Ethernet Challenges InfiniBand’s Dominance
InfiniBand dominated high-performance networking in the early days of generative AI due to its superior speed and low latency. However, Ethernet has made significant strides, leveraging cost efficiency, scalability, and continuous technological advancements to close the gap with InfiniBand networking. Industry giants like Amazon, Google, Oracle, and Meta have adopted high-performance Ethernet solutions, narrowing the performance divide and, in some cases, surpassing InfiniBand in specific metrics. Even NVIDIA, a long-time InfiniBand leader, has shifted focus to Ethernet-based solutions like Spectrum-X, which now outsells its Quantum InfiniBand products in the Blackwell GPU series. The release of the Ultra Ethernet Consortium‘s (UEC) Release Candidate 1 specification marks a pivotal moment in this evolution, positioning Ethernet as a formidable competitor in AI networking and high-performance computing (HPC).
UEC 1.0 Specification: Redefining Ethernet for AI and InfiniBand Competition
The UEC’s 562-page Release Candidate 1 specification introduces an enhanced Ethernet architecture tailored for large-scale AI networking and HPC clusters.
Unlike standard Ethernet, which struggles to match InfiniBand’s performance without deep customization, UEC optimizes the transport and flow control layers to deliver InfiniBand-level performance with greater flexibility and cost-effectiveness. The UEC project aims to provide transport layer and flow control layer functionalities for Ethernet network interface cards (NICs) and switches, optimizing the operational efficiency of large-scale, high-speed data center networks. The transport layer ensures user data reaches its destination from the source while supporting modern AI and HPC command requirements. Meanwhile, the flow control layer guarantees data transmission at optimal speeds, prevents congestion, and achieves dynamic rerouting during link failures.
Core Components of UEC for Competing with InfiniBand
The UEC, led by the Linux Joint Development Foundation (JDF), aims to achieve 1-20 microsecond round-trip latency, making it ideal for AI training, AI inference, and HPC networking. Its specifications mandate that the network’s physical layer must adhere to Ethernet standards while requiring switches to support modern Ethernet capabilities.
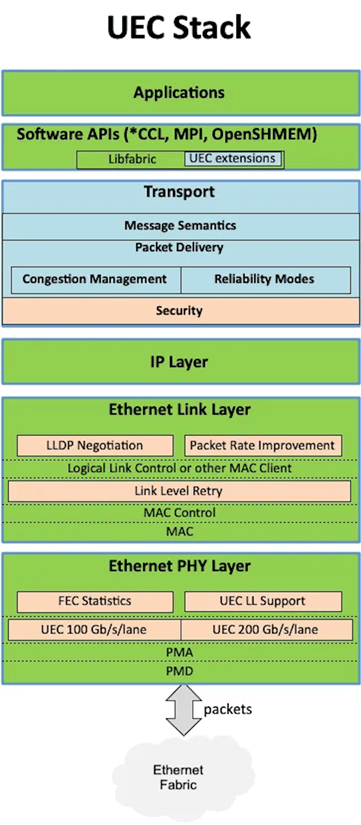
A key technical cornerstone is Open Fabric Interfaces (LibFabric). As a widely adopted API, LibFabric standardizes NIC usage by connecting high-performance networking libraries—such as NVIDIA’s NCCL, AMD’s RCCL, and MPI—via existing bindings or plugins, thereby addressing the communication demands of AI supercomputing clusters. UEC mandates LibFabric support for NICs, including commands for send/receive, RDMA, and atomic operations, accelerating InfiniBand-like performance.
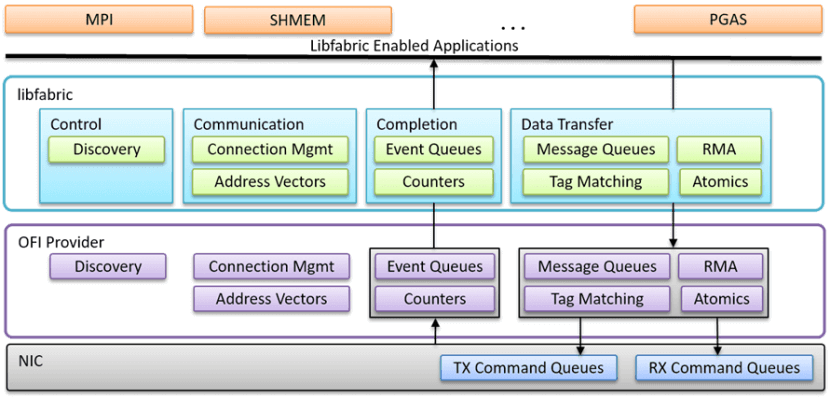
The UEC project is not an entirely new invention; it builds upon established open standards to define an interoperable framework for its operations, with particular emphasis on unconstrained API interactions with CPUs/GPUs. UEC mandates that all NICs must support the LibFabric command set—including send, receive, RDMA, and atomic operations—enabling the translation of LibFabric’s software command stack into hardware-accelerated instruction sets on the NIC.
The concept of a “Job” introduced by LibFabric is further refined in UEC. Each Job represents a collection of collaborative processes across multiple endpoints, isolated via Fabric End Points (FEPs) within the NIC. A single NIC may host multiple FEPs, but each FEP belongs exclusively to one Job and can only communicate with FEPs sharing the same Job ID. Job creation and termination are managed by a trusted Fabric Service, which also supports encrypted domains for secure traffic isolation. UEC additionally provides flexible membership mechanisms for service scenarios requiring dynamic participation.
These Job and FEP concepts form the foundation of UEC network operations and are mandatory components of the LibFabric command implementation.
UEC’s transport layer delivers LibFabric commands and data to FEPs, ideally leveraging Ethernet while supporting optional enhancement layers.
- Open Fabric Interfaces (LibFabric): A standardized API that integrates with high-performance libraries like NVIDIA’s NCCL, AMD’s RCCL, and MPI, enabling seamless communication in AI supercomputing clusters. UEC mandates LibFabric support for NICs, including commands for send/receive, RDMA, and atomic operations, accelerating InfiniBand-like performance.
- Job and Fabric End Point (FEP) Model: UEC introduces a Job concept, where collaborative processes across endpoints are isolated via FEPs within NICs. This ensures secure, scalable communication, rivaling InfiniBand’s proprietary protocols.
- Multi-Rail Architecture: UEC’s “fat network” design uses multiple consistent paths (e.g., 8x100Gbps channels for an 800GbE interface) to maximize bandwidth and redundancy, offering scalability that challenges InfiniBand networks.
Packet Layer Design
Drawing from industry experience with modular switches, UEC fragments LibFabric messages into smaller packets for flexible routing, integrating reliability and flow control directly into the transport layer. Given the ultra-low latency requirements of data centers, hardware acceleration is essential for error recovery and flow control to ensure seamless data streaming.
The packet layer introduces additional headers, enabling NICs and switches to exchange network operational information independently of message flows. While modular switches typically handle such tasks via internal switching layers, UEC NICs generate packets with enhanced flow control capabilities transmitted over augmented Ethernet.
Multi-Rail Architecture
UEC is designed for “fat networks” featuring multiple physically equidistant, equal-speed paths—commonly implemented as “multi-rail” configurations. For example, an 800GbE NIC interface may comprise eight 100Gbps lanes, each connected to a separate switch. With each switch supporting 512×100Gbps ports, the system can accommodate up to 512 FEPs.
UEC NICs employ an “entropy” mechanism to assign packets across lanes via hashing for load balancing. The sender selects entropy values to distribute packets evenly, maximizing aggregate bandwidth. CPU/GPU applications remain oblivious to this complexity, simply queuing sends via LibFabric while the NIC handles distribution automatically.
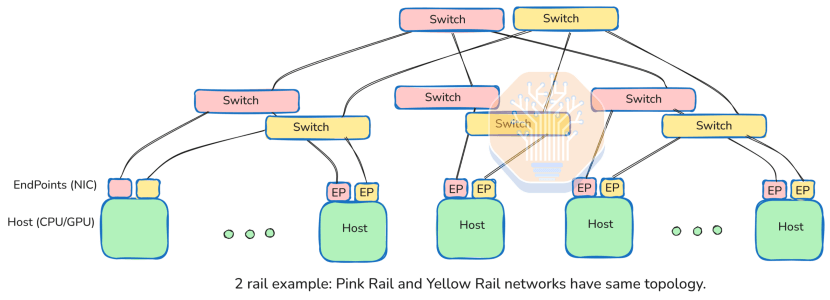
This multi-rail architecture enables parallel operation of multiple 512-port switches with identical topologies, achieving higher aggregate throughput. UEC’s breakthrough lies in coordinating these endpoints within a single NIC, presenting hosts with a high-bandwidth connection while transparently distributing traffic across paths.
Beyond enhancing cluster scalability and simplifying network deployment, multiple paths empower UEC NICs to deliver:
- Ultra-fast packet loss recovery
- Microsecond-scale flow control
- Stable throughput despite suboptimal application scheduling or occasional link fluctuations
UEC-CC: Advanced Congestion Control to Rival InfiniBand
UEC’s Congestion Control (UEC-CC) is a game-changer for AI network performance. With sub-500-nanosecond precision, UEC-CC measures forward and reverse path delays independently, requiring absolute time synchronization between NICs. Unlike InfiniBand, which relies on proprietary mechanisms, UEC-CC uses Explicit Congestion Notification (ECN) and supports packet trimming to minimize packet loss. By eliminating outdated protocols like RoCE, DCQCN, and Priority Flow Control (PFC), UEC-CC ensures smoother data flows, making Ethernet a strong contender in low-latency networking.
Through bidirectional measurement, UEC-CC can accurately determine whether congestion originates at the sender or the receiver. When UEC-CC is enabled, switches must support Explicit Congestion Notification (ECN), and modern ECN variants are recommended: specifically, setting congestion flags per traffic class and performing measurements immediately before packet transmission. This approach provides the most current congestion information and enables differentiated handling per traffic class.
In cases of extreme congestion, UEC-CC also supports packet trimming, retaining only tombstone header information to explicitly notify the receiver of packet loss. Compared to outright packet dropping, this mechanism triggers error correction responses faster.
Given that data center Round-Trip Times (RTT) are only a few microseconds, the sender can transmit data for only an extremely short duration without waiting for acknowledgments. Therefore, the receiving FEP (Front-End Processor, likely referring to the NIC/receiver logic) is responsible for controlling the transmission pace.
The receiver gathers rich multi-lane, multi-traffic-class flow state information via ECN flags. Based on this, it determines how many new packet credits to grant and notifies the sender via ACKs and special Credit CP (Control Packet) commands. This allows the sender to be paused at the microsecond level, effectively preventing packet loss.
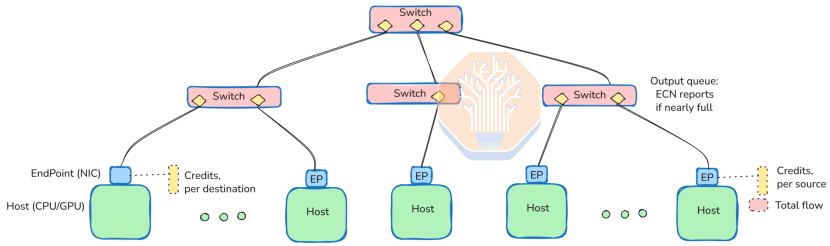
Furthermore, UEC-CC supports dynamic adjustment of “entropy capacity” to rebalance routing paths, thereby optimizing message spraying strategies. It standardizes the reporting mechanism for partial error correction rates and packet loss rates, enabling the system to detect weak links and route around them. By using entropy-based hash routing at each hop, even with entropy levels an order of magnitude greater than the number of lanes, weak links can be isolated, minimizing their impact on overall path capacity.
UEC-CC deprecates several legacy flow control mechanisms:
- RoCE and DCQCN: Deprecated because their inability to dynamically update flow control strategies based on the actual location of flow issues degrades UEC-CC performance.
- PFC (Priority-based Flow Control): Unnecessary between switches and can even block legitimate traffic, hence it should be disabled. It is also no longer recommended for NIC-to-switch connections due to its lack of precision compared to UEC-CC.
- Credit-Based Flow Control: Similarly deprecated because it conflicts with the UEC-CC mechanism.
Transport Security for Secure AI Networking
UEC’s Transport Security Sublayer adopts post-quantum cryptography (DES) and dynamic key derivation to secure AI cluster communication. This robust security framework supports flexible encryption domains, ensuring safe data exchange even in dynamic environments, offering a level of security comparable to InfiniBand networks.
The Transport Security Sublayer is a highly specialized and rigorously structured security mechanism. It draws upon many established security practices while incorporating adaptive improvements.
UEC recommends using a post-quantum cryptographic algorithm, DES (Data Encryption Standard), as the encryption method, and emphasizes defensive operations, including rules for rotating nonce values. The encryption domain can be a subset of FEPs within a Job, and it also supports adaptive domain configuration for dynamic service scenarios where clients frequently join or leave.
The mechanism employs an ingenious key derivation scheme. This allows the use of a single master key across the entire domain, while using different keys and nonces for each communication flow, requiring only minimal table space (even for Jobs containing tens of thousands of endpoints).
To ensure security, the data center must incorporate trusted components:
- A Security Domain Manager entity responsible for creating and maintaining the encryption domain.
- NICs are equipped with trusted hardware modules to manage their port access within the domain.
Although verifying the versions of these components falls outside the scope of the UEC specification, open standards exist for vendor reference implementations.
Other Layers
Layer 4: Network Layer (UE Network Layer): Primarily discusses the packet trimming mechanism, an optional congestion control measure used to reduce data payload during network overload.
Layer 5: Link Layer (UE Link Layer): Aims to enhance overall performance through link-level packet replacement and inter-switch flow control mechanisms. However, given that UEC-CC already provides highly efficient flow control, this design appears largely redundant in environments with microsecond-level round-trip delays. Especially considering that CBFC (Credit-Based Flow Control) has been deprecated in the UEC-CC section, this functionality doesn’t seem to offer significant benefits. It is optional, is not expected to be widely deployed in the future, but may add complexity to interoperability testing.
Layer 6: Physical Layer (UE Physical Layer): Recommends using multiple 100Gb Ethernet lanes, adhering to IEEE 802.3/db/ck/df standards. The document briefly notes that referencing 200Gb standards is currently impossible as they are not yet officially published. In contrast, the UALink specification explicitly supports 200Gb, indicating an industry trend moving in this direction. UEC should also consider starting from this point in the future, rather than passively following later.
UEC vs. UALink and SUE: A Competitive Landscape for InfiniBand Alternatives
While UEC targets scalable Scale-Out networks for thousands of endpoints, competitors like UALink and Broadcom’s Scale Up Ethernet (SUE) focus on Scale-Up networks similar to NVIDIA’s NVLink.
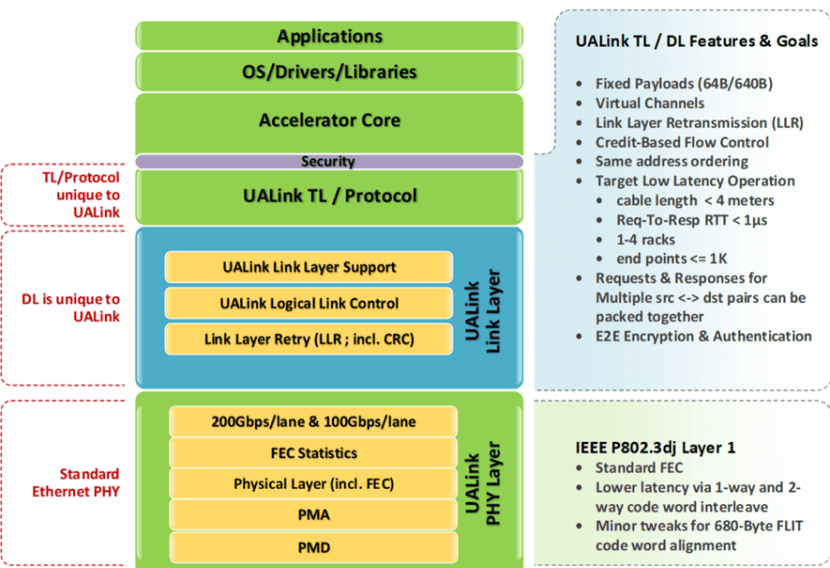
UALink supports up to 1024 endpoints with 200GbE links, while SUE emphasizes single-rail networks. Both incorporate memory-mapped interfaces for efficient data transfer, but UEC’s comprehensive approach, including multi-layer switching and advanced congestion control, positions it as a stronger rival to InfiniBand for large-scale AI and HPC clusters.
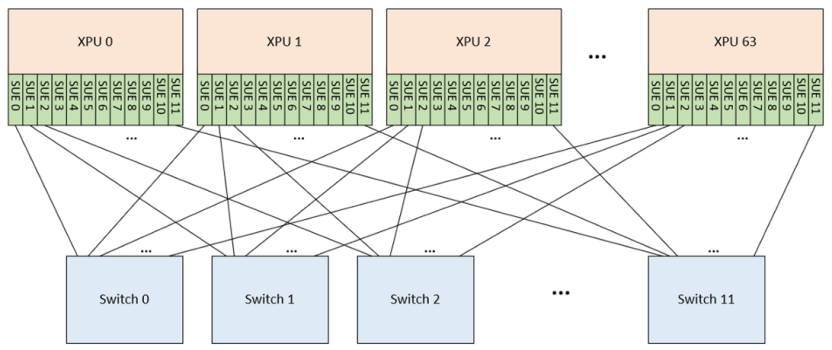
Both SUE and UALink explicitly mention 200GbE links in their specifications, making UEC appear slightly lagging behind in terms of speed.
Similar to UEC, UALink sprays traffic across rails, but it provides a detailed definition for its credit-based flow control mechanism. In contrast, SUE delegates this aspect to Ethernet implementation and suggests relying on client software coordination. This results in a cleaner specification design for SUE, though the practical difference is minimal. UALink also bundles multiple lanes together (e.g., 4×200G) to boost transmission efficiency, whereas SUE and UEC consider a single 200G lane sufficiently fast. Therefore, UALink introduces extra complexity here for limited gain.
SUE recommends using PFC or, preferably, Credit-Based Flow Control (CBFC) for flow control. In single-tier switch environments, this approach is viable, as PFC works well in such scenarios, and CBFC offers smoother operation.
UALink provides encryption mechanisms for connections, while SUE takes a more streamlined approach, simply declaring that reliability, data integrity, and encryption should be provided by the Ethernet layer.
Furthermore, SUE delegates the tasks of message spraying and cross-rail load balancing to the software layer within the endpoint nodes. This is a distinct advantage for companies skilled in developing such software.
Both UALink and SUE provide a memory-mapped interface. While neither specifies the exact implementation of memory mapping, both expect message sending and receiving to be accomplished by reading from and writing to virtual memory addresses corresponding to remote endpoints. This approach can theoretically achieve efficiency comparable to NVLink. However, since they don’t reuse NVLink’s packet format, new plugins or low-level code still need to be developed.
“Memory mapping” is often referred to as “memory semantics.” It utilizes a large virtual address space, assigning unique address ranges to each host. This allows host processors to perform memory operations directly using read/write instructions. However, this mechanism does not include advanced semantics like sequential consistency or cache coherence. That is, there is no cache snooping or intelligent cache updates between nodes in the cluster.
For all these systems, including UEC, the demands for high speed and low latency in data centers are driving endpoints to be pulled closer to the host chip, rather than remaining as “obsolete” IO bus devices located remotely from the host. The trend today is more akin to treating endpoints (like NICs) as another core within a multi-core system. This simplifies the process of sending commands from compute cores (like streaming GPUs or traditional CPUs) and allows endpoints to access host memory more efficiently.
It is anticipated that SUE and UALink will increasingly be integrated as IP blocks within host chips rather than existing as standalone chips. NVLink was designed this way from the start, and chips like Intel Gaudi 3 or Microsoft Maia 100 employ similar approaches over Ethernet links. While this simplifies IP block design, it also requires them to remain sufficiently compact to minimize the real estate they occupy on the host chip.
In contrast, UEC’s complexity is more likely to reside in discrete NICs. However, there is good reason to expect it will gradually be integrated into host chip fabrics in the future, potentially even in chiplet form.
Key Advantages of UEC Over InfiniBand
Hardware-Accelerated LibFabric: Enhances compatibility with existing high-performance libraries.
- Scalable Job Model: Combines modern encryption and flexible endpoint management.
- Advanced Congestion Control: UEC-CC outperforms traditional protocols like RoCE and DCQCN.
- Open Standards: Supports CCL, MPI, SHMEM, and UD plugins for broad ecosystem compatibility.
- Cost and Scalability: Ethernet’s affordability and flexibility make it a viable InfiniBand alternative.
Challenges and Considerations for UEC Adoption
While UEC offers significant advantages, challenges remain. Interoperability across vendors requires rigorous testing to ensure consistent performance, especially when non-UEC-compliant devices are involved. Amazon’s EFA, while LibFabric-based, highlights potential plugin compatibility issues with NVIDIA’s ecosystem. Ensuring ECN support in intermediate devices is critical to maintaining InfiniBand-level performance.
The Future of AI Networking: Can UEC Redefine the Rules?
As AI models grow, network performance becomes a critical bottleneck. UEC’s open-standard approach challenges InfiniBand’s dominance by combining LibFabric, multi-rail architecture, and advanced congestion control. Its scalability, security, and cost-effectiveness make it a compelling choice for future AI data center networks. While InfiniBand remains a strong player, UEC’s innovations could reshape the landscape, driving the industry toward open, standardized AI networking solutions.
The UEC 1.0 specification marks a turning point in the battle between Ethernet and InfiniBand. By addressing performance gaps with hardware acceleration, advanced flow control, and robust security, UEC positions Ethernet as a scalable, cost-effective alternative for AI and HPC networking. As data centers evolve, UEC’s open standards and flexibility could redefine the rules, challenging InfiniBand’s monopoly and paving the way for next-generation AI infrastructure.
Related Products:
-
 NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA(Mellanox) MMA1T00-HS Compatible 200G Infiniband HDR QSFP56 SR4 850nm 100m MPO-12 APC OM3/OM4 FEC PAM4 Optical Transceiver Module
$139.00
-
NVIDIA(Mellanox) MMS1W50-HM Compatible 200G InfiniBand HDR QSFP56 FR4 PAM4 CWDM4 2km LC SMF FEC Optical Transceiver Module
$650.00
-
NVIDIA(Mellanox) MMA1B00-E100 Compatible 100G InfiniBand EDR QSFP28 SR4 850nm 100m MTP/MPO MMF DDM Transceiver Module
$40.00
-
OSFP-800G-PC50CM 0.5m (1.6ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Passive Direct Attach Copper Cable
$105.00
-
OSFP-800G-AC3M 3m (10ft) 800G Twin-port 2x400G OSFP to 2x400G OSFP InfiniBand NDR Active Copper Cable
$600.00