
Overview
We have previously briefly introduced NVIDIA’s latest Blackwell GPU, but some of the content may be easily misunderstood, such as the ambiguity or vague concepts in NVIDIA’s official introduction. Additionally, we have seen some misunderstandings about the capabilities of the new generation of GPUs, such as the belief that they have dozens of times the performance improvement. Therefore, we have decided to comprehensively summarize the various data to allow everyone to make a more comprehensive and fairer comparison.
In this article, we have comprehensively collected hardware information on NVIDIA’s Blackwell GPUs, including B100, B200, GH200, and NVL72, as well as the SuperPod-576, and the corresponding ConnectX-800G network cards, Quantum-X800 IB switches, and Spectrum-X800 Ethernet switches, and further compared them with the previous series. It should be noted that some of the content in the article is data that we have inferred based on various information, such as the red parts in some of the tables, and the final data will be subject to the official white paper (which has not yet been seen). In addition, this does not include content related to the software ecosystem.
Evolution
NVIDIA released the latest Blackwell architecture GPUs on March 19, 2024, the main ones being the B200, B100, and GB200 GPUs, as well as the corresponding GB200-NVL72 and GB200-SuperPod. The relationship between the various GPUs is shown in the figure below.
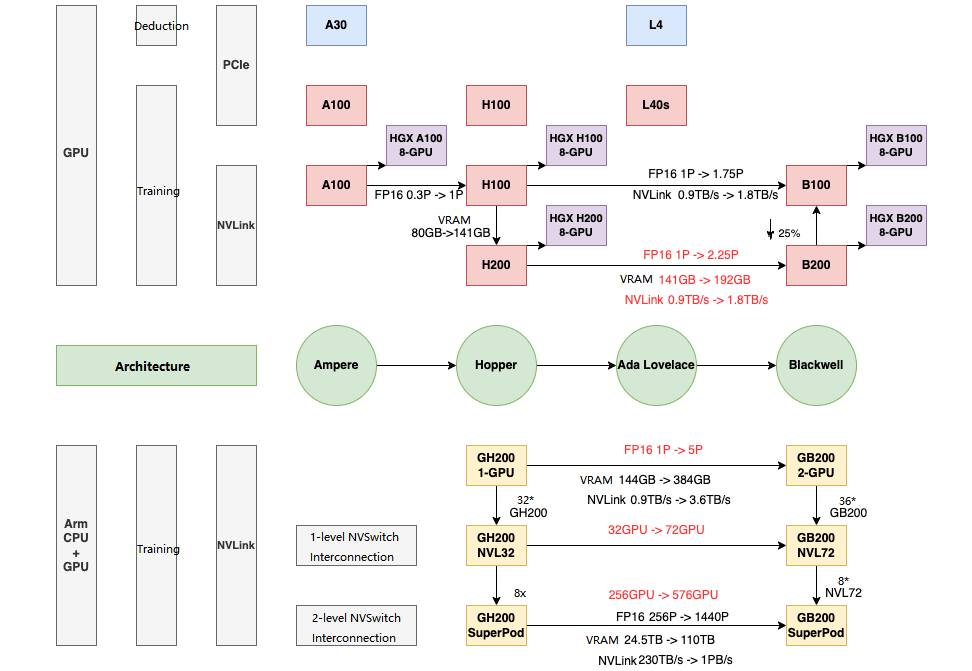
Single GPU
The table below shows the most powerful GPUs in the Ampere, Hopper, and the latest Blackwell series. It can be seen that the memory, computing power, and NVLink are all gradually being strengthened. (Note: NVIDIA has also released a special solution where two H100 PCIe versions are connected through NVBridge, called H100 NVL, but since they are still two GPUs, the details will not be discussed here.)
A100 -> H100: FP16 dense computing power increased by more than 3 times, while power consumption only increased from 400W to 700W.
H200 -> B200: FP16 dense computing power increased by more than 2 times, while power consumption only increased from 700W to 1000W.
B200 FP16 dense computing power is about 7 times that of A100, while the power consumption is only 2.5 times.
Blackwell GPUs support FP4 precision, with computing power twice that of FP8. Some of the data in NVIDIA’s reports compare FP4 computing power with Hopper architecture FP8 computing power, so the acceleration ratio will be more exaggerated.
It should be noted that:
GB200 uses the full B200 chip, while B100 and B200 are the corresponding stripped-down versions.
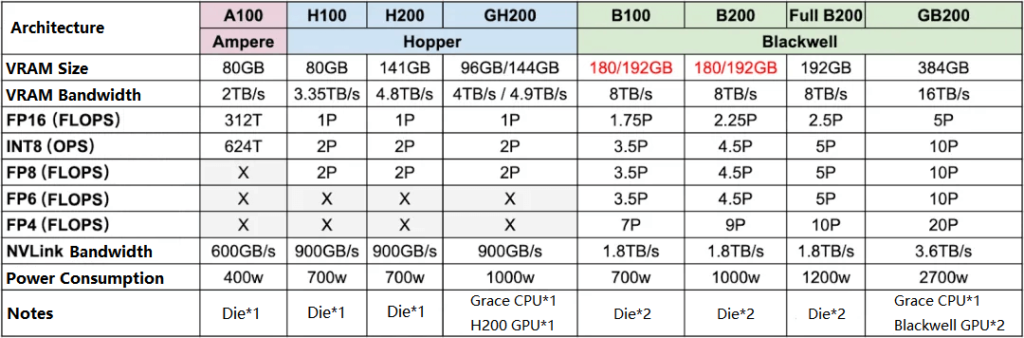
HGX Servers
HGX is a high-performance server from NVIDIA, usually containing 8 or 4 GPUs, typically paired with Intel or AMD CPUs, and using NVLink and NVSwitch to achieve full interconnection (8 GPUs are usually the upper limit of NVLink full interconnection, except for NVL and SuperPod).
From HGX A100 -> HGX H100 and HGX H200, the FP16 dense computing power increased by 3.3 times, while the power consumption is less than 2 times.
From HGX H100 and HGX H200 -> HGX B100 and HGX B200, the FP16 dense computing power increased by about 2 times, while the power consumption is similar, at most not more than 50%.
It should be noted that:
The network of HGX B100 and HGX B200 has not been upgraded, and the IB network card is still 8x400Gb/s.
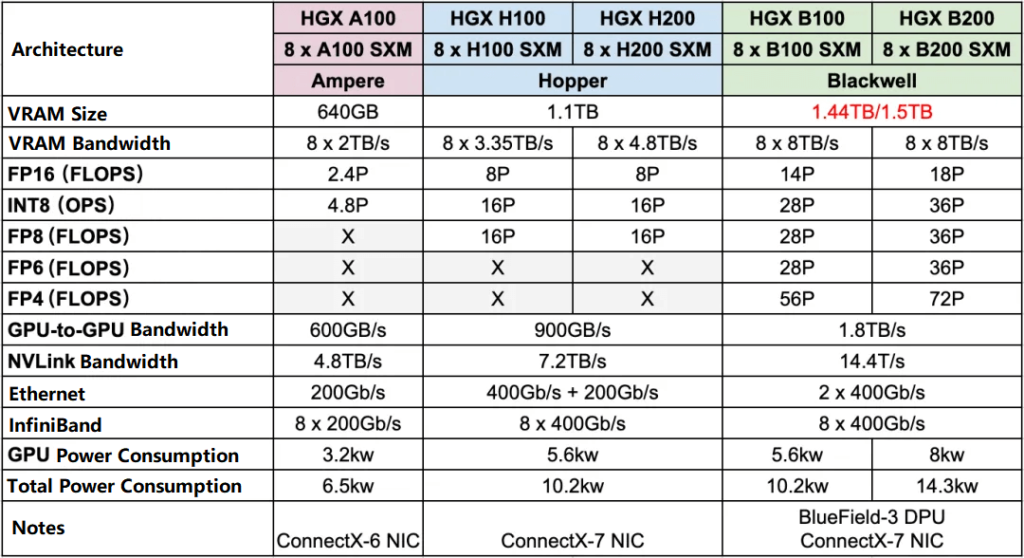
NVL & SuperPod
In addition to the HGX series GPU servers, NVIDIA also has solutions for full cabinets and clusters, all using the latest Grace CPU + GPU solution, and corresponding to liquid cooling systems. The table below shows the corresponding NVL cabinets and SuperPod for the Hopper architecture and Blackwell architecture.
NVL32 -> NVL72: The number of GPUs increased from 32 to 72, and the FP16 dense computing power increased from 32P to 180P, nearly 6 times, while the power consumption also increased from 40kW (no specific number seen, estimated data) to 120kW, nearly 3 times.
GH200 SuperPod -> GB200 SuperPod: The number of GPUs increased from 256 to 576, and the FP16 dense computing power increased from 256P to 1440P, nearly 6 times, and the corresponding power consumption has not been found.
The latest ConnectX-8 IB network cards with 800Gb/s bandwidth are used in NVL72 and GB200 SuperPod, while HGX B100 and HGX B200 still use ConnectX-7 IB network cards with 400Gb/s bandwidth.
It should be noted that:
NVIDIA introduced that the GB200 SuperPod is composed of 8 NVL72, while the GH200 SuperPod is not composed of 8 NVL32.
The number of L1 NVSwitch Trays and L2 NVSwitch Trays in the GB200 SuperPod has not been seen and is estimated data.
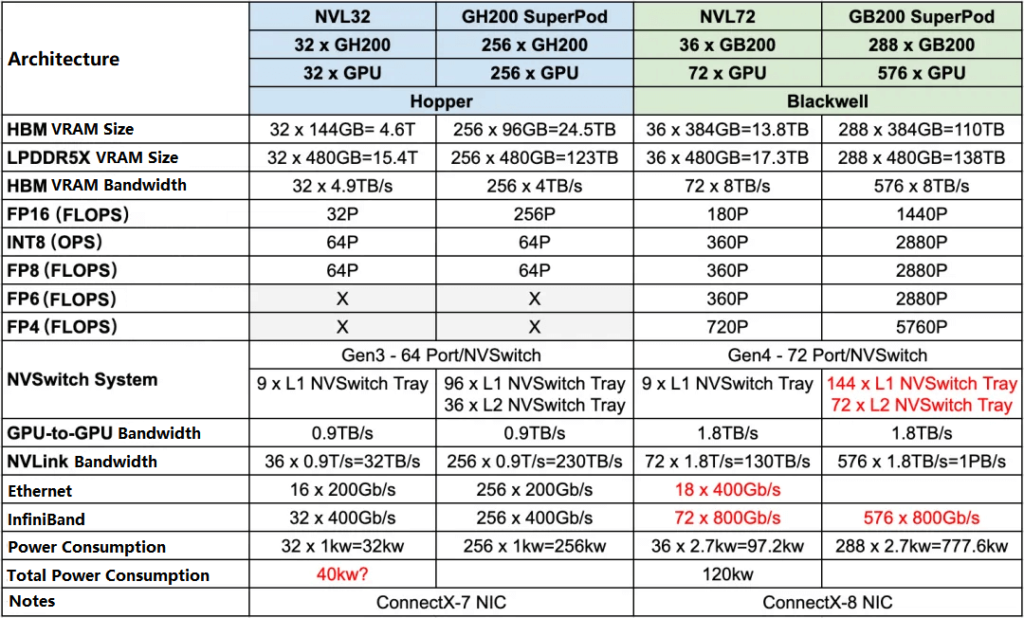
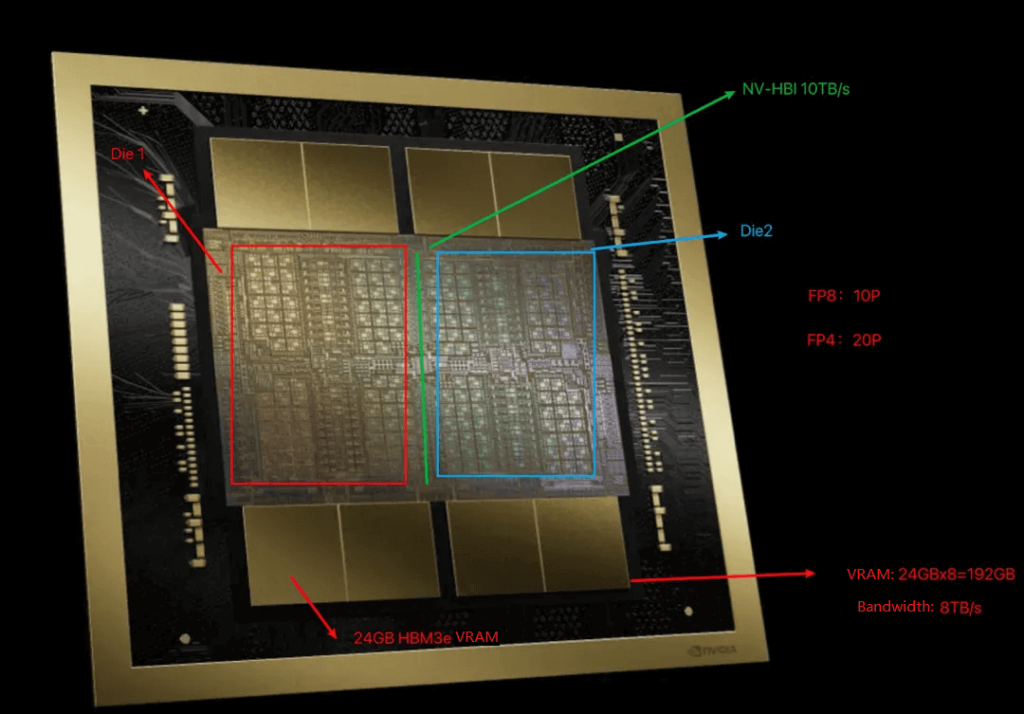
Blackwell GPU
The Blackwell GPU and the H100 GPU both use TSMC’s 4N process technology. The H100 contains 80 billion transistors, while the Blackwell GPU contains 208 billion transistors. However, the H100 is a single-die (single complete semiconductor unit) package, while the Blackwell GPU is a multi-die package with 2 dies.
Each Blackwell GPU die has about 1.25 times the compute power of the H100, and the two dies together have around 2.5 times the compute power of the H100. This can also be seen from the number of transistors.
The communication bandwidth between the two dies is 10TB/s.
The memory uses HBM3e, with each chip being 24GB in size and a theoretical bandwidth limit of 1.2TB/s, with an actual bandwidth of 1TB/s. The entire Blackwell GPU has 8 of these memory chips.
In summary, the key specifications of a complete Blackwell GPU are:
Sparse compute power (dense compute power * 2):
FP16: 5P FLOPS (2 * 2.5P)
FP8/FP6/INT8: 10P FLOPS (2 * 5P)
FP4: 20P FLOPS (2 * 10P)
Memory:
Size: 192GB (8 * 24GB)
Bandwidth: 8TB/s (8 * 1TB/s)
GH200 & GB200
GH200
The GH200 is NVIDIA’s combination of the H200 GPU released last year and the Grace CPU. Each Grace CPU is paired with one H200 GPU, and the H200 GPU can have up to 96GB or 144GB of memory. The Grace CPU and Hopper GPU are interconnected via NVLink-C2C with a bandwidth of 900GB/s. In addition to the HBM3e, the Grace CPU also has 480GB of external LPDDR5X memory, though the corresponding bandwidth is lower at 500GB/s.
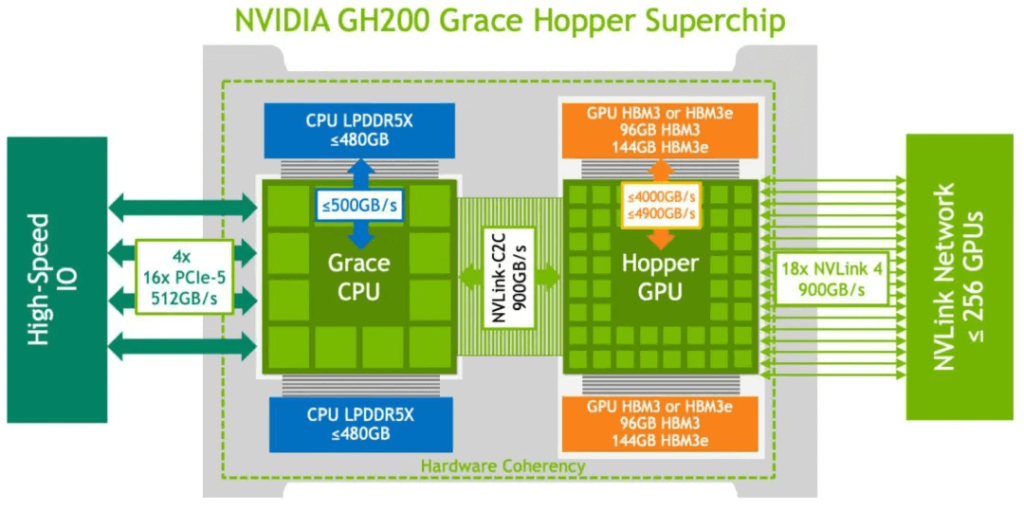
GB200
Unlike the GH200, each GB200 consists of 1 Grace CPU and 2 Blackwell GPUs, doubling the GPU compute power and memory. The CPU and GPUs are still interconnected at 900GB/s via NVLink-C2C. The corresponding power consumption is 1200W.
The GB200 includes 384GB of HBM3e memory and the same 480GB of LPDDR5X, for a total of 864GB of fast memory.


HGX H100/H200 and HGX B100/B200
HGX H100 and HGX H200
As shown, the H200 has the same compute power as the H100, but with larger memory. The maximum memory for 8 GPUs increases from 640GB to 1.1TB. The sparse FP16 compute power for 8 GPUs is 16P, and the sparse FP8 is 32P. The GPU-to-GPU communication bandwidth is 900GB/s for both.
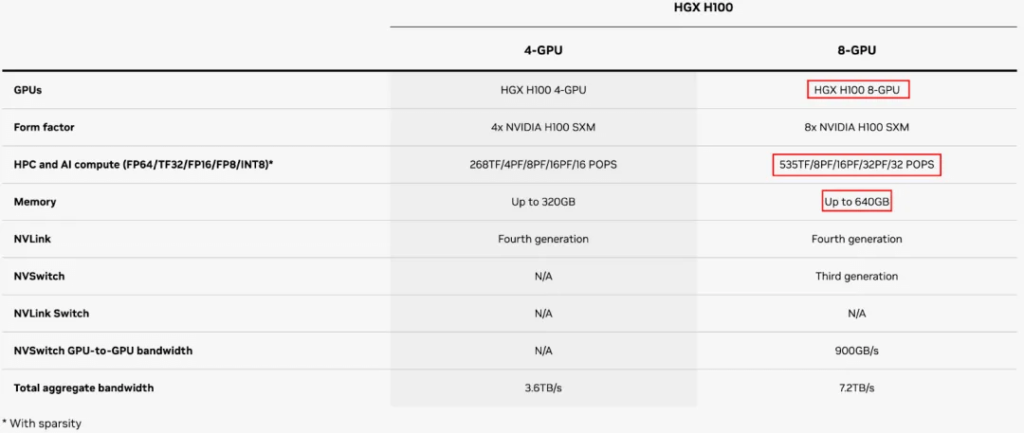
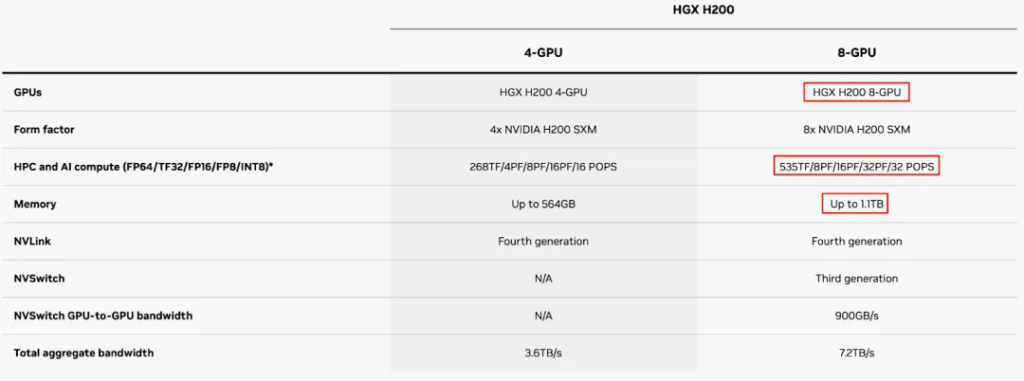
HGX B100 and HGX B200
The B100 and B200 correspond to the previous H100 and H200 respectively, but without the Grace CPU, so they can be used with Intel or AMD CPUs.
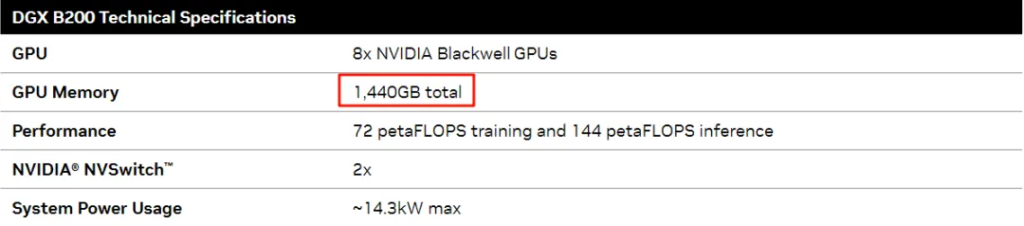
The memory of the B100 and B200 is larger than the H100 and H200. The maximum memory for 8 GPUs is 1.5TB (Note: NVIDIA’s website initially showed 1.4TB, which does not match 192GB*8, and was later corrected to 1.5TB, while the DGX B200 datasheet clearly states 1440GB, or 180GB per GPU).
The compute power of the B100 is about 3/4 of the B200. The sparse FP16 compute power for 8xB100 is 28P, and for 8xB200 is 36P, so 8xB200 is 2.25 times that of 8xH100/H200. This means the sparse FP16 compute power of a single B200 is 4.5P. It should be noted that the actual compute power of the B200 is 90% of the full B200 (in the GB200).


The image shows the DGX B200 datasheet data.
Blackwell’s Tensor Cores have added support for FP6 and FP4, and the FP4 compute power is 2 times the FP8 power, and 4 times the FP16 power. Blackwell’s CUDA Cores no longer support INT8, and starting from Hopper, they also no longer support INT4.

Blackwell’s Tensor Cores have added support for the Microscaling data format, which may be how they support FP8, FP6, FP4, and INT8.

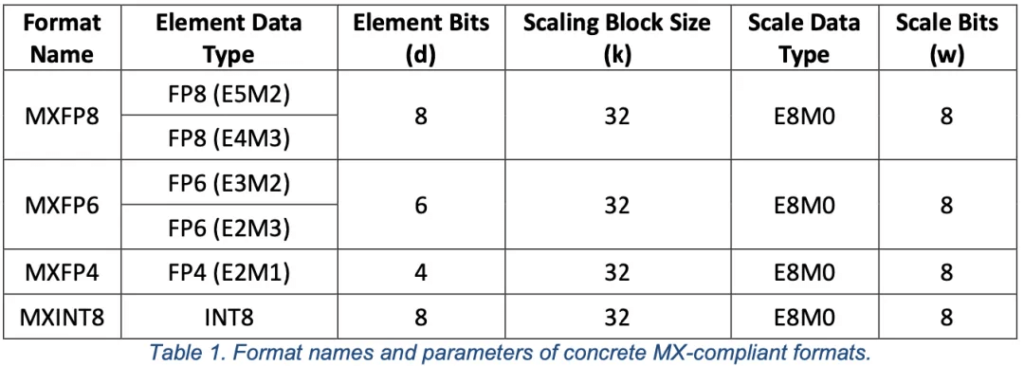
NVLink and NVSwitch
Third-Generation NVSwitch
The third-generation NVSwitch has 64 NVLink Ports, each with 2 lanes. The bandwidth limit is 64*50GB/s=3.2TB/s.
Fourth-Generation NVSwitch
The NVSwitch chip has 72 NVLink Ports, each with 2 lanes, with a bidirectional bandwidth of 2 x 2 x 200 Gb/s = 100GB/s, for a total of 7.2TB/s. The 1.8TB/s NVLinks in the image correspond to 18 Ports.

The B100 and B200 use the fifth-generation NVLink and fourth-generation NVSwitch. Each GPU on the B100 and B200 still has 18 NVLinks, but the bandwidth per link has been upgraded from 50GB/s on the fourth-generation NVLink (H100) to 100GB/s. So the maximum GPU-to-GPU bandwidth for the B100 and B200 is 1.8TB/s.

The fourth-generation NVSwitch also doubles the GPU-to-GPU bandwidth to 1.8TB/s. It can support up to 576 GPUs, for a total bandwidth limit of 576*1.8TB/s=1PB/s.

Network Cards and Network Switches
ConnectX-8 InfiniBand Network Card
NVIDIA has also released a new generation of InfiniBand network cards, the ConnectX-8 (ConnectX-800G), with a corresponding communication bandwidth of 800Gb/s. The previous H100 and H200 used the ConnectX-7 network card, with a communication bandwidth of 400Gb/s, while the A100 used the ConnectX-6 network card with a bandwidth of 200Gb/s.

However, NVIDIA did not use the new ConnectX-800G network card in the HGX B100/B200, and instead continued to use the previous generation ConnectX-7, as shown in the images (NVIDIA Launches Blackwell-Powered DGX SuperPOD for Generative AI Supercomputing at Trillion-Parameter Scale and NVIDIA Blackwell Platform Arrives to Power a New Era of Computing).


BlueField-3 DPU/SuperNIC
BlueField-3 supports Ethernet and IB connections at speeds up to 400Gb/s and can be combined with network and storage hardware accelerators, programmed using NVIDIA DOCA. With BlueField-3, there are corresponding BlueField-3 DPU and BlueField-3 SuperNIC. The BlueField-3 SuperNIC can provide Ethernet remote direct memory access (RoCE) between GPU servers at speeds up to 400Gb/s, supporting single-port 400Gb/s or dual-port 200Gb/s. The previous generation BlueField-2 SuperNIC only supported single-port 200Gb/s or dual-port 100Gb/s.


Quantum-X800 IB Switch
The Quantum-X800 is the new generation of NVIDIA Quantum IB switch, capable of achieving 800Gb/s end-to-end connections with ultra-low latency, primarily supporting the NVIDIA ConnectX-8 network card. The corresponding Quantum-X800 Q3400-RA switch (4U) can provide 144 800Gb/s ports, as shown in the image, using air cooling but also supporting liquid cooling.

Spectrum-X800 Ethernet Switch
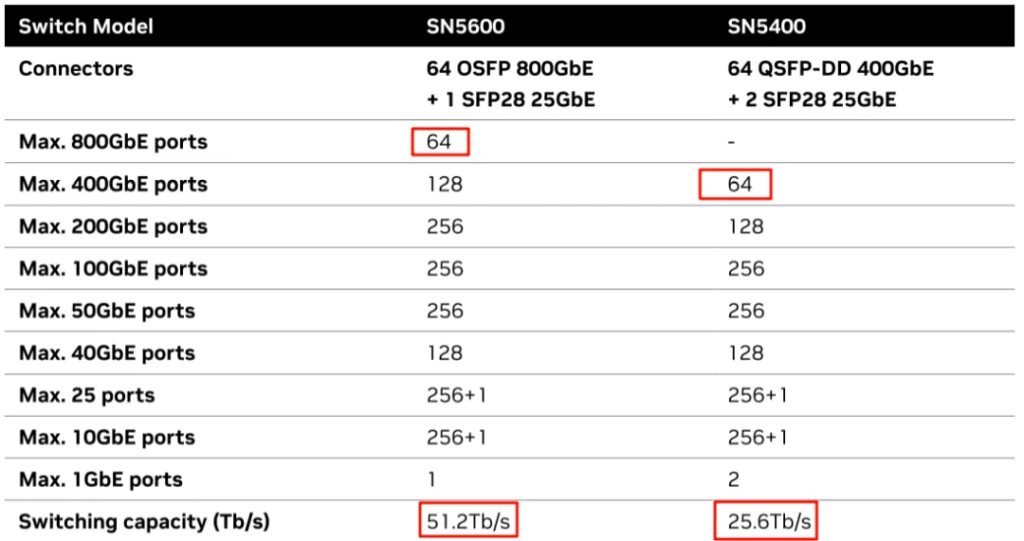
The Spectrum-X800 is the new generation of NVIDIA Spectrum Ethernet switch, including two types: SN5600 and SN5400, both using a 2U design.

As shown in the table, the SN5600 can support up to 800Gb/s per port, with 64 ports and a total bandwidth of 51.2Tb/s, while the SN5400 can support up to 400Gb/s per port, with 64 ports and a total bandwidth of 25.6Tb/s.
GH200 NVL32 & GH200-SuperPod
GH200 Compute Tray
The GH200 Compute Tray is based on the NVIDIA MGX design (1U size), with 2 GH200 units per Compute Tray, i.e., 2 Grace CPUs and 2 H200 GPUs.
NVSwitch Tray
The first-generation NVSwitch Tray contains 2 third-generation NVSwitch chips, with a total of 128 NVLink Ports and a maximum communication bandwidth of 6.4TB/s.
GH200 NVL32
Each cabinet contains 16 GH200 Compute Trays and 9 NVSwitch Trays, resulting in a total of 32 GH200 GPUs and 18 NVSwitches. The 32 GH200 GPUs have 32×18=576 NVLinks, and theoretically, only 576/64=9 NVSwitches would be needed to achieve full interconnection, but this design includes 18 NVSwitches.
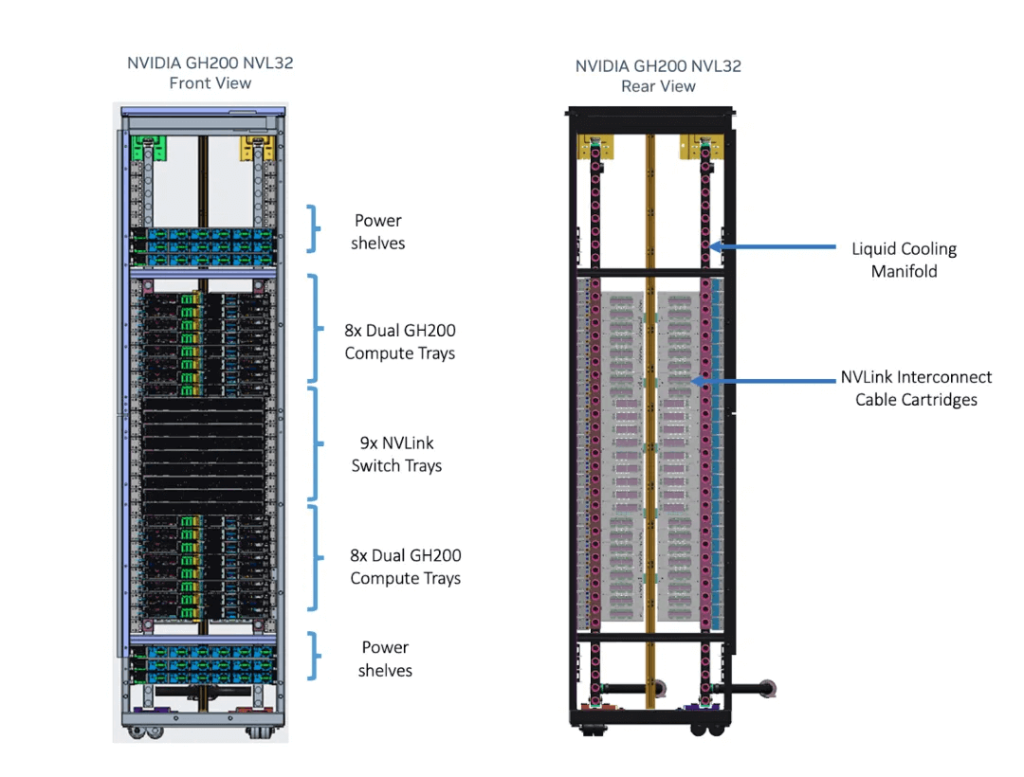
GH200 SuperPod
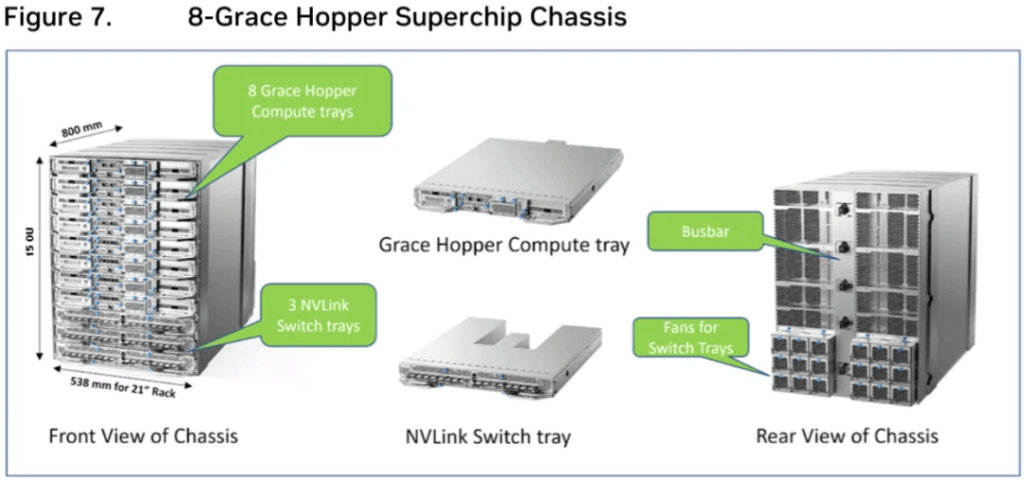
The GH200 SuperPod is composed of 256 GH200 GPUs in a fully interconnected configuration, but it is not made up of 8 NVL32 units. Instead, it is composed of 32 8-Grace Hopper Superchips.
As shown in Figure 7, each 8-Grace Hopper Superchip includes:
8*Hopper Compute Trays (8U), each containing:
1*GH200 GPU
1*ConnectX-7 IB network card, 400Gb/s
1*200Gb/s Ethernet card
3*NVSwitch Trays (3U), with a total of 6*NVSwitches
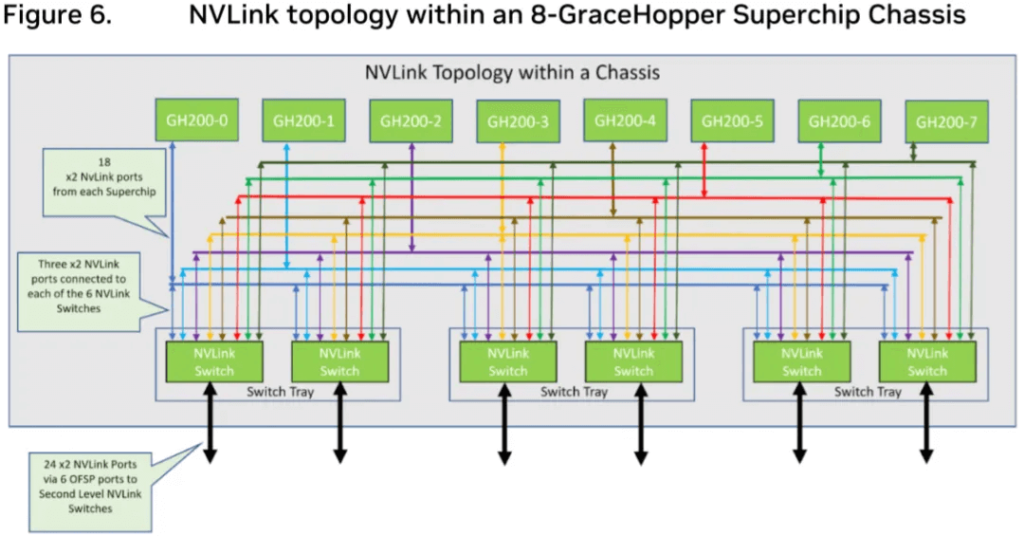
The NVLink connections are as shown in Figure 6, with each GH200 and each NVSwitch having 3 NVLink connections. This uses 24 ports per NVSwitch in this direction. Additionally, each NVSwitch has 24 ports connected to the L2 NVSwitch, for a total of 48 used ports per NVSwitch. (Note: Some of the NVSwitch ports are redundant, and theoretically only 4.5 NVSwitches would be needed, so 3 NVSwitch Trays were chosen.)
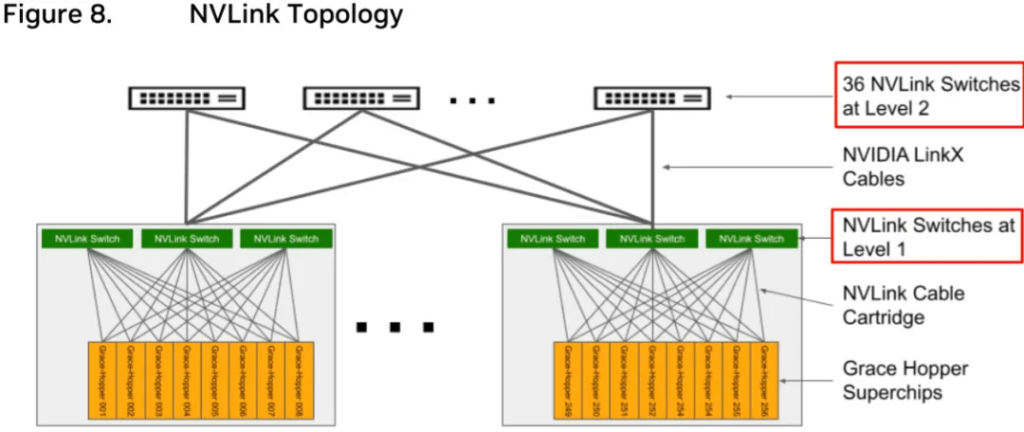
As shown in Figure 8, the GH200 SuperPod is composed of 32 8-Grace Hopper Superchips. The L1 level contains 32 x 3 = 96 NVSwitch Trays (192 NVSwitches), and the L2 level contains 36 NVSwitch Trays (64 NVSwitches). Each L1 NVSwitch Tray has 24 x 2 = 48 ports connected to the L2 NVSwitch Trays, so 36 L2 NVSwitch Trays are needed.
As shown in Figure 12, the 256 GH200 GPUs are also interconnected through a two-tier IB switch.
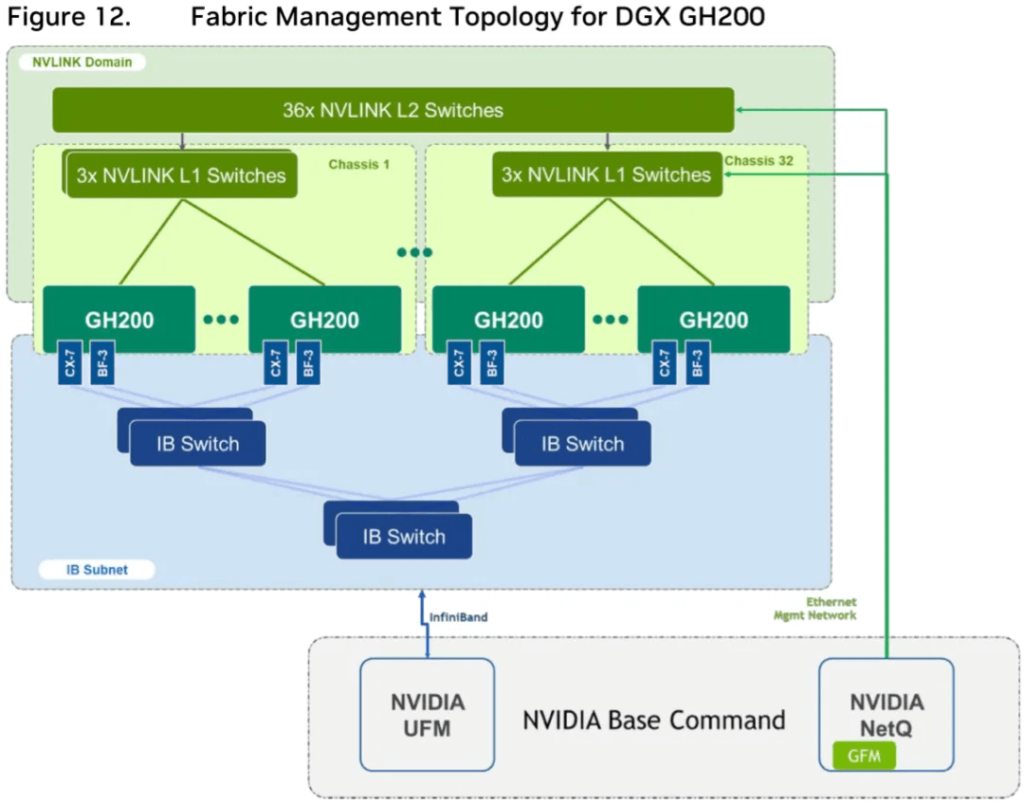
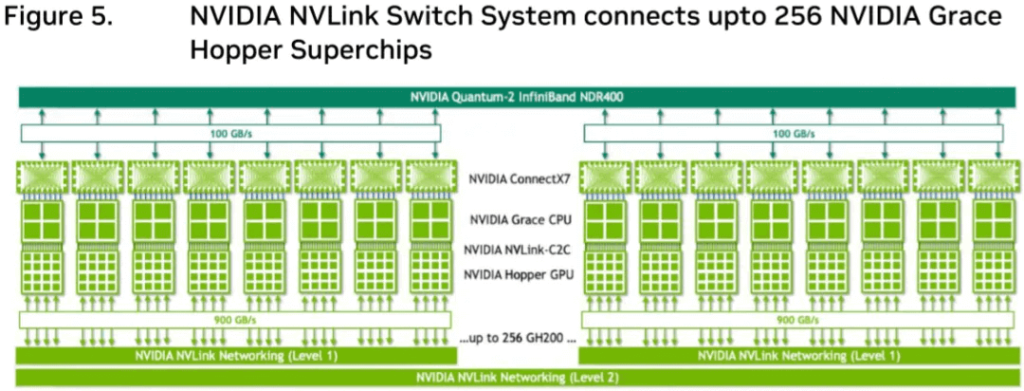
The complete connectivity of the GH200 SuperPod is shown in Figure 5.
GB200 NVL72 & GB200 SuperPod
GB200 Compute Tray
The GB200 Compute Tray is also based on the NVIDIA MGX design (1U size), with each Compute Tray containing 2 GB200 units, which is 2 Grace CPUs and 4 Blackwell GPUs, as shown in the image.

Each GB200 Compute Tray supports 1.7TB of Fast Memory (Note: the “HBM3e” in the image is likely a typo, it should be “Fast Memory”, not “HMB3e”). If it’s referring to the memory per Blackwell GPU, it should be 192GB x 4 = 768GB. The 1.7TB likely includes the additional 480GB of LPDDR5X per GB200, for a total of 768GB + 480GB x 2 = 1728GB.


NVSwitch Tray
As shown in the image, the new generation NVSwitch Tray also contains 2 NVSwitch chips (1U size), with a total of 144 NVLink Ports (72 NVLink Ports per NVSwitch chip). Each port has a bandwidth of 100GB/s, supporting a total bandwidth limit of 14.4TB/s. The fourth-generation NVSwitch System can support up to 576 GPUs, so the total bandwidth limit can reach 576 * 1.8TB/s = 1PB/s. (Note: the 8 ports in the image are not NVLink Ports, each corresponds to 18 NVLinks.)

The NVSwitch System used in the NVL72 is shown below, containing 9 NVSwitch Trays. The 72 ports in the image correspond to the ports in the previous image, not NVLink Ports, with a bandwidth of 1.8TB/s (18 x 100GB/s NVLinks).

GB200 NVL72
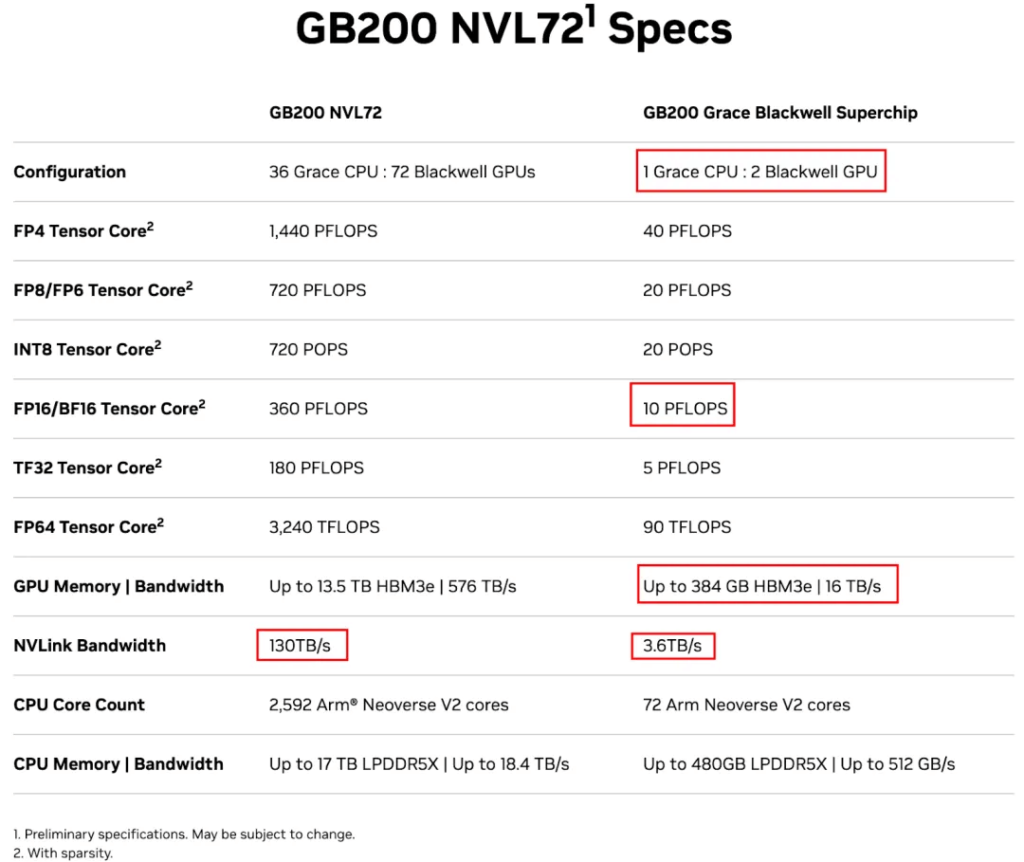
One GB200 NVL72 contains 18 GB200 Compute Trays, so it has 36 Grace CPUs and 72 GPUs. The total GPU memory is 72 * 192GB = 13.8TB, and the CPU’s Fast Memory LPDDR5X is 480GB x 36 = 17TB, so the total Fast Memory is 30TB. It also includes 9 NVSwitch Trays.
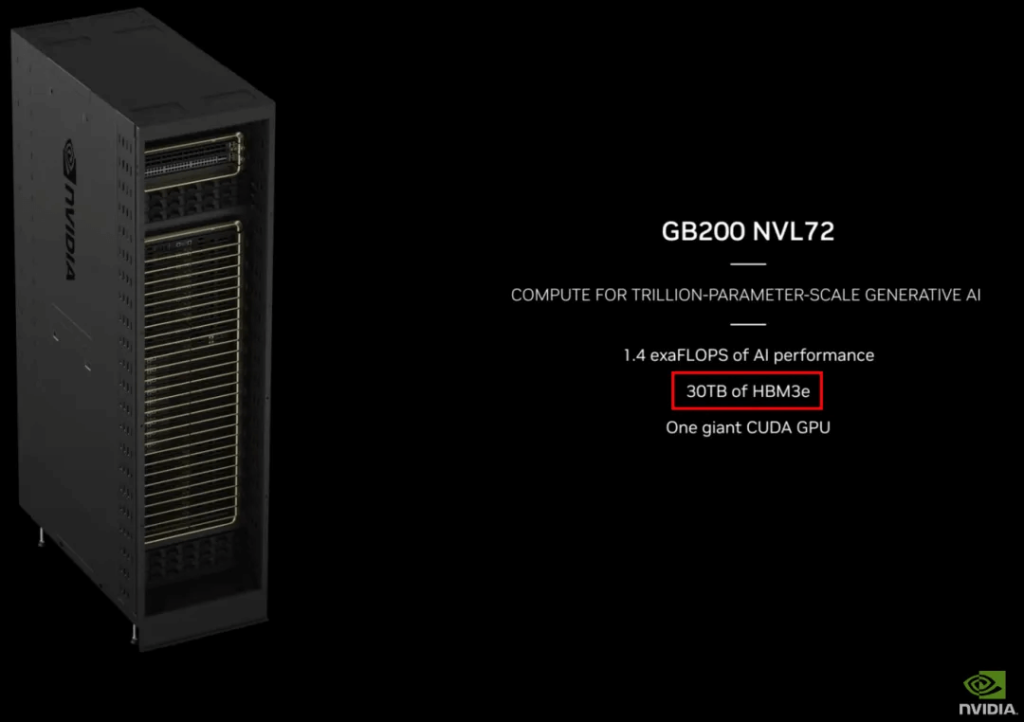
NVIDIA also offers a NVL36 configuration, which still has 18 GB200 Compute Trays, but each Compute Tray only has one GB200, so a total of 18 Grace CPUs and 36 B200 GPUs.The corresponding compute power is shown in the image. So the 30TB mentioned is likely 13.5TB HBM3e + 17TB LPDDR5X.

The corresponding computing power is shown in the figure below:
So the 30TB HBM3e here should also be 13.5TB HBM3e + 17TB LPDDR5X:
GB200 SuperPod
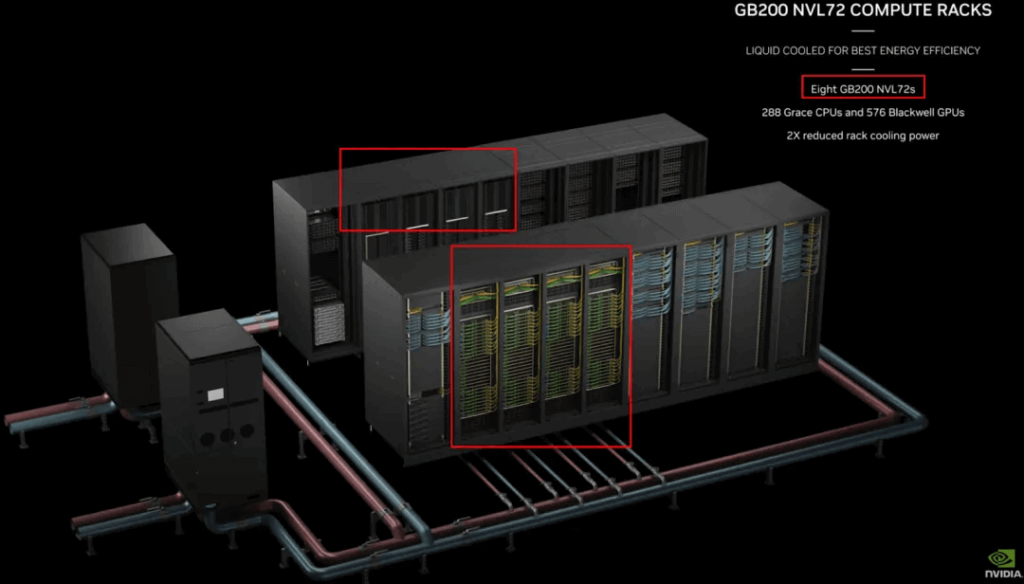
The GB200 SuperPod is composed of 8 NVL72 units, totaling 576 Blackwell GPUs. To achieve full interconnectivity, similar to the previous 256 GH200 GPUs, it requires a two-tier NVSwitch Tray system (theoretical bandwidth limit of 576 * 1.8TB/s = 1PB/s):
The first-tier NVSwitch Tray has half its ports connected to the 576 Blackwell GPUs, so 576 * 18 / (144/2) = 144 NVSwitch Trays are needed (the remaining 144 * 72 ports).
The second-tier NVSwitch Trays have all their ports connected to the remaining first-tier NVSwitch ports, so 144 * 72 / 144 = 72 NVSwitch Trays are needed. Each second-tier NVSwitch Tray is connected to all the first-tier NVSwitch Trays (2 ports per connection).
Performance Data Analysis
DGX GB200 Performance
NVIDIA claims that the DGX B200 (corresponding to the HGX B200) has a 3x improvement in training performance and a 15x improvement in inference performance compared to the previous generation DGX H100 (HGX H100). However, this is with certain preconditions. Looking solely at the FP16 or FP8 compute power from HGX H100 to HGX B200, the compute power has increased by 2.25x. But the memory size is larger, the memory bandwidth is around 2.3x higher, and the NVLink bandwidth has also doubled. So the overall 3x improvement in training speed is in line with expectations.
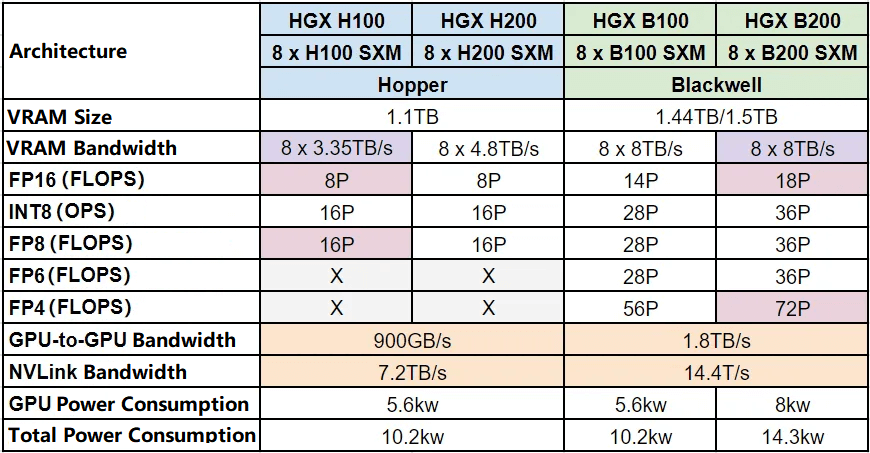
As shown in the image, the 3x training speed was measured on 4096 HGX B200 systems vs 4096 HGX H100 systems, training the GPT-MoE-1.8T model.
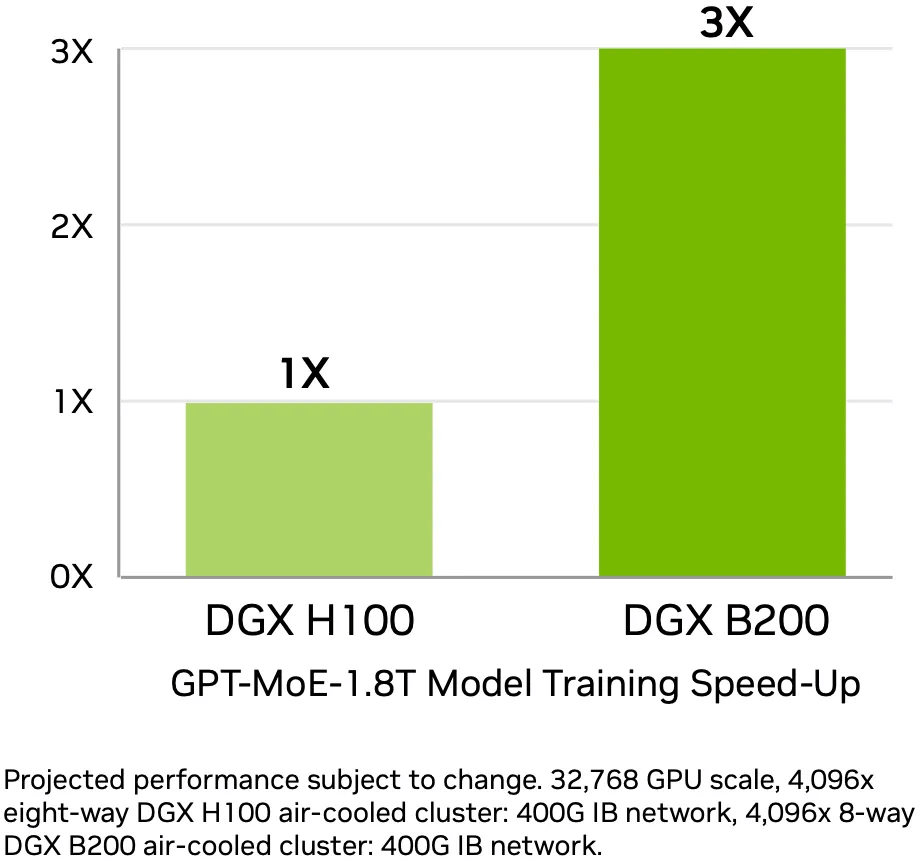
As shown in the image, the 15x inference speed was measured on 8 HGX B200 systems vs 8 HGX H100 systems, using the GPT-MoE-1.8T model for inference (GPT model inference is usually I/O bound, so memory bandwidth is crucial; to support higher concurrency, large memory size is also important; and since the model is large, strategies like Tensor Parallel are often used, so NVLink bandwidth is also crucial). They achieved 3.5 Tokens/s and 58 Tokens/s respectively.The factors affecting GPT inference are numerous, and for these two systems, the improvements are determined by:
- VRAM bandwidth (8×3.35TB/s -> 8x8TB/s)
- VRAM size (8x141GB -> 8x192GB)
- NVLink bandwidth (7.2TB/s -> 14.4TB/s)
- Compute power doubled (16P -> 36P)
- FP8 -> FP4 (x2)
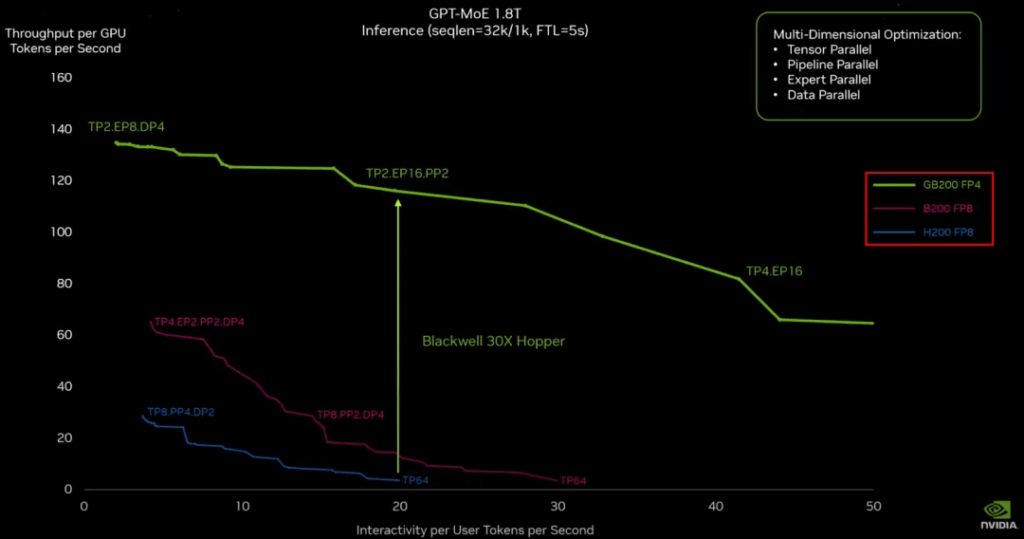
As shown in the last image, Jensen Huang provided a more detailed comparison in his GTC keynote, showing that the improvement is only around 3x when comparing B200 FP8 and H200 FP8 (with TP, EP, DP, PP representing Tensor Parallel, Expert Parallel, Data Parallel, and Pipeline Parallel). The improvement using GB200 in FP4 is very significant (likely due to the full NVLink interconnect in the NVL72).
GPT-MoE-1.8T Training Power Consumption
In his GTC keynote, Jensen Huang also discussed the power consumption for training the GPT-MoE-1.8T model, comparing Hopper and Blackwell GPUs:
- A single NVL32 cabinet is 40kW, so 8000 GPUs would be around 10MW, plus other power consumption, likely around 15MW.
- A single NVL72 cabinet is 120kW, so 2000 GPUs would be around 3.3MW, plus other power consumption like network switches, totaling around 4MW.


Related Products:
-
 OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
OSFP-800G-FR4 800G OSFP FR4 (200G per line) PAM4 CWDM Duplex LC 2km SMF Optical Transceiver Module
$3500.00
-
OSFP-800G-2FR2L 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Duplex LC SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-2FR2 800G OSFP 2FR2 (200G per line) PAM4 1291/1311nm 2km DOM Dual CS SMF Optical Transceiver Module
$3000.00
-
OSFP-800G-DR4 800G OSFP DR4 (200G per line) PAM4 1311nm MPO-12 500m SMF DDM Optical Transceiver Module
$3000.00
-
NVIDIA MMS4X00-NM-FLT Compatible 800G Twin-port OSFP 2x400G Flat Top PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$1199.00
-
NVIDIA MMA4Z00-NS-FLT Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS4X00-NM Compatible 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 SMF Optical Transceiver Module
$900.00
-
NVIDIA MMA4Z00-NS Compatible 800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF Optical Transceiver Module
$650.00
-
NVIDIA MMS1Z00-NS400 Compatible 400G NDR QSFP112 DR4 PAM4 1310nm 500m MPO-12 with FEC Optical Transceiver Module
$700.00
-
NVIDIA MMS4X00-NS400 Compatible 400G OSFP DR4 Flat Top PAM4 1310nm MTP/MPO-12 500m SMF FEC Optical Transceiver Module
$700.00
-
NVIDIA MMA1Z00-NS400 Compatible 400G QSFP112 VR4 PAM4 850nm 50m MTP/MPO-12 OM4 FEC Optical Transceiver Module
$550.00
-
NVIDIA MMA4Z00-NS400 Compatible 400G OSFP SR4 Flat Top PAM4 850nm 30m on OM3/50m on OM4 MTP/MPO-12 Multimode FEC Optical Transceiver Module
$550.00
-
NVIDIA MMS4X50-NM Compatible OSFP 2x400G FR4 PAM4 1310nm 2km DOM Dual Duplex LC SMF Optical Transceiver Module
$1200.00
-
OSFP-XD-1.6T-4FR2 1.6T OSFP-XD 4xFR2 PAM4 1291/1311nm 2km SN SMF Optical Transceiver Module
$15000.00
-
OSFP-XD-1.6T-2FR4 1.6T OSFP-XD 2xFR4 PAM4 2x CWDM4 2km Dual Duplex LC SMF Optical Transceiver Module
$20000.00
-
OSFP-XD-1.6T-DR8 1.6T OSFP-XD DR8 PAM4 1311nm 2km MPO-16 SMF Optical Transceiver Module
$12000.00















