mechanism. In the RDMA scheme, data can communicate directly with the network card, bypassing the CPU and the complex operating system, which not only greatly improves the throughput, but also ensures lower latency.
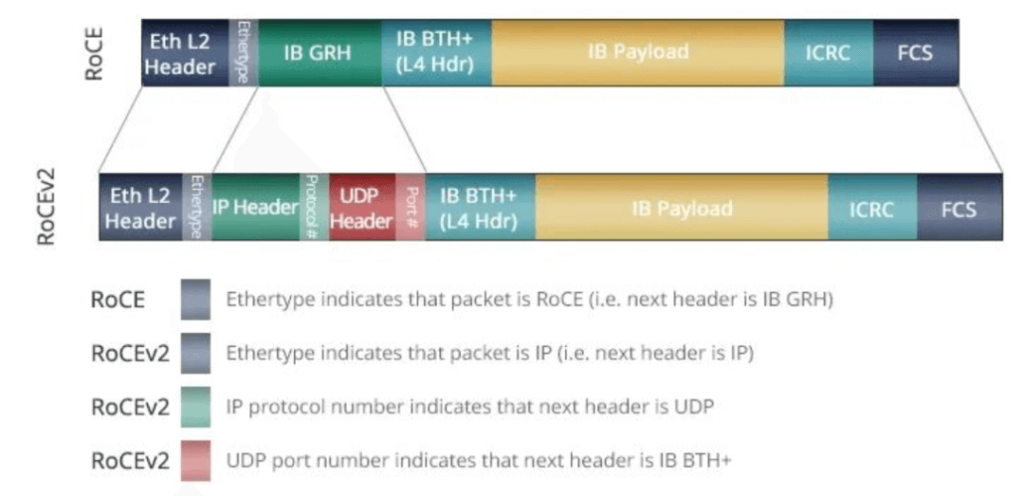
Earlier, RDMA was mainly carried on the InfiniBand network. Now, it has been gradually ported to Ethernet. The current mainstream networking scheme is based on the RoCE v2 protocol to build a network that supports RDMA. However, the PFC and ECN technologies in this scheme, although they are generated to avoid link congestion, may cause the sender to pause or slow down when triggered frequently, thereby affecting the communication bandwidth.
Frame Switch
Some Internet companies had hoped to use frame switches to meet the needs of high-performance networks. However this scheme has challenges such as insufficient scalability, high device power consumption, and large fault domains, so it is only suitable for small-scale AI computing cluster deployment.
New generation of AIGC network: DDC technology
Given the various limitations of traditional schemes, a new solution – DDC (Distributed Disaggregated Chassis) came into being. DDC “disassembles” the traditional frame switch, enhances its scalability, and flexibly designs the network scale according to the size of the AI cluster. Through this innovative way, DDC overcomes the limitations of traditional schemes and provides a more efficient and flexible network architecture for AI computing.

From the perspective of scale and bandwidth throughput, DDC has fully met the network requirements for large-scale AI model training. However, network operation is not only about these two aspects, it also needs to be optimized in terms of latency, load balancing, management efficiency, and so on. To this end, DDC adopts the following technical strategies:
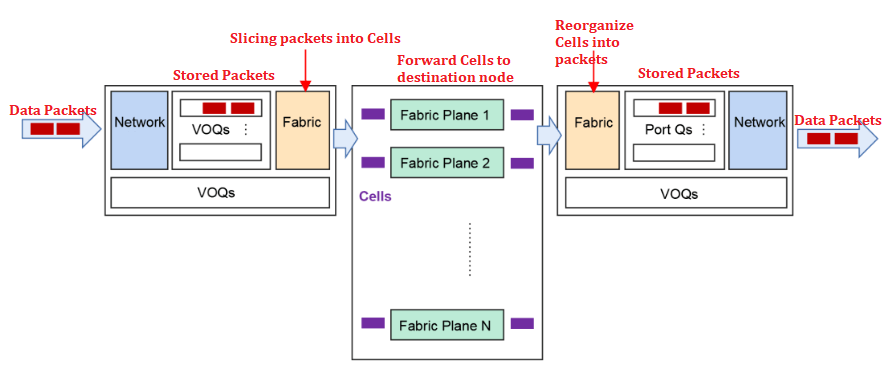
- VOQ+Cell-based forwarding mechanism, effectively combating packet loss
When the network encounters burst traffic, it may cause the receiver to process slowly, resulting in congestion and packet loss. The VOQ+Cell-based forwarding mechanism adopted by DDC can solve this problem well. The specific process is as follows:
The sender will first classify and store the packets into VOQs after receiving them. Before sending the packets, the NCP will first send a Credit message to confirm whether the receiver has enough buffer space. Only when the receiver confirms that it has processing capacity, the packets will be sliced into Cells and dynamically load-balanced to the Fabric nodes. If the receiver is temporarily unable to process, the packets will be temporarily stored in the VOQs of the sender and not directly forwarded. This mechanism makes full use of the cache, which can greatly reduce or even avoid packet loss, thereby improving the overall communication stability, reducing latency, and increasing bandwidth utilization and business throughput efficiency.
- PFC single-hop deployment, completely avoiding deadlock
PFC technology is used for traffic control in RDMA lossless networks, which can create multiple virtual channels for Ethernet links and set priorities for each channel. However, PFC also has deadlock problems.
In the DDC network, since all NCPs and NCFs are regarded as whole devices, there is no multi-level switch, thus completely avoiding the deadlock problem of PFC.
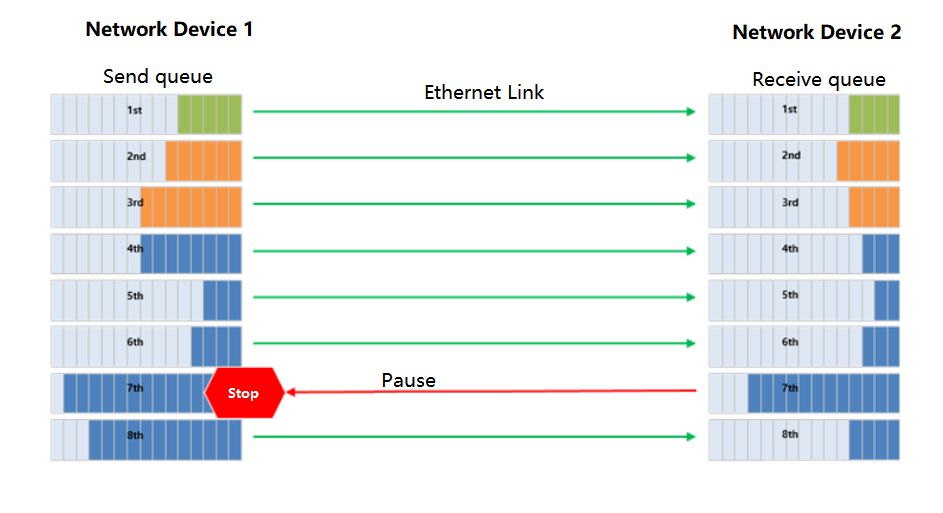
Schematic Diagram of PFC Working Mechanism
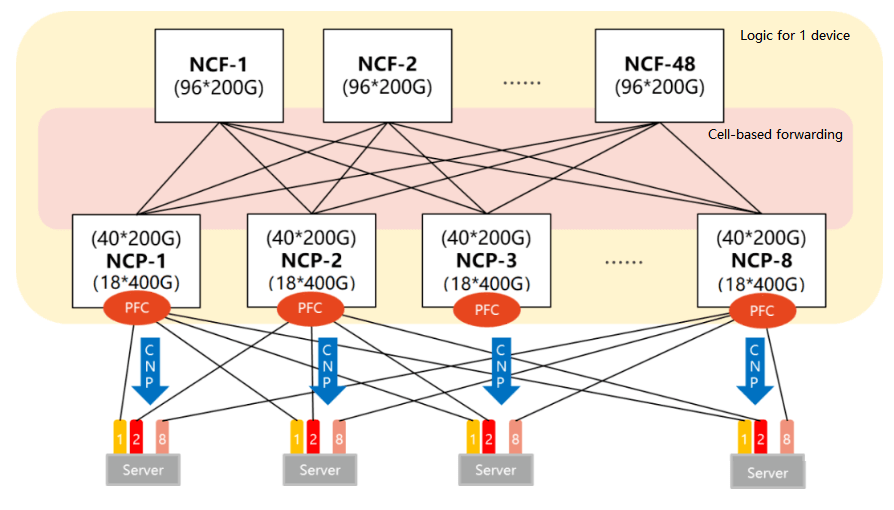
- Distributed OS, enhancing reliability
In the DDC architecture, the management function is centrally controlled by the NCC, but this may pose a single point of failure risk. To avoid this problem, DDC uses a distributed OS, which allows each NCP and NCF to manage independently, and has an independent control plane and management plane. This not only greatly improves the system reliability, but also makes it easier to deploy.
Conclusion: DDC meets the network requirements of large-scale AI model training through its unique technical strategies, and also optimizes in many details, ensuring that the network can run stably and efficiently under various complex conditions.
Related Products:
-
 QSFP-DD-800G-AOC-3M 3m (10ft) 800G QSFP-DD to QSFP-DD Active Optical Cable
$2710.00
QSFP-DD-800G-AOC-3M 3m (10ft) 800G QSFP-DD to QSFP-DD Active Optical Cable
$2710.00
-
QSFP-DD-800G-AOC-10M 10m (33ft) 800G QSFP-DD to QSFP-DD Active Optical Cable
$2750.00
-
QSFP112-400G-AOC-3M 3m (10ft) 400G QSFP112 to QSFP112 Active Optical Cable
$1643.00
-
QSFP112-400G-AOC-10M 10m (33ft) 400G QSFP112 to QSFP112 Active Optical Cable
$1669.00
-
OSFP-800G-SR8 OSFP 8x100G SR8 PAM4 850nm MTP/MPO-16 100m OM4 MMF FEC Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
OSFP-400G-PSM8 400G PSM8 OSFP PAM4 1550nm MTP/MPO-16 300m SMF FEC Optical Transceiver Module
$1000.00
-
NVIDIA MCA7J60-N004 Compatible 4m (13ft) 800G Twin-port OSFP to 2x400G OSFP InfiniBand NDR Breakout Active Copper Cable
$800.00
-
NVIDIA MCA4J80-N004 Compatible 4m (13ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable
$650.00
-
NVIDIA MCA4J80-N003-FTF Compatible 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable, Flat top on one end and Finned top on other
$600.00
-
NVIDIA MFS1S00-H005V Compatible 5m (16ft) 200G InfiniBand HDR QSFP56 to QSFP56 Active Optical Cable
$355.00















